تجزیه از پایین به بالا
در علوم کامپیوتر، تجزیه به عملی اطلاق میشود که قواعد ساختاری یک متن را آشکار میسازد. این گام مقدمه معنی کردن آن متن است. تجزیه پایین به بالا به یک نوع تجزیه کردن متن ورودی بر اساس ساختار گرامری از پیش تعیین شدهای گفته میشود که طی آن از پایینترین بخش درخت تجزیه یعنی برگهای آن شروع میکنیم و با اعمال قواعد ساخت روی جمله آنقدر ادامه میدهیم تا به ریشه درخت برسیم.
تجزیه پایین به بالا
درخت اشتقاق یک ابزار انتزاعی برای بیان ساختار یک گرامر مستقل از متن است. ریشه این درخت متغیر شروع گرامر و برگهای آن ثوابت این گرامر هستند. از کنار هم قرار دادن برگهای این درخت یک جمله که در زبان معادل آن گرامر وجود دارد بدست میآید. در تجزیه پایین به بالا برخلاف تجزیه بالا به پایین که در ابتدا بدون هیچ دانشی صرفاً با حدس زدن براساس اولین نشانه عمل تجزیه آغاز میشود، با نگاه کردن به برگهای درخت در واقع نسبت به اعمال اشتقاق میتوان شهود گرفت[1]. در واقع تجزیه پایین به بالا با خواندن از سمت چپ و آمدن به سمت راست معادل اشتقاق از راستترین متغیر است که یکی از روشهای اشتقاق در یک گرامر است. در تجزیه پایین به بالا با نگاه کردن به برگهای درخت اشتقاق و مقایسه کردن با قواعد ساخت درمییابیم در هر مرحله طبق کدام قاعده بایستی عمل اشتقاق صورت میگرفته تا حاصل چنین برگی باشد.
شیفت و کاهش دادن
تجزیه پایین به بالا از طریق شیفت و کاهش دادن صورت میگیرد. به این معنی که تمام ورودی ابتدا خارج از دسترس است سپس به تدریج با عمل شیفت یک نشانه در اختیار تجزیهکننده قرار میگیرد. تجزیهکننده تعیین میکند آیا قاعده اشتقاقی برای این نشانه وجود دارد یا نه. اگر قاعدهای وجود نداشت دوباره عمل شیفت دادن صورت میگیرد. انی عمل آنقدر تکرار میشود تا جمع نشانههای در دسترس از طریق قاعدهای در گرامر قابل ساخته شدن باشد. در آنصورت عمل کاهش دادن صورت میگیرد. به مجموعه نشانههایی که باعث صورت گرفتن یک کاهش میشوند هندل(handle) گفته میشود.
تجزیه LR
در این روش تجزیه برای تجزیه صحیح و استفاده نکردن از قواعد ساخت اشتباه در هر راس درخت از تجزیه LR استفاده میکنیم. [2] تجزیه LR به این معنی است که از سمت چپ جمله ورودی شروع میکنیم و به سمت راست میرویم و پس از پیدا شدن هندل عمل کاهش را انجام میدهیم. نام LR هم واقف بر همین دو موضوع است (L برای Left to right و R برای Reduce). این روش ابتدایی با نام (LR(0 شناخته میشود که روش ناقصی است. سه نوع تجزیهگر صحیحتر که از این روش مشتق میشوند به ترتیب قدرتشان عبارتند از: (LR(1)، LALR(1 و (SLR(1.
(LR(0
_deterministic_automaton.gif)
پیشتر اشاره شد که به تدریج نشانهها در اختیار ما برای بررسی قرار میگیرند. برای نشان دادن اینکه تا کجا جلو رفتهایم در این روش از نقطه(.) استفاده میشود. به این ترتیب حالات متفاوتی برای قرار داشتن نقطه وجود دارد. میتوان با یک ماشین حالت متناهی حالات مختلف و نحوه رسیدن به هر حالت را مدل کرد. در تصویر متحرک روبرو نحوه ساخته شدن این ماشین حالت متناهی را برای گرامر داده شده مشاهده میکنید.
پس از ساختن این ماشین حالت متناهی میتوان یک رشته گرفت و با شروع از سمت چپ به تدریج هندلها را به کمک ماشین ساخته شده پیدا کرد و عمل کاهش را انجام داد. نکته حائز اهمیت در این مرحله ساختن یک جدول است. این جدول به تعداد استیتهای ماشین حالت متناهی ردیف و به تعداد نشانهها ستون دارد. هر استیت ماشین باید بیانگر یک حرکت باشد:
- شیفت
- کاهش
(عمل قبول کردن رشته به این معنی که درخت اشتقاق آن به دست آمدهاست هم ذیل کاهش در نظر گرفته میشود) استیتهای شیفت استیتهایی هستند که نقطه به پایان عبارت نرسیدهباشد و استیتهای کاهش استیتهایی هستند که نقطه به پایان عبارت تک تک عبارات داخل آن استیت رسیدهباشد. اینجاست که ضعف (LR(0 مشخص میشود. همانگونه که در شکل روبرو دیده میشود بهطور مثال وضعیت استیتهای ۰، ۲ و ۴ متناقض است. در این استیتها هم عباراتی وجود دارند که آماده کاهش هستند و هم عباراتی هستند که باید برای رسیدن به هندل مناسب برای آنها عمل شیفت را انجام داد. به این تناقض، تناقض شیفت-کاهش میگوییم. نوع دیگری از تناقض وجود دارد که نام تناقض کاهش-کاهش است. به این ترتیب ۳ روش دیگر برای تجزیه معرفی شدند که براساس دیدن نشانه بعد از نقطه هستند:[3]
- (LR(1
- (SLR(1
- (LALR(1
(LR(1
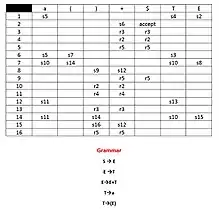
این روش دقیقا مشابه روش قبل است ولی در حین تجزیه علاوه بر نکاتی که تا الان به آنها توجه میکردیم، نشانه بعد از نقطه را هم مدنظر قرار میدهیم و به این ترتیب از به وجود آمدن تناقضهای گفته شده جلوگیری میکنیم. در این مرحله هم میتوان ماشین حالت متناهی ساخت و مشابه قبل هر استیت شامل چند عبارت گرامری است که هر عبارت یک نشانه جلوی خود میبیند. به این نشانه اصطلاحا Lookahead Token گفته میشود و بیانگر این است که نشانه بعد از حرف غیرپایانهای در جمله چه چیزی است. طبیعتا ساخت این ماشین حالت متناهی بخاطر در برگرفتن حالات بیشتر دشوارتر است.
در شکل روبرو یک نمونه از جدول اشتقاقی که طی این روش ساخته میشود را مشاهده میکنید. در خانههای این جدول مشخص شده با توجه به استیت ماشین حالت متناهی و نشانه پیشرو چه عملی انتخاب شود. عبارت [عدد]s در یک خانه به معنی شیفت دادن و رفتن به استیت [عدد] است و [عدد]r به معنی کاهش دادن طبق قاعده شماره [عدد] است.
(SLR(1
این روش خود نمونهای از روش قبلی است ولی برای جلوگیری از پیچیدگی ماشین حالت متناهی روش قبل و سادهسازی معرفی شدهاست. این روش با توجه به اینکه ساده شده روش (LR(1 است به قدرتمندی این روش نیست و ضعفهایی دارد. در این روش مجموعهای از نشانهها که طبق قواعد گرامر میتوانند پس از هر حرف غیرپایانهای بیایند برای هرکدام از این حرفها در نظر گرفته میشود. حال بهجای در نظر گرفتن تمام حالات نشانه پیشرو، تنها بررسی میکنیم نشانه پیشرو حرف غیرپایانهای یک قاعده در مجموعه گفتهشده حضور دارد یا خیر. به مجموعه گفتهشده مجموعه دنبالکنندهها یا Follow set گفته میشود. همانطور که گفته شد در این روش به دلیل اعمال محدودیت برای جلوگیری از گستردگی ماشین حالت متناهی ضعفهایی وجود دارد. بهطور مثال در این روش ممکن است با تناقض شیفت-کاهش روبرو شویم.
(LALR(1
این روش هم برگرفته از روش (LR(1 است ولی برای جلوگیری از گسترده شدن ماشین حالت متناهی در حین ساختن استیتها بررسی صورت میگیرد که حتیالامکان استیت جدید اضافه نشود. این به دو صورت ظاهر میشود:
- در یک استیت اگر محبور باشیم یک قاعده را بخاطر تفاوت در نشانه پیشرو چندبار بنویسیم، آن قاعده را یکبار مینویسیم و روبرویش تمام نشانههای پیشرو را میگذاریم.
- هر گاه از یک استیت با یک تبدیل حرفی بخواهیم به استیتی برویم دقیقا مشابه آن استیت وجود ندارد در بین استیتها میگردیم که آیا استیتی وجود دارد که همان قاعده را با نشانه پیشرو دیگری داشته باشد یا نه. اگر چنین استیت وجود داشت تبدیل را به همان استیت صورت میدهیم و به نشانههای پیشروی آن نشانه جدید را اضافه میکنیم.
منابع
- Compilers: Principles, Techniques, and Tools (2nd Edition), by Alfred Aho, Monica Lam, Ravi Sethi, and Jeffrey Ullman, Prentice Hall 2006.
- Parsing Techniques; A Practical Guide(2nd Edition), by Dick Grune and Ceriel J.H. Jacobs, Springer 2008.
- «نسخه آرشیو شده». بایگانیشده از اصلی در ۹ آوریل ۲۰۱۸. دریافتشده در ۳۱ دسامبر ۲۰۱۷.