الگوریتم تطابق رشته با زمان خطی
الگوریتم تطابق رشته با زمان خطی توسط دانلد کنوت و وان پرت و همچنین جیمز ه. موریس به صورت مستقل پرداخته شد، اما این سه فرد با هم آن را منتشر کردند. به همین خاطر به الگوریتم KMP نیز مشهور است. این الگوریتم در میان رشته S وجود کلمه W را بررسی میکند، بهطوریکه وقتی یک عدم مطابقت اتفاق میافتد، خود کلمه اطلاعات کافی را در بردارد تا محلی را که مطابقت بعدی ممکن است از آنجا شروع شود، با آزمایش دوبارۀ حروف تطبیق داده شده قبلی تعیین کند.
توجه: در این مقاله رشتهها با استفاده از آرایههای مبتنی بر صفر نمایش داده میشوند؛ به گونهای که حرف 'C' در به صورت نشان داده میشود.


الگوریتم KMP
یک مثال از الگوریتم جستجو
برای نشان دادن جزئیات این الگوریتم، یک اجرا (تقریباً ساختگی) از آن را بررسی میکنیم. در هر زمان دلخواهی، الگوریتم در یک حالت مشخصشده با دو عدد صحیح m و i قرار دارد. بهطوریکه هرکدام به ترتیب موقعیتی در S را مشخص میکنند که شروع یک تطابق ممکن برای W و اندیسی از W است که نشان میدهد کدام کاراکتر در حال حاضر تحت بررسی است. در ابتدای اجرا الگوریتم به این شکل است:
1 2
m: 01234567890123456789012
S: ABC ABCDAB ABCDABCDABDE
W: ABCDABD
i: 0123456
با مقایسۀ پیدرپی کاراکترهای W با کاراکترهای "متناظر" از S ادامه میدهیم و اگر کاراکترها یکسان بودند به کاراکتر بعدی آن میرویم. در مرحلۀ چهارم یک فاصله و کاراکتر 'D' است که این یک عدم تطابق است. به جای اینکه دوباره جستجو را از شروع کنیم، در نظر میگیریم که 'A' بین موقعیتهای 0 و 3 فقط در اندیس 0 از S دیده شدهاست؛ از این رو با دانستن این مطلب و اینکه آن کاراکترها قبلاً بررسی شدهاند، میدانیم که اگر دوباره آنها بررسی کنیم، هیچ موقع یک تطابق دیگر را پیدا نخواهیم کرد. پس به کاراکتر بعدی میرویم و m را برابر 4 و i را برابر 0 در نظر میگیریم. (از آنجایی که m + i – T[i] = 0 + 3 – 0 = 3 و T[0] = -1 پس m برابر 4 خواهد بود.)



1 2
m: 01234567890123456789012
S: ABC ABCDAB ABCDABCDABDE
W: ABCDABD
i: 0123456
در اینجا تقریباً به یک تطابق دست پیدا میکنیم، اما در اختلاف مشاهده میشود. با این حال در انتهای تطابق از "AB" گذر کردیم که میتواند شروع یک تطابق جدید باشد، پس باید این را در نظر بگیریم. همانطور که از قبل میدانیم، این کاراکترها با دو کاراکتر قبل از موقعیت فعلی تطابق داشتند، پس نیاز نیست که دوباره بررسی شوند؛ به راحتی m = 8 و i = 2 قرار داده و تطابق کاراکتر فعلی را ادامه میدهیم. پس به این شکل هم کاراکترهای تطابق دادهشدۀ قبلی از S و هم از W را حذف میکنیم.


1 2
m: 01234567890123456789012
S: ABC ABCDAB ABCDABCDABDE
W: ABCDABD
i: 0123456
جستجو بلافاصله متوقف میشود، هرچند از آنجایی که رشته دارای فاصله نیست، مانند قبل به اول W بازمیگردیم و جستجو را از کاراکتر بعدی S آغاز میکنیم: m = 11 و i = 0.
1 2
m: 01234567890123456789012
S: ABC ABCDAB ABCDABCDABDE
W: ABCDABD
i: 0123456
دوباره به یک تطابق برای "ABCDAB" دست پیدا کردیم، اما کاراکتر بعدی ('C') با کاراکتر آخر W یعنی 'D' مطابقت ندارد. مانند قبل m را برابر 15 و i را برابر 2 در نظر میگیریم و تطابق را از موقعیت فعلی ادامه میدهیم.
1 2
m: 01234567890123456789012
S: ABC ABCDAB ABCDABCDABDE
W: ABCDABD
i: 0123456
در این مرحله موفق به یافتن تطابقی که شروعش از کاراکتر است میشویم.

توضیحات و شبهبرنامه برای الگوریتم جستجو
مثال بالا همۀ اجزای الگوریتم را در بر دارد. فرض میکنیم یک جدول "تطابق جزئی" T (که در پایین توضیح داده شده) داریم که مشخص میکند از کجا باید به دنبال یافتن شروع یک تطابق جدید باشیم. درایههای جدول T نشان میدهند که اگر تطابقی از شروع شود و هنگام مقایسۀ با شکست بخورد، مطابقت بعدی ممکن است از اندیس رشتۀ S آغاز شود. (که مقدار "برگشتن"ای است که ما نیاز داریم بعد از یک عدم مطابقت انجام دهیم.) اینجا دو مفهوم داریم: اول، که نشان میدهد اگر در عدم مطابقت داریم، نمیتوانیم برگردیم و باید کاراکتر بعدی را بررسی نماییم. دوم، با وجود اینکه مطابقت احتمالی از اندیس آغاز میشود، مانند مثال بالا، نیاز نیست که هیچکدام از کاراکتر بعد از آن را بررسی کنیم، پس جستجو را از ادامه میدهیم. شبهبرنامهی سادۀ زیر الگوریتم جستجوی KMP را نشان میدهد:








algorithm kmp_search:
input:
an array of characters, S (the text to be searched)
an array of characters, W (the word sought)
output:
an integer (the zero-based position in S at which W is found)
define variables:
an integer, m ← 0 (the beginning of the current match in S)
an integer, i ← 0 (the position of the current character in W)
an array of integers, T (the table, computed elsewhere)
while m+i is less than the length of S, do:
if W[i] = S[m + i],
if i equals the (length of W)-1,
return m
let i ← i + 1
otherwise,
let m ← m + i - T[i],
if T[i] is greater than -1,
let i ← T[i]
else
let i ← 0
(if we reach here, we have searched all of S unsuccessfully)
return the length of S
کارایی الگوریتم جستجو
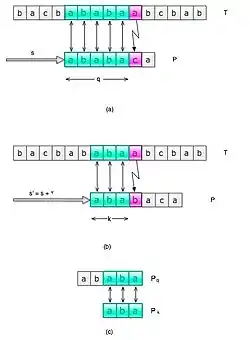
با فرض داشتن جدول T، الگوریتم KMP دارای پیجیدگی است که k طول رشتۀ S و O نماد O بزرگ میباشد. به جز مخارج کلی وارد شده هنگام وارد شدن به تابع و خارج شدن از آن، همۀ محاسبات در حلقۀ while انجام میگیرد که در اینجا کرانی از تعداد تکرارهای این حلقه را محاسبه خواهیم کرد. برای انجام این کار باید اول یک مشاهدۀ کلیدی روی ماهیت T داشته باشیم. این جدول برای این ساخته شده که نشان دهد اگر تطابقی از شروع شود و هنگام مقایسۀ با شکست بخورد، مطابقت بعدی ممکن است از آغاز شود. بهطور خاص، تطابق احتمالی بعدی باید در اندیسی بالاتر از m رخ دهد، پس .



با استفاده از این واقعیت، نشان میدهیم که حلقه میتواند حداکثر 2k بار اجرا شود. در هر بار تکرار، یکی از دو شاخۀ داخل حلقه اجرا خواهد شد. شاخۀ اول i را مداوم افزایش داده و مقدار m را تغییر نمیدهد تا اندیس m + i کاراکتر دقیق فعلی از S افزایش یابد. شاخۀ دوم را به m اضافه میکند و همانطور که دیده میشود، این همواره یک عدد مثبت میباشد. در نتیجه محل m از شروع تطابق احتمالی فعلی افزایش مییابد. حال اگر m + i = k باشد، حلقه تمام میشود، پس هر شاخه از حلقه میتواند حداکثر k بار اجرا شود. از آنجایی که هر شاخه به ترتیب m یا m + i را افزایش میدهند و m ≤ m + i، اگر m = k باشد، پس قطعاً m + i ≥ k. در نتیجه چون حداکثر افزایش را دارد، باید قبلاً شرط m + i = k برقرار شده باشد، پس هر کدام از راهها میتواند انجام شده باشد.

در نتیجه حلقه حداکثر 2k بار اجرا میشود که نشان میدهد پیچیدگی زمانی الگوریتم است.
جدول "تطابق جزئی" ("عمل شکست")
هدف از ساختن این جدول آن است که الگوریتم هیچ کاراکتری از S را بیش از یک بار مطابقت ندهد. یک مشاهدۀ کلیدی دربارۀ ماهیت یک جستجوی خطی که اجازه میدهد این کار انجام شود، آن است که با بررسی کردن قطعهای از رشتۀ اصلی در مقابل یک قطعۀ ابتدایی از طرح اصلی، خواهیم دانست که دقیقاً از چه اندیسهایی یک مطابقت احتمالی جدید شروع خواهد شد. در واقع یک جستجو از قبل روی طرح انجام خواهیم داد و یک لیست از همۀ موقعیتهای احتمالی ارائه میکنیم. بهطوریکه از حداکثر تعداد کاراکتر گذر کند، در حالی که هیچ تطابق احتمالی را از دست ندهد.
میخواهیم بتوانیم برای هر موقعیت در W، طول بلندترین قطعۀ ابتدایی ممکن از W را پیدا کنیم که از آن موقعیت آغاز شده اما آن را شامل نمیشود، به جای اینکه قطعۀ کاملی را در نظر بگیریم که از آغاز شده و عدم مطابقت داشتهاست. از این رو دقیقاً طول بلندترین قطعۀ ابتدایی ممکن و مناسب از W است که همچنین یک قطعه از زیررشتهای است که پایانش در میباشد. قرارداد میکنیم که رشتۀ خالی طول 0 را دارد. از آنجایی که یک عدم تطابق از ابتدای طرح یک حالت خاص است (هیچ امکانی برای بازگشت نیست)، در نظر میگیریم، همانطور که در بالا توضیح داده شد.

یک مثال از الگوریتم ساختن جدول
ابتدا مثال "W = "ABCDABD را بررسی میکنیم. خواهیم دید که همان روال الگوریتم جستجوی اصلی را پیش میگیرد و به همان دلایل کارا است. در نظر میگیریم: . برای یافتن ، باید یک پسوند مناسب از "A" کشف کنیم که یک پیشوند از W هم هست. اما هیچ پسوند مناسبی از "A" نداریم پس و به همین شکل .



با ادامه میدهیم. توجه میکنیم که یک میانبر برای بررسی کردن همهی پسوندها وجود دارد: فرض میکنیم یک پسوند مناسب یافتهایم که پیشوند مناسب نیز هست و در با طول 2 تمام میشود (تا حداکثر ممکن)؛ سپس اولین کاراکتر یک پیشوند مناسب از پیشوند مناسب W است، از این رو خودش یک پیشوند مناسب است و در تمام میشود که قبلاً تعیین شده که نمیتواند در حالت اتفاق بیفتد. از این رو در هر مرحله، راه میانبر آن است که تنها در صورتی نیاز به بررسی پسوند به اندازۀ دادهشدۀ m + 1 داریم که یک پسوند معتبر از اندازۀ m در مرحلۀ قبل یافت شده باشد. (بهطور مثال )





در نتیجه نیاز نیست درگیر یافتن زیررشتههایی به طول 2 شویم و مانند حالت قبل تنها یکی با طول 1 شکست میخورد، پس: .

به یعنی 'A' میرویم. همان منطق نشان میدهد که بلندترین زیررشتهای که ما نیاز به بررسی آن داریم دارای طول 1 است، و با اینکه در این حالت 'A' کار میکند، به خاطر بیاورید که ما به دنبال قطعههایی هستیم که قبل از کاراکتر فعلی تمام میشوند. از این رو .


حال کاراکتر بعدی یعنی را که همان 'B' است بررسی میکنیم. منطق زیر را پیش میگیریم:
اگر یک زیررشته را که از قبل از کاراکتر آغاز میشود و تا ادامه دارد بخواهیم پیدا کنیم، آنگاه بهطور خاص خودش یک قطعۀ ابتدایی مناسب خواهد داشت که در تمام و قبل از آن شروع میشود، که با این واقعیت در تضاد است که ما قبلاً فهمیدهایم 'A' خودش جلوترین وقوع از یک قطعۀ مناسب است که در تمام میشود. پس نباید قبل از را جستجو کنیم تا یک رشتۀ پایانی برای پیدا کنیم. در نتیجه .


در نهایت، خواهیم دید که کاراکتر بعدی در قطعۀ موردنظر که از آغاز میشود، 'B' خواهد بود، که در واقع همان است. به علاوه همین استدلال مانند بالا نشان میدهد که نیازی نیست قبل از را بررسی کنیم تا یک قطعه برای پیدا کنیم، پس .


پس به این ترتیب جدول زیر را پر میکنیم:
i |
0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
W[i] |
A | B | C | D | A | B | D |
T[i] |
-1 | 0 | 0 | 0 | 0 | 1 | 2 |
بقیۀ مثالها جذابتر و پیچیدهتر هستند:
i |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
W[i] |
P | A | R | T | I | C | I | P | A | T | E | I | N | P | A | R | A | C | H | U | T | E | ||
T[i] |
-1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 3 | 0 | 0 | 0 | 0 | 0 |
توضیحات و شبهبرنامه برای الگوریتم ساختن جدول
مثال بالا تکنیکهای کلی برای ساختن جدول با کمترین تلاش را نشان میدهد. قاعدۀ کلی برای جستجوی سراسری آن است که: بیشتر کارها قبلاً در هنگام یافتن موقعیت فعلی انجام شدهاست، پس اعمال کمی باید هنگام خروج از آن انجام شود. تنها پیچیدگی جزئی آن است که در ابتدای کار این منطق به اشتباه، زیررشتههای نامناسبی از رشته میدهد. این مشکل ضرورت یک مقداردهی اولیه را نشان میدهد.
algorithm kmp_table:
input:
an array of characters, W (the word to be analyzed)
an array of integers, T (the table to be filled)
output:
nothing (but during operation, it populates the table)
define variables:
an integer, pos ← 2 (the current position we are computing in T)
an integer, cnd ← 0 (the zero-based index in W of the next
character of the current candidate substring)
(the first few values are fixed but different from what the algorithm
might suggest) let T[0] ← -1, T[1] ← 0
while pos is less than the length of W, do:
(first case: the substring continues)
if W[pos - 1] = W[cnd],
let cnd ← cnd + 1, T[pos] ← cnd, pos ← pos + 1
(second case: it doesn't, but we can fall back)
otherwise, if cnd> 0, let cnd ← T[cnd]
(third case: we have run out of candidates. Note cnd = 0)
otherwise, let T[pos] ← 0, pos ← pos + 1
کارایی الگوریتم ساختن جدول
پیچیدگی الگوریتم جدول از است که n طول رشتۀ W میباشد. به جز مقداردهی اولیۀ انجامشده، همۀ کارها در یک حلقۀ while انجام شدهاست. کافیست نشان دهیم این حلقه در زمان اجرا میشود که با بررسی مقادیر pos و pos - cnd بهطور همزمان قابل اثبات است. در اولین شاخه، هم pos و هم cnd بهطور همزمان در حال افزایشند، پس pos - cnd محفوظ است. اما بهطور طبیعی pos در حال افزایش است. در شاخۀ دوم، cnd با جایگزین میشود. در شاخۀ سوم، pos در حال افزایش و cnd بدون تغییر است، پس pos و pos - cnd هر دو افزایش مییابند. از آنجایی که pos ≤ pos - cnd، در هر مرحله یا pos یا یک کران پایین از pos افزایش مییابد؛ در نتیجه چون الگوریتم زمانی که pos = n باشد، به پایان میرسد، باید حداکثر بعد از 2n بار تکرار حلقه کار تمام شود. (چون pos - cnd از 1 آغاز میشوند.) پس پیچیدگی الگوریتم جدول از میباشد.


کارایی الگوریتم KMP
از آنجایی که دو قسمت الگوریتم به ترتیب دارای پیچیدگی و هستند، در کل پیچیدگی الگوریتم از میباشد.

بدون توجه به تعداد تکرار یک طرح در W یا S، این پیچیدگیها همواره یکسان هستند.
منابع برای مطالعۀ بیشتر
- الگوریتم جستجوی رشتۀ Boyer-Moore
- الگوریتم جستجوی رشتۀ رابین-کارپ
منابع
- Donald Knuth (1977). "Fast pattern matching in strings". SIAM Journal on Computing. 6 (2): 323–350. doi:10.1137/0206024. Unknown parameter
|coauthors=ignored (|author=suggested) (help) - توماس اچ کورمن (2001). "Section 32.4: The Knuth-Morris-Pratt algorithm". مقدمهای بر الگوریتمها (Second ed.). MIT Press and McGraw-Hill. pp. 923–931. ISBN 978-0-262-03293-3. Unknown parameter
|coauthors=ignored (|author=suggested) (help)
پیوند به بیرون
- String Searching Applet animation
- An explanation of the algorithm and sample C++ code by David Eppstein
- Knuth-Morris-Pratt algorithm description and C code by Christian Charras and Thierry Lecroq
- Explanation of the algorithm from scratch by FH Flensburg.
- Breaking down steps of running KMP by Chu-Cheng Hsieh.
- ویدیو در یوتیوبNPTELHRD YouTube lecture video