درخت تصمیم
درخت تصمیمگیری (Decision Tree) یک ابزار برای پشتیبانی از تصمیم است که از درختها برای مدل کردن استفاده میکند. درخت تصمیم بهطور معمول در تحقیقها و عملیات مختلف استفاده میشود. بهطور خاص در آنالیز تصمیم، برای مشخص کردن استراتژی که با بیشترین احتمال به هدف برسد بکار میرود. استفاده دیگر درختان تصمیم، توصیف محاسبات احتمال شرطی است.
کلیات
در آنالیز تصمیم، یک درخت تصمیم به عنوان ابزاری برای به تصویر کشیدن و آنالیز تصمیم، در جایی که مقادیر مورد انتظار از رقابتها متناوباً محاسبه میشود، استفاده میگردد. یک درخت تصمیم دارای سه نوع گرهاست:
۱-گره تصمیم: بهطور معمول با مربع نشان داده میشود.
۲-گره تصادفی: با دایره مشخص میشود.
۳-گره پایانی: با مثلث مشخص میشود.
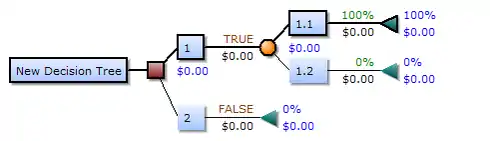
نمودار درخت تصمیمگیری
یک درخت تصمیم میتواند خیلی فشرده در قالب یک دیاگرام، توجه را بر روی مسئله و رابطه بین رویدادها جلب کند.
مربع نشان دهنده تصمیمگیری، بیضی نشان دهنده فعالیت، و لوزی نشان دهنده نتیجهاست.
مکانهای مورد استفاده
درخت تصمیم، دیاگرام تصمیم و ابزارها و روشهای دیگر مربوط به آنالیز تصمیم به دانشجویان دوره لیسانس در مدارس تجاری و اقتصادی و سلامت عمومی و تحقیق در عملیات و علوم مدیریت، آموخته میشود.
یکی دیگر از موارد استفاده از درخت تصمیم، در علم دادهکاوی برای classification است.
الگوریتم ساخت درخت تصمیمگیری
مجموع دادهها را با نمایش میدهیم، یعنی ، به قسمی که و . درخت تصمیمگیری سعی میکند به صورت بازگشتی دادهها را به قسمی از هم جدا کند که در هر گِرِه متغیرهای مستقلِ به هم نزدیک شده همسان شوند.[1] هر گِره زیر مجموعه ای از داده هاست که به صورت بازگشتی ساخته شدهاست. بهطور دقیقتر در گره اگر داده ما باشد سعی میکنیم یک بُعد از متغیرهایی وابسته را به همراه یک آستانه انتخاب کنیم و دادهها را برحسب این بُعد و آستانه به دو نیم تقسیم کنیم، به قسمی که بطور متوسط در هر دو نیم متغیرهای مستقل یا خیلی به هم نزدیک و همسان شده باشند. این بعد و آستانه را مینامیم. دامنه برابر است با و یک عدد صحیح است. برحسب به دو بخش و به شکل پایین تقسیم میشود[1]:














حال سؤال اینجاست که کدام بُعد از متغیرهای وابسته و چه آستانهای را باید انتخاب کرد. به زبان ریاضی باید آن یی را انتخاب کرد که ناخالصی داده را کم کند. ناخالصی برحسب نوع مسئله تعریفی متفاوت خواهد داشت، مثلا اگر مسئله یک دستهبندی دوگانه است، ناخالصی میتواند آنتراپی داده باشد، کمترین ناخالصی زمانی است که هم و هم از یک دسته داشته باشند، یعنی در هر کدام از این دو گِرِه دو نوع دسته وجود نداشته باشد. برای رگرسیون این ناخالصی میتواند واریانس متغیر وابسته باشد. از آنجا که مقدار داده در و با هم متفاوت است میانگینی وزندار از هر دو ناخالصی را به شکل پایین محاسبه میکنیم.[2] در این معادله ، و :





هدف در اینجا پیدا کردن آن یی است که ناخالصی را کمینه کند، یعنی . حال همین کار را به صورت بازگشتی برای و انجام میدهیم. بعضی از گرهها را باید به برگ تبدیل کنیم، معیاری که برای تبدیل یک گره به برگ از آن استفاده میکنیم میتواند مقداری حداقلی برای (تعداد داده در یک گره) و یا عمق درخت باشد به قسمی که اگر با دو نیم کردن گِره یکی از معیارها عوض شود، گِره را به دو نیم نکرده آن را تبدیل به یک برگ میکنیم. معمولاً این دو پارامتر باعث تنظیم مدل (Regularization) میشوند[2]. در ابتدای کار گره شامل تمام دادهها میشود یعنی .



مسئله دستهبندی
اگر مسئله ما دستهبندی باشد و باشد تابع ناخالصی برای گره میتواند یکی از موارد پایین باشد، در این معادلهها [3]:


ناخالصی گینی:

ناخالصی آنتروپی:

ناخالصی خطا:

مسئله رگرسیون
در مسئله رگرسیون ناخالصی میتواند یکی از موارد پایین باشد:
میانگین خطای مربعات:

میانگین خطای قدر مطلق:

مزایا
در میان ابزارهای پشتیبانی تصمیم، درخت تصمیم و دیاگرام تصمیم دارای مزایای زیر هستند:
۱- فهم ساده: هر انسان با اندکی مطالعه و آموزش میتواند، طریقه کار با درخت تصمیم را بیاموزد.
۲- کار کردن با دادههای بزرگ و پیچیده: درخت تصمیم در عین سادگی میتواند با دادههای پیچیده به راحتی کار کند و از روی آنها تصمیم بسازد.
۳-استفاده مجدد آسان: در صورتی که درخت تصمیم برای یک مسئله ساخته شد، نمونههای مختلف از آن مسئله را میتوان با آن درخت تصمیم محاسبه کرد.
۴- قابلیت ترکیب با روشهای دیگر: نتیجه درخت تصمیم را میتوان با تکنیکهای تصمیمسازی دیگر ترکیب کرده و نتایج بهتری بدست آورد.
معایب
۱- مشکل استفاده از درختهای تصمیم آن است که به صورت نمایی با بزرگ شدن مسئله بزرگ میشوند. ۲- اکثر درختهای تصمیم تنها از یک ویژگی برای شاخه زدن در گرهها استفاده میکنند در صورتی که ممکن است ویژگیها دارای توزیع توأم باشند. ۳- ساخت درخت تصمیم در برنامههای داده کاوی حافظه زیادی را مصرف میکند زیرا برای هر گره باید معیار کارایی برای ویژگیهای مختلف را ذخیره کند تا بتواند بهترین ویژگی را انتخاب کند.
منابع
- Sequential decision making with partially ordered preferences Daniel Kikuti, Fabio Gagliardi Cozman , Ricardo Shirota Filho
مثال ۱
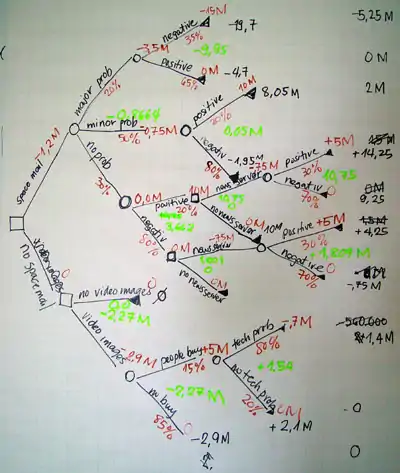
درخت تصمیم در بهینهسازی مشارکت اوراق بهادار مورد استفاده قرار گیرد. مثال زیر اوراق بهادار ۷ طرح مختلف را نشان میدهد. شرکت ۱۰۰۰۰۰۰۰۰ برای کل سرمایهگذاریها دارد. خطوط پر رنگ نشان دهنده بهترین انتخاب است که موارد ۱، ۳، ۵، ۶ و۷ را در بر میگیرد و هزینهای برابر ۹۷۵۰۰۰۰ دارد و سودی برابر ۱۶۱۷۵۰۰۰ برای شرکت فراهم میکند. مابقی حالات یا سود کمتری دارد یا هزینه بیشتری میطلبد.[4]
مثال ۲
در بازی بیست سؤالی، بازیکن باید یک درخت تصمیم در ذهن خود بسازد که به خوبی موارد را از هم جدا کند تا با کمترین سؤال به جواب برسد. در صورتی بازیکن به جواب میرسد که درخت ساخته شده بتواند به خوبی موارد را از هم جدا کند.
جستارهای وابسته
منابع
پیوند به بیرون
|