تجزیهکننده کاهشی بازگشتی
تجزیهکننده کاهشی بازگشتی ( انگلیسی: Recursive descent parser) یک تجزیهکننده بالا به پایین است که درخت تجزیه را از بالا و حالت اولیه میسازد تا به رشته ورودی کاربر برسد. این تجزیهکننده به صورت بازگشتی، ورودی را تجزیه میکند تا درخت تجزیه را بسازد.[1]
با ساختن درخت از بالا به پایین، احتمال وجود عقبگردی در مراحل وجود دارد که نقطه ضعف این روش برشمرده میشود ولی با نوع پیشبینیکننده آن که از رشته ورودی برای پیشبینی اقدام بعدی استفاده میکند، میتوان عقبگرد را از میان برداشت.
این تجزیهکننده از گرامر مستقل از متن که به صورت بازگشتی پیادهسازی میشود، استفاده میکند.[2]تجزیهکنندههای کاهشی بازگشتی نمیتوانند دستور زبانهای چپگرد را تجزیه کنند (چون در حلقهٔ بینهایت گیر میکنند) و ابتدا باید این چپگردی را رفع نمود.
نحوه اعمال تجزیه
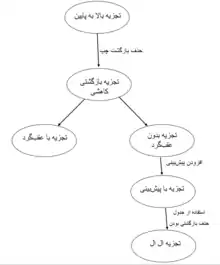
برای این تجزیه ابتدا برای همهٔ نمادهای ناپایانی گرامر از جمله نماد شروع، یک تابع در نظر میگیریم، که در واقع روند تجزیه آن را شامل میشود و همهٔ رشتههایی که از آن مشتق میشوند در این تابع صدق میکنند.
در صورتی که نماد ناپایانی N فقط یک قاعده را در گرامر داشته باشد (در سمت چپ فقط یک قاعده آمدهباشد) تابع تجزیه آن آسان خواهد بود و به ترتیب نمادها در سمت راست آن پیش میرویم. اگر نماد بعدی یک نماد پایانی بود آن را نماد پیشرو در ورودی چک میکنیم اگر یکسان بود، هم در ورودی و هم در سمت راست قاعده یک نماد جلوتر میرویم و اگر نبود، خطا گزارش میدهیم. اگر نماد بعد یک نماد ناپایانی بود، تابع متناظر آن نماد ناپایانی را فراخوانی میکنیم به این صورت ادامه میدهیم تا به انتهای سمت راست قاعده میرسیم.
در صورتی که نماد ناپایانی N، در سمت چپ چندین قاعده بود، تابع تجزیه نیاز دارد تصمیم بگیرد از کدام قاعده استفاده کند. در صورتی که تجزیه ما پیشبینیکننده نباشد یکی از قاعدهها را انتخاب میکند و در صورت بروز خطا در اجرای این قاعده، قاعده دیگر مشتق شده از N را فراخوانی میکند. تا زمانی که یکی از قاعدهها به درستی اجرا شود.
ولی در صورتی که تجزیهکننده ما قابلیت پیشبینیکنندگی داشته باشد، براساس نماد پیشرو ورودی و مقایسه قواعد مشتقشده، یک قاعده را انتخاب میکند.[3]
شبه کد
N() {
if (lookahead can start first rule for N) {
match rule 1 for N
}
else if (lookahead can start second rule for N) {
match rule 2 for N
}
... ...
else if (lookahead can start n'th rule for N) {
match rule n for N
else {
error();
}
}
پیادهسازی در جاوا
مثال ساده روبرو که گرامر سادهای از عبارتهای ریاضی با پرانتز کامل، را نشان میدهد. در ادامه طبق تجزیهکننده کاهشی بازگشتی به زبان جاوا پیادهسازی شدهاست.
<expression> ::= <number> |
"(" <expression> <operator> <expression> ")"
<operator> ::= "+" | "-" | "*" | "/"
در تکه کد زیر، تابع ParseError جهت نمایش خطاهای نحوی در رشته ورودی کاربر تعریف شدهاست.
private static class ParseError extends Exception {
ParseError(String message) {
super(message);
}
}
تکه کد زیر برای این پیادهسازی شده که کاراکتر بعدی در ورودی را بخواند و اگر از جمله عملیاتهای مجاز بود، آن را برگرداند در غیر این صورت خطا دهد.
static char getOperator() throws ParseError {
TextIO.skipBlanks();
char op = TextIO.peek();
if ( op == '+' || op == '-' || op == '*' || op == '/' ) {
TextIO.getAnyChar();
return op;
}
else if (op == '\n')
throw new ParseError("Missing operator at end of line.");
else
throw new ParseError("Missing operator. Found \"" +
op + "\" instead of +, -, *, or /.");
}
کد زیر برای خواندن یک عبارت ریاضی از یک خط ورودی و برگرداندن مقدار نهایی آن است. در صورت که ورودی دارای خطای نحوی باشد، خطا برمیگرداند. این تابع تا زمانی اجرا میشود که به یک عدد نهایی منجر شود. سپس به صورت بازگشتی به توابع فراخوانی کنندهاش، نتیجه نهایی هر عبارت در هر مرحله را برمیگرداند[4]
private static double expressionValue() throws ParseError {
TextIO.skipBlanks();
if ( Character.isDigit(TextIO.peek()) ) {
return TextIO.getDouble();
}
else if ( TextIO.peek() == '(' ) {
TextIO.getAnyChar();
double leftVal = expressionValue();
char op = getOperator();
double rightVal = expressionValue();
TextIO.skipBlanks();
if ( TextIO.peek() != ')' ) {
throw new ParseError("Missing right parenthesis.");
}
TextIO.getAnyChar();
switch (op) {
case '+': return leftVal + rightVal;
case '-': return leftVal - rightVal;
case '*': return leftVal * rightVal;
case '/': return leftVal / rightVal;
default: return 0;
}
}
else {
throw new ParseError("Encountered unexpected character, \"" +
TextIO.peek() + "\" in input.");
}
}
پیادهسازی در پایتون
گرامر محاسبهگر روبرو نیز توسط تجزیهکننده کاهشی بازگشتی به زبان پایتون که در ادامه آمده، حل شدهاست.
exp ::= term | exp + term | exp - term
term ::= factor | factor * term | factor / term
factor ::= number | ( exp )
پیادهسازی در پایتون:[5]
class Calculator():
def __init__(self, tokens):
self._tokens = tokens
self._current = tokens[0]
def exp(self):
result = self.term()
while self._current in ('+', '-'):
if self._current == '+':
self.next()
result += self.term()
if self._current == '-':
self.next()
result -= self.term()
return result
def factor(self):
result = None
if self._current[0].isdigit() or self._current[-1].isdigit():
result = float(self._current)
self.next()
elif self._current is '(':
self.next()
result = self.exp()
self.next()
return result
def next(self):
self._tokens = self._tokens[1:]
self._current = self._tokens[0] if len(self._tokens)> 0 else None
def term(self):
result = self.factor()
while self._current in ('*', '/'):
if self._current == '*':
self.next()
result *= self.term()
if self._current == '/':
self.next()
result /= self.term()
return result
if __name__ == '__main__':
while True:
lst = list(raw_input('> ').replace(' ', ''))
tokens = []
for i in range(len(lst)):
if lst[i].isdigit() and i> 0 and (tokens[-1].isdigit() or tokens[-1][-1] is '.'):
tokens[-1] += lst[i]
elif lst[i] is '.' and i> 0 and tokens[-1].isdigit():
tokens[-1] += lst[i]
else:
tokens.append(lst[i])
print Calculator(tokens).exp()
جستارهای وابسته
منابع
- «Recursive descent parser».
- «A recursive descent parser for regex».
- «Introduction to Recursive Descent Parsing». بایگانیشده از اصلی در ۲۹ ژانویه ۲۰۱۸. دریافتشده در ۳۱ دسامبر ۲۰۱۷.
- «A Simple Recursive Descent Parser».
- «A simple python calculator».