الگوریتم مونت کارلو
در علوم کامپیوتر، الگوریتم مونت کارلو یک الگوریتم تصادفی است که دارای زمان اجرایی قطعی است اما خروجی آن میتواند با یک احتمال مشخص (معمولاً کوچک) نادرست باشد.
رده مشابهی از الگوریتم به نام الگوریتم لاس وگاس نیز وجود دارد، که از نوع تصادفی است، اما به گونهای متفاوت: در آن الگوریتم به میزانی زمان نگه میدارند که این میزان به صورت تصادفی تغییر میکند، اما الگوریتم همواره پاسخی درست را ایجاد میکند. زمانی که یک رویه برای ارزیابی خروجی الگوریتم داشته باشیم، میتوانیم یک الگوریتم مونت کارلو را به یک الگوریتم لاس وگاس تبدیل نماییم. اگر چنین باشد، الگوریتم لاس وگاس حاصل تنها یک الگوریتم مونت کارلو است که به صورت مکرر اجرا میشود تا نتیجه یکی از اجراها خروجی را حاصل کند، که بتوان آن را به یک جواب درست تعبیر نمود.
نام این الگوریتم از نام یک کازینو بزرگ به نام کازینو مونت کارلو برگرفته شدهاست که در قلمرو موناکو قرار دارد و در تمامی کشورها به عنوان نماد قماربازی معروف است.
یک طرفه در برابر دو طرفه
با وجود این که پاسخ برگردانده شده توسط یک الگوریتم قطعی همواره درست به نظر میرسد، اما این حالت برای الگوریتم مونت کارلو برقرار نیست. برای مسئله تصمیم گیری، این الگوریتمها عمدتاً به عنوان مغرضانه-نادرست یا مغرضانه-درست محسوب میشوند. یک الگوریتم مغرضانه-نادرست مونت کارلو زمانی که پاسخ نادرست را بر میگرداند، همواره درست عمل میکند. و به همین صورت یک الگوریتم مغرضانه-درست، با تغییر آن چیزهایی که نیاز به تغییر دارند. در حالی که این الگوریتمهایی با خطای یک طرفه را ترسیم میکند، دیگر انواع این الگوریتم ممکن است حالت مغرضانه را نداشته باشند: که به آنها خطاهای دو طرفه میگویند. در واقع، پاسخی که نوع اخیر ایجاد میکنند با احتمال کران داری یا نادرست است یا درست.
به عنوان مثال، آزمون اعداد اول Solovay–Strassen برای تشخیص اعداد اول به کار میرود. این روش همواره پاسخ درست را برای ورودیهای عدد اول ایجاد میکند. برای ورودیهای مرکب، این آزمون با احتمال حداقل 1/2 پاسخ نادرست و با احتمال حداکثر 1/2 پاسخ درسترا برمی گرداند. بنابراین پاسخهای نادرست الگوریتم قطعی هستند، حال آن که وضعیت پاسخ هایدرست مشخص نیست. به این الگوریتم، الگوریتم مغرضانه-نادرست نیمه درست اطلاق میشود.
تقویت
در الگوریت مونت کارلو با خطاهای یک طرفه، با اجرای الگوریتم به تعداد k بار، احتمال شکست میتواند کاهش یابد (و به همین صورت احتمال موفقیت تقویت شود). الگوریتم Solovay–Strassen را که یک الگوریتم مغرضانه-نادرست نیمه درست است، دوباره در نظر بگیرید. میتوان این الگوریتم را که خروجی false میدهد، چندین بار اجرا کرد. اگر پس از k بار خروجی آن false باشد، جواب الگوریتم false و در غیر این صورت true است. بنابراین، اگر عددی اول باشد بنابراین پاسخ همواره درست است، و اگر عدد مرکب باشد، جواب با احتمال حداقل درست است.

برای الگوریتمهای مونت کارلو با خطای دو طرفه نیز احتمال شکست میتواند با اجرای مکرر الگوریتم و بازگرداندن تابع اکثریت پاسخها، کاهش یابد.
ردههای پیچیدگی
ردههای پیچیدگی چندجملهای احتمالی با خطای کران دار BPP به گونهای از مسئله تصمیم گیری گفته میشود که میتوانند توسط الگوریتمهای زمان چندجملهای مونت کارلو با احتمال کران داری از خطاهای دوطرفه حل شوند. رده پیچیدگی RP مسائلی را توصیف میکند که میتوانند با استفاده از الگوریتم مونت کارلو با احتمال کران داری از خطای یک طرفه حل شوند یعنی: اگر پاسخ درست خیر بود، الگوریتم همان کار را کند، اما میتواند برای برخی از مثالهایی که پاسخ درست بله است، نیز پاسخ نادرست بدهد. در مقابل، رده پیچدگی ZPP مسائلی را تببین میکند که با استفاده از الگوریتمهای با زمان مشخص لاس وگاس حل میشوند. بدیهی است که ZPP ⊂ RP ⊂ BPP، اما این هنوز مشخص نشده که کدام یک از این ردههای پیچیدگی از بقیه متمایزند به این معنی که، الگوریتمهای مونت کارلو توان محاسباتی بیشتری از الگوریتمهای لاس وگاس دارند، اما این امر هنوز ثابت نشدهاست. یکی دیگر از ردههای پیچیدگی، رده PP است که به مسائل تصمیم گیری اشاره میکند که دارای یک الگوریتم زمان چندجملهای مونت کارلو هستند که از مسئله پرتاب سکه دقیق تر هستند، اما احتمال خطا نمیتواند کرانی دور از 1/2 داشته باشد.
کاربردها در نظریه محاسباتی اعداد
الگوریتمهای مشهور مونت کارلو که شامل آزمون اعداد اول Solovay–Strassen، آزمون اعداد اول Miller–Rabin و نسخههای سریعی از الگوریتم Schreier–Sims که در نظریه محاسباتی گروه ها کاربرد دارند، جزء کاربردهای الگوریتم مونت کارلو هستند.
زمینههای کاربرد مونت کارلو
- گرافیک، بهطور خاص خط اثر پرتو
- مدل سازی جا به جایی نور در رشتههای بیولوژیک
- مونت کارلو در اقتصاد
- مهندسی اطمینان
- در شبیه سازی پیچش برای پیشبینی ساختار پروتئین
- در تخقیقات تجهیزات نیم رسانا، برای مدلسازی جا به جایی حاملهای کنونی
- در محیط زیست، بررسی آلاینده ها
- کاربرد مونت کارلو در فیزیک استاتیک
- در طراحی احتمالاتی برای شبیهسازی و درک تغییرپذیری
- در شیمی فیزیک، بهطور خاص برای شبیهسازی قالبهای اتمهای درگیر
- در علوم کامپیوتر:
o الگوریتم لاس وگاس o LURCH o Computer Go o بازیها
- کاربردهای گسترده در فیزیک هسته ای
الگوریتم مونت کارلو در یادگیری تقویتی
روش مونت کارلو به عنوان یکی از راه حلهای مسئله یادگیری تقویتی بر روی میانگینگیری از بازگشتهای نمونه برداری شده، استفاده شدهاست. این روش به صورت عمده جهت تخمین تابع ارزش و به دست آوردن سیاستهای بهینه به کار میرود. در این روش، بر خلاف روشهای برنامهریزی پویا در یادگیری تقویتی، عامل دانش کاملی از محیط ندارد. روشهای مونت کارلو در این زمینه تنها به تجربه، یعنی دنباله نمونههای حالتها، اعمال و پاداش متناظر با آنها که توسط تعامل با محیط به دست می آیند، نیاز داند. در روش یادگیری از اهمیت خاصی برخوردار است چرا که به هیچ گونه دانش قبلی از ویژگیهای دینامیکی محیط نیاز ندارد. به صورت عینی، تنها نیاز داریم تا انتقالهای نمونهای را ایجاد کنیم نه توزیع احتمالی کامل از تمامی انتقالها که در روشهای برنامهریزی پویا استفاده میشود.
با وجود تفاوتهای موجود میان روش مونت کارلو و برنامهریزی پویا، بسیاری از ایدههای مهم این روش از همان روش برنامهریزی پویا گرفته شدهاند. این ایدهها نه تنها در زمینه محاسبه تابع ارزش بلکه در نحوه تعامل برای رسیدن به بهینگی دارای تشابهات زیادی هستند. همچنین این روش با روش یادگیری تفاوت زمانی نیز مشابهتهای زیادی دارد. هر دو روش الگوریتم مونت کارلو و یادگیری تفاوت زمانی از تجربه برای حل مسئله پیشبینی استفاده میکنند. با داشتن چند تجربه که یک سیاست را در پیش دارند، هر دو روش تخمین خود از مقدار را به دست میآورند. یک روش مونت کارلو ساده شامل تمامی ملاقاتها که برای محیطهای ساکن مناسب است عبارت است از:




به دست آوردن سیاست در یادگیری تقویتی
در مسئله یادگیری تقویتی، به صورت خاص، ما می خواهیم مقدار تابع ارزش یک حالت خاص را تحت سیاست مورد نظر محاسبه کنیم که این کار با داشتن مجموعهای از قسمتها (episodes) انجام خواهد شد. الگوریتم مشاهده کلی مونت کارلو میزان متوسط بازگشتها را برای تمامی مشاهدهها در تمامی قسمتها محاسبه میکند. این عمل در الگوریتم مونت کارلو به صورت زیر انجام میشود که سودوکد آن نیز در زیر آمدهاست:



مقایسه با روشهای دیگر یادگیری تقویتی
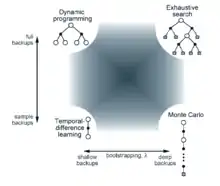
تمامی روشهای یادگیری تقویتی دارای ایدهای یکسان هستند. اول، هدف تمام آنها تخمین تابع ارزش است. دوم، تمامی آنها با نگهداری مقادیر در عبور از حالتهای مختلف ممکن یا واقعی عمل میکنند. سوم، تمامی آنها یک راهبرد برای پیمایش کلی سیاست (GPI) دارند، به این معنی که آنها یک تابع ارزش تقریبی و یک سیاست تقریبی را نگه میدارند و پیوسته هر کدام از آنها را بر مبنای دیگری بهبود میبخشند.
دو بعد مهم در روشهای یادگیری تقویتی در شکل روبرو مشاهده میشود. این ابعاد با نوع نگهداری که برای بهبود تابع ارزش استفاده شدهاست، مرتبط هستند. بعد عمودی نشان دهده این است که نگهداری آیا در نمونه هاست (بر اساس گذر از نمونه ها) یا نگهداری کامل است (بر اساس توزیع گذرهای ممکن). نگه داریهای کامل نیازمند یک مدل هستند حال آن که نگه داریهای نمونهای میتوانند بدون مدل نیز عمل کنند. بعد افقی به عمق این نگهداریها، یعنی درجه bootstrapping، مرتبط است. سه گوشه از چهار گوشه اشاره شده از روشهای مهم در تخمین ارزشها هستند: برنامهریزی پویا، یادگیری تفاوت زمانی و الگوریتم مونت کارلو.
جستارهای وابسته
منابع برای مطالعه بیشتر
- Motwani, Rajeev; Raghavan, Prabhakar (1995). Randomized Algorithms. نیویورک (ایالت): Cambridge University Press. ISBN 0521474655.
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001). "Ch 5. Probabilistic Analysis and Randomized Algorithms". مقدمهای بر الگوریتمها (2nd ed.). بوستون: MIT Press and McGraw-Hill. ISBN 0-262-53196-8.
- Berman, Kenneth A; Paul, Jerome L. (2005). "Ch 24. Probabilistic and Randomized Algorithms". Algorithms: Sequential, Parallel, and Distributed. بوستون: Course Technology. ISBN 0-534-42057-5.
- Richard Sutton and Andrew Barto (1998). Reinforcement Learning. MIT Press. ISBN 0585024456