فهرست خودسازماندهیکننده
فهرست خودسازماندهنده یا لیست خودسازماندهنده (به انگلیسی: self-organizing list) فهرستی است که ترتیب عناصر خود را مطابق با جستجوهای صورتگرفته برای پیدا کردن عناصر تغییر میدهد تا زمان دسترسی میانگین برای هر عنصر را بهبود بخشد. هدف فهرست خودسازماندهنده افزایش سرعت جستجوی خطی است؛ به این صورت که عناصری را که احتمال دسترسی به آنها بیشتر است (یعنی تعداد دفعات درخواست شده برای دستیابی به آنها نسبت به بقیهٔ عناصر بیشتر است) را در ابتدای فهرست قرار میدهد.
تاریخچه
ریشهٔ مفهوم «فهرست خودسازماندهنده» یا «لیست خودسازماندهنده» به سازماندهی پروندههای ذخیرهشده در نوارها و دیسکها برمیگردد. استراتژی انتقال رو به جلو، که هر عنصر پس از آن که جستجو میشود در ابتدای فهرست قرار میگیرد، برای نخستین بار در سال ۱۹۶۵ و توسط شخصی به نام McCabe مطرح شد.[1] او زمان متوسط مورد نیاز برای جستجو، در فهرستی با آرایش تصادفی عناصر را بررسی کرد تا به حالتی بهینه برای ترتیب عناصر دست یابد. ترتیب بهینه در این فهرست در حالتی روی میداد که عناصر هریک بر اساس احتمال دسترسی خود مرتب شوند به صورتی که عنصری با بیشترین میزان دسترسی در سر فهرست قرار بگیرد. ترتیب بهینه ترتیبی از پیش تعیین شده نبود و در طول زمان میتوانست تغییر کند. پس از آن McCabe استراتژی جابهجایی را ارائه داد که در آن هر عنصر در هنگام جستجو به جای انتقال به سر فهرست با عنصر ماقبلش در فهرست جابهجا میشود، او حدس زد که محدودهٔ زمان جستجوی میانگین در استراتژی جابهجایی، با فرض استقلال جستجوها، از همین زمان در استراتژی انتقال رو به جلو بیشتر نمیشود. این حدس او بعدها توسط شخصی به نام Rivest اثبات گردید.[2] علاوه بر موارد فوق McCabe توانست نشان دهد که هر دو روش انتقال رو به جلو و نیز جابهجایی در نهایت به ترتیب بهینه منجر میشوند. با دستیابی به پیشرفتهای بیشتر، الگوریتمهای دیگری توسط محققانی همچون ریوِست، تِنِنباوم، نیمز، کنوت، بنتلی، و McGeoch ارائه شد.
مقدمه
یکی از سادهترین روشهای پیادهسازی فهرست خودسازماندهنده، استفاده از لیست پیوندی است. از این رو اگرچه این پیادهسازی برای درج یک عنصر به صورت تصادفی و از لحاظ تخصیص حافظه کارآمد است، دسترسی تصادفی به یک عنصر را به سادگی ممکن نمیسازد. یک فهرست خودسازماندهنده این ناکارآمدی را با بازآرایی عناصر برپایهٔ تعداد دسترسیها کاهش میدهد.
ناکارآمدی در پیمایش لیست پیوندی
در یک لیست پیوندی برای دستیابی به دادهٔ nاُم نیازمند مقایسههای متوالی هستیم؛ چراکه باید از سر فهرست شروع کنیم و تکتک گرهها را بپیماییم تا به عنصر nاُم دست یابیم؛ بنابراین هزینهٔ این عملیات در لیست پیوندی از مرتبهٔ (O(n است که در مقایسه با آرایه که هزینهٔ چنین عملیاتی در آن از مرتبهٔ (O(1 است بسیار ناکارآمد بهشمار میآید.
کارآمدیِ فهرست خودسازماندهنده
در یک فهرست خود سازمان دهنده با استفاده از مفهومی به نام اصل پارتو که بیان میکند ۸۰ درصد از دسترسیها به ۲۰ درصد عناصر است و به عبارت دیگر دسترسی به برخی عناصر بیشتر رخ میدهد، ایدهای برای سازماندهی فهرست شکل گرفتهاست. در این ایده در یک درخواست معین عناصر بر طبق تعداد جستجوها سازماندهی میشوند و دادههایی که میزان دسترسی بیشتری نسبت به سایرین دارند در سر فهرست نگهداری میشوند. بدین ترتیب تعداد مقایسههای لازم برای دسترسی به یک گره خاص در حالت میانگین کاهش مییابد و کارایی فهرست افزایش خواهد یافت.
پیادهسازی فهرست خودسازماندهنده
پیادهسازی فهرست خود سازمان، دقیقاً مشابه فهرست پیوندی است و تمام توابع در هر دو یکسان اند و تنها تفاوت موجود میان این دو فهرست در نحوهٔ قرار گرفتن عناصر است که ترتیب عناصر در فهرست خودسازماندهنده همانطور که بیان شد بر اساس احتمال دسترسی عناصر است.
بررسی زمان اجرا جستجو در فهرست/دسترسی
یک فهرست خودسازماندهنده شامل n عنصر را در نظر بگیرید که با استفاده از فهرست پیوندی پیادهسازی شدهاست. هزینهٔ لازم برای جستجو با این فرض که عنصر مورد جستجو در فهرست وجود دارد با تعداد مقایسههایی که برای پیدا کردن آن عنصر باید صورت گیرد اندازهگیری میشود. در ادامه این زمان در حالت میانگین، بدترین حالت و بهترین حالت محاسبه شدهاست:
حالت میانگین
در این حالت برای بدست آوردن زمان میانگین لازم برای جستجوی عنصر iام با دانستن تعداد دفعات جستجو برای این عنصر() از طریق محاسبهٔ امید ریاضی این زمان را اندازهگیری میکنیم:


در این محاسبه همان احتمال دسترسی برای عنصر i ام است. حال اگر این احتمال برای همهٔ عناصر یکسان باشد (یعنی داشته باشیم : ) داریم:



همانطور که محاسبه شد، در این حالت زمان میانگین به احتمال دسترسی به عناصر بستگی ندارد.
در مورد جستجو در فهرستی با توزیع غیر یکنواخت دسترسی به عناصر، (حالتی که در آن احتمال دسترسی به یک عنصر با عنصر دیگر متفاوت است) این زمان میتواند تا حد خوبی با تغییر کردن جایگاههای عناصر نسبت به هم کاهش داشته باشد؛ چرا که در آن حالت iهایی با مقادیر کمتر در احتمالات بزرگتر ضرب شده و (T(n در مجموع کمتر میشود.
برای داشتن شهودی قویتر از مطلب مذکور از مثال زیر استفاده میکنیم:
در فهرست روبهرو، احتمال هر عنصر در مقابل آن نوشته شدهاست:
زمان میانگین در حالتی که ترتیب عناصر با توجه به احتمال دسترسی آنها تغییر نکرده باشد برابر خواهد بود با:

حال اگر فهرست بر اساس احتمال دسترسی عناصر سازماندهی شود بهطوریکه عناصری با احتمال دسترسی بیشتر در سر فهرست قرار گیرند فهرست به صورت زیر در میآید:
F(0.5), C(0.4), D(0.3), B(0.2), A(0.1), E(0.1)
که زمان میانگین در این حالت به صورت مقابل محاسبه میشود:

همانطور که مشاهده شد زمان میانگین مورد نیاز در حالتی که عناصر بر اساس احتمال دسترسی به آنها مرتب شدهاند نسبت به حالتی که عناصر به صورت تصادفی در فهرست جای گرفتهاند کاهش یافتهاست. به این ترتیب زمان میانگین مورد نیاز برای جستجوی یک عنصر در حالت میانگین در فهرست خودسازماندهنده نسبت به فهرست پیوندی کاهش داشته و این امر مزیتی برای فهرست خودسازماندهنده محسوب میشود.
بدترین حالت
بدترین حالت زمانی رخ میدهد که جستجوی عنصر انتهاییِ فهرست مد نظر ما باشد. در این حالت چه در فهرست معمولی و چه در فهرست خودسازماندهنده با n عنصر نیازمند n مقایسه خواهیم بود. پس زمان اجرا در بدترین حالت، مستقل از نوع فهرست، از مرتبهٔ (O(n خواهد بود. احتمال رخداد بدترین حالت کم است اما این احتمال کم به منزلهٔ نادیده گرفته شدن این حالت نیست. در فهرست خودسازماندهنده که عناصر بر اساس احتمال دسترسی آنها سازماندهی میشوند بدترین حالت همان حالتی است که عنصری که احتمال دسترسی به آن از بقیه کمتر است مورد جستجو قرار گرفته باشد که در این حالت به علت قرار گرفتن این عنصر در انتهای فهرست باید تمام فهرست پیمایش شود؛ لذا برای فهرستی با طول n به n مقایسه نیاز داریم.
بهترین حالت
در بهترین حالت عنصری که احتمال دسترسی به آن بیشتر است مورد جستجو خواهد بود. این عنصر در فهرست خودسازمان دهنده در ابتدای فهرست قرار دارد و با انجام یک عمل مقایسه مشخص میشود؛ لذا مرتبهٔ زمانی جستجو در این حالت (O(1 خواهد بود.
روشهای سازماندهی عناصر
از آن جایی که در هنگام مرتب کردن عناصر در یک فهرست خودسازماندهنده احتمال دسترسی به آنها بهطورکلی و از قبل مشخص نیست، روشهای متفاوتی برای این سازماندهی شکل گرفتهاست که در زیر به مهمترینهای آنها پرداخته شدهاست:
روش انتقال به جلو (MTF)
در این روش عنصر مورد جستجو به سر فهرست حرکت داده میشود.
مزیتها: پیادهسازی این روش آسان است و نیاز به هیچ گونه حافظهٔ اضافی ندارد. همچنین این روش با عوض شدن عنصر مورد جستجو در یک الگوی درخواست سازگار است.
معایب: یکی از عیوب این روش این است که هر عنصری که مورد جستجو قرار بگیرد، به سر فهرست منتقل میشود. حال اگر این عنصر، عنصری با کمترین احتمال دسترسی باشد (تعداد دفعات جستجوی آن عنصر در مجموعهای از درخواستها کمتر از باقی عناصر باشد)، قرار گرفتن آن در سر فهرست موجب میشود دسترسی به سایر عناصر کندتر صورت گیرد. همچنین، انتقال عنصر مورد جستجو در هر درخواست به ابتدای فهرست سبب میشود که اگر فهرستی در ابتدا در حالت بهینه قرار داشته باشد، جستجوهای مکرر سبب از بین رفتن آرایش بهینهٔ آن شوند.
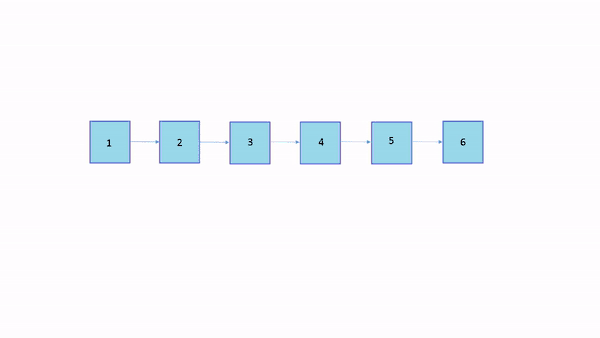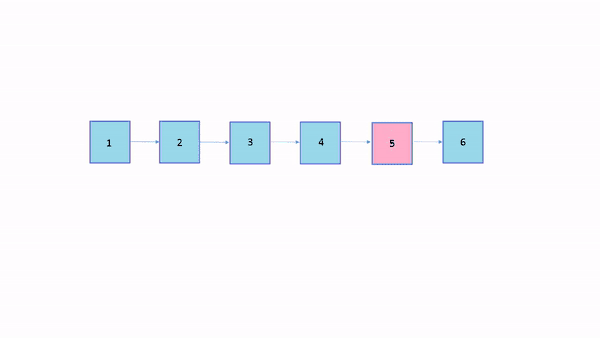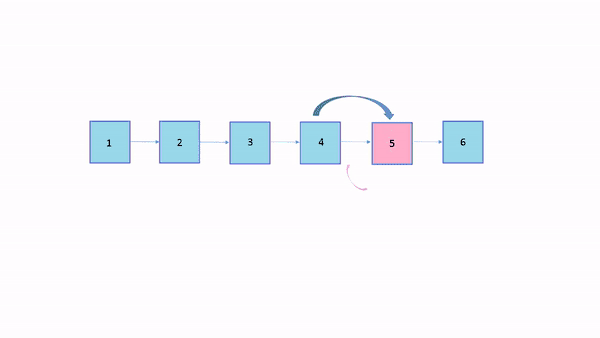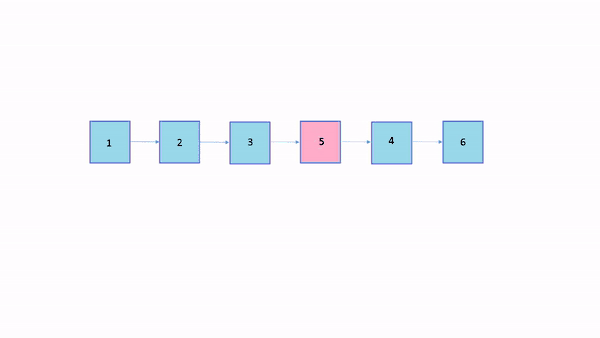
با انتخاب عنصر ۵ام آن عنصر به ابتدای فهرست منتقل میشود:

روش شمارش
در این روش تعداد دفعاتی که هر عنصر مورد جستجو قرار میگیرد شمرده میشود. بدین منظور برای هر عنصر متغیری به عنوان شمارنده در نظر گرفته میشود و مقدار این شمارنده با هر بار جستجوی خانهٔ نظیر آن افزایش مییابد. سپس تمام عناصر بهطور غیر صعودی بر اساس مقدار شمارندهٔ خود مرتب میشوند که در نتیجه عناصری با میزان دسترسی بیشتر در سر فهرست قرار خواهند گرفت.
مزیتها: این روش به نسبت دیگر روشها الگوی واقعیتری از جستجوهای صورت گرفته شده ارائه میدهد.
معایب: از آن جایی که در این روش برای هر عنصر یک شمارنده نگهداری میشود، استفاده از این روش سبب مصرف حافظهٔ اضافی میگردد. همچنین سازگار نبودن این روش با ایجاد شدن تغییرات سریع در الگوهای دسترسی از دیگر معایب آن محسوب میشود. بدین معنی که اگر تعداد دسترسیها برای عنصری که در فهرست قرار دارد و آن را A مینامیم ۱۰۰ باشد و این تعداد برای هر عنصر دیگری که در سر فهرست نیست و آن را B مینامیم ۴۰ باشد، اگر هماکنون عنصر B عنصر جدید مورد جستجو باشد باید حداقل ۶۰ بار مورد جستجو قرار بگیرد تا بتواند عنصر سر فهرست قرار گرفته و سبب بهینه شدن فهرست شود.
اگر عنصر پنجم دو بار دیگر مورد جستجو قرار بگیرد با عنصر چهارم جابهجا میشود:
.gif)
روش جابهجایی
این روش شامل جابهجایی عنصر مورد جستجو و عنصر ماقبل آن است. بدین ترتیب هر عنصری که جستجو میشود در صورتی که عنصر ابتداییِ فهرست نباشد با عنصر پیش از خود جابهجا میشود تا اولویت آن افزایش پیدا کند.
مزیتها: این روش نیز همانند روش انتقال به جلو حافظهٔ اضافی مصرف نمیکند و همچنین پیادهسازی آن آسان است. علاوه بر آن در این روش عناصری با بیشترین میزان دسترسی به احتمال زیاد در ابتدای فهرست قرار خواهند گرفت.
معایب: برای حرکت یک عنصر به سمت سر فهرست، نیازمند تعداد جستجوهای زیادی خواهیم بود و همیچنین این روش نیز به سرعت با تغییرات ایجاد شده در الگوی دادهها سازگاری پیدا نمیکند و حالت اولیهٔ آن حفظ میشود.
دیگر روشها
به دنبال تلاشهای McCabe، پژوهشهای زیادی برای پیدا کردن روشهایی شکل گرفت که هم بتوانند از سرعت روش انتقال رو به جلو سود ببرند و هم از دقت روش جابهجایی. در این راستا میتوان الگوریتم بیتنر را نام برد که در واقع ترکیبی از دو الگوریتم فوق است. این الگوریتم به نحوی است که ابتدا روش انتقال رو به جلو اجرا میشود و سپس برای سازماندهی دقیقتر روش جابهجایی به کار گرفته میشود. روشهای دیگری نیز وجود دارند که بر پایهٔ الگوریتمهای بالا پس از هر n جستجو در فهرست یا n جستجوی پشت سر هم یک عنصر خاص فهرست و… شکل گرفتهاند. الگوریتمهایی همانند تعویض با پدر یا انتقال به پدر نیز وجود دارند که سازماندهی گرههای مورد جستجو را بر اساس نزدیکی آنها به عنصر سر فهرست انجام میدهند. دستهای دیگر از الگوریتمها مربوط به الگوهای جستجویی هستند که در آنها در یک بازهٔ زمانی مشخص زیر مجموعهای از فهرست با احتمال بیشتری مورد دسترسی قرار میگیرد و تغییرات عمدتاً در آن زیر مجموعه رخ میدهد. چنین الگوهای جستجویی دارای ویژگی منبع محلی هستند. این ویژگی همچنین نشان دهندهٔ دسترسیهای وابسته است که به منزلهٔ این است که احتمال دسترسی به یک عنصر مشخص به احتمال دسترسی به عناصر مجاورش وابسته است. مثال از پدیدههایی که ویژگی منبع محلی را دارند در حوزهٔ علوم کامپیوتر فراوان است؛ مانند سامانههای پایگاه داده، مدیریت حافظه و سیستمهای پرونده.
برنامههای کاربردی مرتبط با فهرست خودسازماندهنده
مترجمان زبانهای برنامهنویسی همانند کامپایلرها و مفسرها از فهرستهای خودسازماندهنده به منظور حفظ جدول نمادها در طول ترجمه و تفسیر کد اصلی برنامه استفاده میکنند. بهعلاوه فهرستهای خودسازماندهنده در شبکههای اطلاعاتی و عصبی و برنامههای خودتنظیمکننده نیز مورد استفاده واقع میشوند.
منابع
- McCabe, John (1965), "On Serial Files with Relocatable Records", Operations Research, INFORMS, 13 (4): 609–618, doi:10.1287/opre.13.4.609
- Becker, J.; Hayes, R.M. (1963), Information Storage and Retrieval: Tools, Elements, Theories, New York: Wiley
- مشارکتکنندگان ویکیپدیا. «Self-organizing list». در دانشنامهٔ ویکیپدیای انگلیسی، بازبینیشده در ۱۶ ژانویهٔ ۲۰۱۷.
- J.H. Hester and D.S. Hirschberg. Self-Organizing Linear Search. University of California, Irvine. Available from: https://www.ics.uci.edu/~dan/pubs/searchsurv.pdf
- The Author 2006. "A Novel Framework for Self-Organizing Lists in Environments with Locality of Reference: Lists-on-Lists". Oxfordjournals. doi:10.1093/comjnl/bxl067
- Self Organization (pdf), 2004
- AMER and OoMMEN, ABDELRAHMAN and B.J. (2006), Self-Organizing Lists in Environments, Oxford, doi:10.1093/comjnl/bxl067