استنباط بیزی تغییراتی
استنباط بیزی تغییراتی (به انگلیسی: Variational Bayes Inference) از جمله روش های رایج در یادگیری بیزی است که برای تقریب جواب با استفاده از یک سری فرض های استقلال در توزیع پَسین (به انگلیسی: Posterior distribution) است. نکته مشکل ساز در یادگیری بیزی این است که برای حساب کردن توزیع پسین لازم است انتگرالی روی تمام حالات ممکن متغیرهای پنهان حساب شود که به درست نمایی حاشیه ای (به انگلیسی: marginal likelihood) معروف است. استنباط تغییراتی سعی در تقریب این انتگرال دشوار دارد تا یادگیری مدل و استنباط با آن را آسان تر کند. به عبارتی دیگی، روش استنباط بیزیِ تغییراتی
- تقریبی برای توزیع پَسین می دهد. با استفاده از این تقریب و داشتن پارامترهای مدل، می توان استنباط آماری روی داده های دیده نشده انجام داد.
- کرانی پایین برای درست نمایی حاشیه ای (یا "گواه"(به انگلیسی: evidence)) روی داده های آموزشی می دهد. با استفاده از این کران می توان پارامترهای مدل را یاد گرفت ("یادگیری مدل" یا model selection). ایده ی کلی این است که هرچه مقدار درست نمایی برای داده های مورد نظر بیشتر باشد، پارامترها برای مدل و داده ها مناسب تر هستند.
می توان گفت روش استنباط تغییراتی، تعمیمی از یادگیری "حداکثرسازی امید" (به انگلیسی: Expectation Maximization) است.
یک نمونه ساده
فرض کنید یک مدل ساده بیزی داریم که در آن مجموعه ای از داده های iid از یک توزیع گوسی با میانگین و واریانس نامشخص در اختیار داریم[1]. در این مثال با جزئیات زیاد سعی داریم عملکرد یادگیری و استنباط تغییراتی را نشان دهیم.
مدل ریاضی
در مدل سازی پارامترهای مسئله، برای مدل سازی پارامترها، از توزیع مزدوج پیشین (به انگلیسی: conjugate prior) استفاده می کنیم. یعنی برای میانگین توزیع نرمال، و برای واریانس توزیع گاما در نظر می گیریم:

اکنون نقطه در اختیار داریم و هدف این است که توزیع پسین را برای پارامترهای مدل و یادبگیریم. فراپارامترهای مدل، یعنی , , و مقادیری ثابت هستند.









توزیع مشترک
توزیع مشترک متغیرهای مسئله به صورت زیر است:

که هرکدام از آنها بر اساس فاکتورهایشان به صورت زیر هستند:

که در آن:

فرض استقلال توزیع ها
فرض کنید که توزیع روی پارامترهای مسئله به صورت تجزیه شوند. در اصل چنین فرضی درست نیست. چرا که پارامتر واریانس توزیع نرمال میانگین وابسته به توزیع گاما است. اما به صورت تقریبی فرض استقلال فوق را انجام می دهیم. چنین فرضی باعث ایجاد خطا در نتیجه ی نهایی خواهد شد، اما در قبال این خطا، سرعت بیشتری در یادگیری مدل به دست می آوریم. فرض استقلال بین توزیع های پارامترهای مسئله اساس روش استنتاج تغییراتی است.

بدست آوردن فاکتور q(μ)

در عبارت فوق پارامترهای , و مقادیر ثابت نسبت به پارامتر هستند. با توجه به عبارت آخر مشاهده می شود که توزیع حول دارای توزیع گوسی است. با کمی بازی با جملات ریاضی می توان توزیع را به فرم گوسی استاندارد نوشت و جمله ای برای میانگین و واریانس آن بدست آورد.




به عبارت دیگر:

بدست آوردن فاکتور q(τ)
بدست آوردن فاکتور تا حد زیادی مشابه مراحل بالاست.


با به توان رساندن دو طرف، توزیع نهایی به صورت یک توزیع گاما بدست می آید.

الگوریتم محاسبه ی پارامترهای بهینه مسئله
بگذارید نتایجی را که از قسمت های قبل بدست آوردیم را یادآوری کنیم:

و

در هر کدام از موارد فوق، امید روی یک پارامتر، وابسته به امید روی پارامترهای دیگر است. می توان این روابط را بر اساس روابط پایه آماری بسط داد.

اعمال روابط فوق به پارامترها سر راست است. در اینجا تنها به توضیح رابطه ی مربوط به می پردازیم.


می توان پارامترهای دیگر را دیگر را به صورت زیر نوشت:

در عبارات فوق به وابستگی روابط مربوط به , و به همدیگر توجه کنید که تشکیل یک الگوریتم حداکثر سازی امیدریاضی (به انگلیسی: expectation maximization) می دهند. می توان مراحل اجرای الگوریتم را به صورت زیر خلاصه کرد:


- با استفاده از و مقادیر مربوط به و را حساب کنید.
- پارامتر را با مقداری اولیه، مقداردهی کنید.
- با استفاده از پارامترهای مسئله و از جمله ، مقدار را تخمین بزنید.
- با استفاده از پارامترهای مسئله و از جمله ، مقدار را تخمین بزنید.
- مراحل فوق را تا رسیدن به همگرایی (جایی که هیچکدام از پارامترها دیگر تغییر زیادی نکنند.) انجام دهید.



می توان نشان داد که این بروز رسانی دوری تضمین شده است که به مقدار بهینه محلی همگرا خواهد شد. می توان اثبات کرد که چون توزیع حول هردو پارامتر و توزیع پسین نمایی است، حتماً به نقطه بهینه جهانی همگرا خواهد شد. نکته ظریف اینجاست این نقطه بهینه مربوط به مسئله با تقریب مستقل بودن توزیع پارامترهای مسئله است و در هر صورت نسبت جواب مسئله اصلی تقریبی است.
یک نمونه ی نسبتاً پیچیده تر
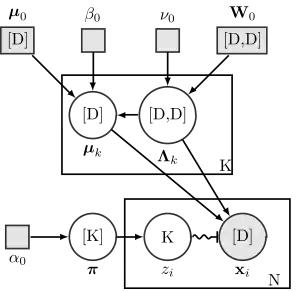
فرض کنید یک نمونه مدل مخلوط گوسی به صورت زیر تعریف شده باشد:

چند نکته:
- توزیع توزیع متقارن دیریکله با بعد است که دارای فراپارامتر است. توزیع دیریکله، توزیع مزدوج پیشین توزیع های categorical و multinomial است.
- توزیع توزیع ویشارت که توزیع مزدوج پیشین برای ماتریس دقت (عکس ماتریس کواریانس) در توزیع نرمال چند متغیره است.
- توزیع چندجملهای روی یک مشاهده (معادل توزیع categorical) است.
- توزیع نرمال چند متغیره است.






می توان توزیع مشترک روی متغیرهای مسئله را به صورت زیر نوشت:

می توان هر کدام از فاکتورهای مسئله را به صورت زیر ساده سازی کرد:

که در آن:

اگر فرض کنیم بنابرین:


که آن تعریف کرده ایم:

با به توان رساندن هر دو طرف داریم:

به صورتی معادل می توان عبارت فوق را به صورت زیر نوشت:

که در آن:

همچنین توجه کنید که

که به صورت طبیعی از توزیع categorical بدست می آید. با توجه به فاکتوریزه کردن به صورت می توان نوشت:



با به توان رساندن دو طرف می توان دید که دارای توزیع دریکله است.


که در آن

همچنین

در نهایت داریم:

می توان نتیجه کلی را به اینصورت نوشت:

که دارای پارامترهای زیر است:



با اجرای پی در پی مراحل بروز رسانی می توان مدل را آموزش داد:
- محاسبه ی با استفاده از سایر پارامترها(E-step).
- محاسبه ی با استفاده از سایر پارامترهای(M-step).

منابع
- Pattern Recognition and Machine Learning by کریستوفر بیشاپ بر اساس فصل دهم
- Bishop, Christopher M. (2006). Pattern Recognition and Machine Learning. Springer. ISBN 0-387-31073-8.
پیوند به بیرون
- Variational-Bayes Repository A repository of papers, software, and links related to the use of variational methods for approximate Bayesian learning
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by دیوید جی سی ماکای provides an introduction to variational methods (p. 422).
- Variational Algorithms for Approximate Bayesian Inference, by M. J. Beal includes comparisons of EM to Variational Bayesian EM and derivations of several models including Variational Bayesian HMMs.
- A Tutorial on Variational Bayes. Fox, C. and Roberts, S. 2011. Artificial Intelligence Review, doi:10.1007/s10462-011-9236-8.
- High-Level Explanation of Variational Inference by Jason Eisner may be worth reading before a more mathematically detailed treatment.