یادگیری تفاوت زمانی
یادگیری تفاوت زمانی (به انگلیسی: Temporal difference learning) یک روش پیشبینی است. این روش به صورت عمده برای حل مسائل یادگیری تقویتی مورد استفاده بود است. "روش تفاوت زمانی ترکیبی از ایدههای مونت کارلو و برنامهریزی پویا است.[1] این روش مشابه روش مونت کارلو است چرا که یادگیری در آن با استفاده از نمونه برداری از محیط با توجه به یک یا چند سیاست خاص انجام میشود. روش تفاوت زمانی به این دلیل به تکنیکهای برنامهریزی پویا شباهت دارد که این روش تخمین کنونی را بر اساس تخمینهای یادگیری شده (فرایندی که به خودراه اندازه معروف است) به دست میآورد. الگوریتم یادگیری تفاوت زمانی به مدل یاگیری تفاوت زمانی در حیوانات نیز مرتبط است.
به عنوان یک روش پیشبینی، یادگیری تفاوت زمانی این واقعیت را در نظر میگیرد که پیشبینیهای آینده نیز معمولاً از جهاتی دارای همبستگی هستند. در روشهای یادگیری مبتنی بر پیشبینی نظارتی، مأمور تنها از مقادیر دقیقاً مشاهده شده یاد میگیرد: یک پیشبینی انجام میشود، و زمانی که مشاهده ممکن باشد، پیشبینی به تطابق بهتری با مشاهده خواهد رسید. مطابق منبع یاد شده، [2] ایده اساسی یادگیری تفاوت زمانی این است که پیشبینیها با پیشبینیهایی دقیق تر دیگری از آینده تنظیم کنیم. همان گونه که از مثال زیر بر میآید (برگرفته از منبع [2])، این رویه نوعی از فرایند خود راه اندازه است:
فرض کنید که می خواهید وضعیت هوای روز شنبه را پیشبینی کنید و مدلی دارید که هوای روز شنبه را با استفاده از وضعیت هوای داده شده برای تمام روزهای هفته، پیشبینی میکند. در شرایط عادی، باید تا شنبه صبر کنید تا بتوانید تمامی مدلهای خود را تنظیم نمایید. با این وجود، زمانی که مثلاً جمعه است، میتوانید ایده بسیار خوبی از این داشته باشید که هوای روز شنبه احتمالاً به چه صورتی خواهد بود و به همین صورت میتوانید مثلاً مدل روز دوشنبه خود را قبل از این که شنبه برسد، تغییر دهید.
به بیان ریاضی، هم در رویکرد استاندارد و هم در رویکرد تفاوت زمانی، تلاش ما بر این است که تابع هزینه را که مرتبط با خطاهای ما در پیشبینی یک یا چند متغیر تصادفی [E[z است، بهینهسازی نماییم. حال آن که در رویکرد استاندارد به گونهای فرض می نماییم که E[z]=z (که z همان متغیر مشاهده شدهاست) و در رویکرد TD از یک مدل استفاده می نماییم. برای حالت خاص در یادگیری تقویتی، که کاربرد عمده روشهای تفاوت زمانی است، z همان بازگشت کل و [E[z با استفاده از معادله بلمن بازگشت داده شدهاست.
ایده اصلی در رویکرد یادگیری تفاوتزمانی، یادگیری براساس تفاوت بین پیشبینیهای پیدرپی زمانی است و برای بروزرسانی نیازی به صبرکردن تا پایان مسیر نیست. به عبارت دیگر، هدف از یادگیری این است که پیشبینی کنونی یادگیرنده برای الگوی فعلی ورودی، بیشتر با پیشبینی بعدی در مرحله بعدی مطابقت داشته باشد.[3]
الگوریتم تفاوت زمانی در علوم عصبی
الگوریتم تفاوت زمانی در زمینه علوم عصبی نیز مورد توجه خاصی بودهاست. پژوهشگران دریافتهاند که نرخ ارسال الکتریکی نورونهای پخشکننده دوپامین در ناحيه تگمنتوم شكمي و جسم سیاه را میتوان به تابع خطای این الگوریتم نسبت داد [4]. تابع خطا، میزان تفاوت میان پاسخ (reward) تخمین زده شده در هر حالت (state) داده شده یا زمان خاصی و پاسخ دقیقی که به دست آمده را نشان میدهد. هر چه قدر این تابع بزرگ تر باشد، تفاوت میان پاسخ به دست آمده و مورد نظر بیشتر بودهاست. زمانی که این تابع با محرکی که پاسخ آینده را به صورت دقیق منعکس میکند، خطا میتواند برای نسبت دادن آن محرک به پاسخ آینده استفاده شود.
به نظر میرسد که سلولهای دوپامین نیز به صورت مشابهی عمل میکنند. در یکی از آزمایشهای انجام شده، اندازهگیریهایی از سلولهای دوپامین در یک میمون در حال آموزش انجام شد تا بتوان یک محرک را با پاسخ (جایزه) مربوط به آن که آب میوه بود، مرتبط کنند [5]. در ابتدا نرخ ارسال الکتریکی سلولهای دوپامین زمانی که میمون با آب میوه مواجه میشد، افزایش یافت که نشان میدهد که تفاوتی در پاسخهای مورد نظر و واقعی وجود دارد. در طول زمان، این ارسال به سمت اولین محرک مطمئن برای پاسخ بازگشت. به محض این که میمون به صورت کامل آموزش دید، هیچ افزایشی در در نرخ ارسال در هنگام مواجه با یک پاسخ مورد انتظار نبود. در ادامه، نرخ ارسال الکتریکی برای سلولهای دوپامین، زمانی که پاسخ مورد نظر دریافت نشد، به زیر سطح فعال شدن کاهش یافت. این یافتهها تا حد زیادی با تابع خطا در یادگیری تفاوت زمانی که در زمینه یادگیری تقویتی مطرح است، مرتبط شدهاست.
رابطه میان این مدل و کارکردهای بالقوه نورولوژیکی زمینه پژوهشی را به وجود آورده که هدف در استفاده از TD برای توضیح بسیاری از جنبههای پژوهشهای رفتاری را دارد [6]. این رابطه همچنین برای مطالعه شرایطی مانند اسکیزوفرنی و تبعات دستکاریهای دارویی سطح دوپامین در یادگیری، مورد استفاده قرار گرفتهاست [7].
فرمول بندی ریاضی
فرض کنید میزان تقویت در نقطه زمانی . همچنین فرض کنید پیش بینی صحیحی باشد که معادل حاصل جمع کاهش یافته تمامی مقادیر تقویت در آینده است. این کاهش توسط توانهایی از عامل به گونهای انجام میشود که در نقاط زمانی دورتر، مقدار تقویت اهمیت کمتری دارد:





که در آن .

این فرمول میتواند توسط تغییر نقطه شروع اندیس i به مقدار صفر گسترش یابد:




بنابراین، مقدار تقویت تفاوت میان پیشبینی ایدهآل و پیشبینی فعلی است:

الگوریتم TD-Lambda یک الگوریتم یادگیری است که توسط Richard S. Sutton بر مبانی کارهای قبلی انجام شده توسط Arthur Samuel در یادگیری تفاوت زمانی ایجاد شدهاست[1]. کاربرد معروفی از این الگوریتم توسط Gerald Tesauro برای ایجاد برنامه TD-Gammon بودهاست. در واقع، این برنامه یاد میگیرد که تخته نرد را در سطح بازیکنان برجسته انسانی بازی کند[8]. پارامتر همان پارامتر فروپاشی نشانهها است که در آن برقرار است. هر چه قدر این پارامتر بیشتر تنظیم شود نشانهها بیشتر باقی میمانند که این معادل آن است که هر چه مقدار بیشتر باشد، نسبتهای تأثیری بیشتری از پاسخهای قبلی بر وضعیتها و اعمال آینده دور تأثیر میگذارند. اگر مقداردهی انجام شود یک الگوریتم یادگیری موازی با الگوریتمهای یادگیری تقویتی مونت کارلو ایجاد خواهد شد.



پیشبینی در یادگیری تفاوت زمانی
هر دو روش الگوریتم مونت کارلو و یادگیری تفاوت زمانی از تجربه برای حل مسئله پیشبینی استفاده میکنند. با داشتن چند تجربه که یک سیاست را در پیش دارند، هر دو روش تخمین خود از مقدار را به دست میآورند. یک روش مونت کارلو ساده شامل تمامی ملاقاتها که برای محیطهای ساکن مناسب است عبارت است از:




که در آن میزان بازگشت واقعی پس از زمان و پارامتر اندازه قدم است. بر خلاف روشهای مونت کارلو که عامل باید تا انتهای هر قسمت (episode) منتظر بماند تا میزان افزایش خود را محاسبه کند، در روشهای تفاوت زمانی عامل تنها تا گام زمانی بعدی صبر میکند. در زمان عاملهای تفاوت زمانی، بلافاصله مقدار مطلوب خود را شکل میدهند و با استفاده از پاداش مشاهده شده مقدار خود را به هنگام رسانی میکنند. سادهترین روش تفاوت زمانی که با عنوان شناخته میشود، عبارت است از:








به دست آوردن سیاست
سادهترین نوع الگوریتم تفاوت زمانی، (0)TD، به صورت کاملاً رویهای عمل میکند. معادلات زیر نحوه محاسبه را نشان میدهند. همچنین سودوکد الگوریتم (0)TD به صورت زیر ترسیم شدهاست.





مقایسه کلی با روشهای دیگر یادگیری تقویتی
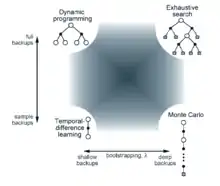
تمامی روشهای یادگیری تقویتی دارای ایدهای یکسان هستند. اول، هدف تمام آنها تخمین تابع ارزش است. دوم، تمامی آنها با نگهداری مقادیر در عبور از حالتهای مختلف ممکن یا واقعی عمل میکنند. سوم، تمامی آنها یک راهبرد برای پیمایش کلی سیاست (GPI) دارند، به این معنی که آنها یک تابع ارزش تقریبی و یک سیاست تقریبی را نگه میدارند و پیوسته هر کدام از آنها را بر مبنای دیگری بهبود میبخشند.
دو بعد مهم در روشهای یادگیری تقویتی در شکل روبرو مشاهده میشود. این ابعاد با نوع نگهداری که برای بهبود تابع ارزش استفاده شدهاست، مرتبط هستند. بعد عمودی نشان دهده این است که نگهداری آیا در نمونه هاست (بر اساس گذر از نمونه ها) یا نگهداری کامل است (بر اساس توزیع گذرهای ممکن). نگه داریهای کامل نیازمند یک مدل هستند حال آن که نگه داریهای نمونهای میتوانند بدون مدل نیز عمل کنند. بعد افقی به عمق این نگهداریها، یعنی درجه bootstrapping، مرتبط است. سه گوشه از چهار گوشه اشاره شده از روشهای مهم در تخمین ارزشها هستند: برنامهریزی پویا، یادگیری تفاوت زمانی و الگوریتم مونت کارلو.
جستارهای وابسته
- یادگیری ماشینی
- هوش مصنوعی
- یادگیری تفاوت زمانی
- یادگیری تقویتی
- کیو-یادگیری
- SARSA
- Rescorla-Wagner model
- Adaptive Heuristic Critic
- PVLV
یادداشتها
- Richard Sutton and Andrew Barto (1998). Reinforcement Learning. MIT Press. ISBN 0585024456. Archived from the original on 4 September 2009. Retrieved 10 December 2011.
- Richard Sutton (1988). "Learning to predict by the methods of temporal differences". Machine Learning. 3 (1): 9–44. doi:10.1007/BF00115009. (A revised version is available on Richard Sutton's publication page بایگانیشده در ۴ سپتامبر ۲۰۰۹ توسط Wayback Machine)
- میلاد وزان، یادگیری عمیق: اصول، مفاهیم و رویکردها، میعاد اندیشه، 1399
- Schultz, W, Dayan, P & Montague, PR. (1997). "A neural substrate of prediction and reward". Science. 275 (5306): 1593–1599. doi:10.1126/science.275.5306.1593. PMID 9054347.
- Schultz, W. (1998). "Predictive reward signal of dopamine neurons". J Neurophysiology. 80 (1): 1–27.
- Dayan, P. (2001). "Motivated reinforcement learning" (PDF). Advances in Neural Information Processing Systems. MIT Press. 14: 11–18. Archived from the original (PDF) on 25 May 2012. Retrieved 10 December 2011.
- Smith, A., Li, M., Becker, S. and Kapur, S. (2006). "Dopamine, prediction error, and associative learning: a model-based account". Network: Computation in Neural Systems. 17 (1): 61–84. doi:10.1080/09548980500361624. PMID 16613795.
- Tesauro, Gerald (March 1995). "Temporal Difference Learning and TD-Gammon". Communications of the ACM. 38 (3). Retrieved 2010-02-08.
منابع برای مطالعه بیشتر
- مدلهای به دست آمده از زمان برای تقویت پائولوفی
Sutton, R.S., Barto A.G. (1990). "Time Derivative Models of Pavlovian Reinforcement" (PDF). Learning and Computational Neuroscience: Foundations of Adaptive Networks: 497–537. Archived from the original (PDF) on 19 June 2009. Retrieved 10 December 2011.
- یادگیری تفاوت زمانی و TD-Gammon
Gerald Tesauro (March 1995). "Temporal Difference Learning and TD-Gammon". Communications of the ACM. 38 (3).
- یادگیری تقویتی در بازیهای صفحه ای
Imran Ghory. Reinforcement Learning in Board Games.
- روشهایی برای شبکههای پیچیده
S. P. Meyn, 2007. Control Techniques for Complex Networks, Cambridge University Press, 2007. See final chapter, and appendix with abridged Meyn & Tweedie.
پیوند به بیرون
- یادگیری تقویتی، نوشته شده توسط حامد عطیان فر
- یادگیری تقویتی در وب سایت رویاک
- صفحه اسکولارپدیا برای یادگیری تفاوت زمانی
Scholarpedia Temporal difference Learning
- گروه پژوهشی شبکههای تفاوت زمانی در دانشگاه آلبرتا