معماری هاروارد
معماری هاروارد یک معماری کامپیوتر با جداسازی فیزیکی محل ذخیرهسازی و مسیر سیگنالها برای دستورالعملها و دادهها است. این واژه از کامپیوترrelay – based مبتنی بر Harvard Mark I یک گرفته شدهاست که دستورالعملها را در نوار پانچ (با عرض ۲۴ بیت) و دادهها را در شمارندههای الکترومکانیکی ذخیره میکند. در این ماشینهای اولیه محل ذخیرهسازی داده کاملاً در واحدپردازش مرکزی قرار دارد و نمیتوان از حافظه دستورالعمل برای ذخیرهسازی داده استفاده کرد و بالعکس. پردازنده نمیتواند برنامههایی را که باید توسط یک عملگر بارگذاری شوند را خودش مقداردهی اولیه کند.
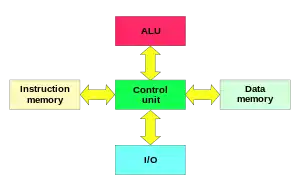
امروزه در بیشتر پیادهسازیهای پردازندهها به دلایل کارایی، چنین تفکیک مسیرسیگنالی وجود دارد، اما در واقع یک معماری هاروارد بهبودیافته پیادهسازی میشود؛ چون آنها میتوانند از اعمالی مانند بارگذاری یک برنامه از حافظه دیسک به عنوان داده و سپس اجرای آن پشتیبانی کنند.
جزئیات حافظه
در معماری هاروارد به ساختن دو حافظهای که ویژگیهای مشترکی دارند نیازی نیست. به خصوص عرض کلمه، زمانبندی، تکنولوژی پیادهسازی و ساختار آدرس دهی حافظه میتواند متفاوت باشد. در برخی سیستمها دستورالعملها میتواند در حافظهٔ فقط خواندنی ذخیره شود، درحالی که حافظه داده بهطور کلی نیازمند حافظهٔ خواندن– نوشتن است. در برخی سیستمها، حافظه دستورالعمل از حافظه داده بیشتر است؛ بنابراین آدرسهای دستورالعملها عرض بیشتری نسبت به آدرسهای داده دارند.
تفاوت معماری هاروارد با وان نیومن
در معماری خالص فون نیومن، CPU میتواند در حال خواندن یک دستورالعمل یا خواندن – نوشتن داده از حافظه یا در آن باشد. هر دوی اینها نمیتوانند در یک زمان اتفاق بیفتند چون دستورالعملها و دادهها از سیستم bus یکسانی استفاده میکنند. در یک کامپیوتر که از معماری هاروارد استفاده میکند، CPU بدون اینکه از حافظه cache استفاده کند، میتواند همزمان دو عمل خواندن دستورالعمل و دسترسی داشتن به یک داده حافظه را انجام دهد.[1] به این ترتیب با یک پیچیدگی مداری یکسان، کامپیوتری با معماری هاروارد میتواند سریع تر باشد؛ چون واکشی دستورالعملها و دسترسی داده به مسیر حافظهای یکسان نیاز ندارند.
همچنین ماشین با معماری هاروارد دارای فضای آدرس دهی داده و کد مجزایی است: آدرس صفر دستورالعمل با آدرس صفر داده یکسان نیست. ممکن است یک مقدار ۲۴ بیتی را مشخص کند، درحالیکه آدرس صفر داده ممکن است به یک بایت اشاره کند که قسمتی از آن مقدار ۲۴ بیتی نیست.
تفاوت معماری هاروارد با معماری هاروارد بهبود یافته
یک ماشین دارای معماری هاروارد بهبود یافته بسیار شبیه یک ماشین با معماری هاروارد است اما سختگیری آن برای تفکیک بین حافظه داده و دستورالعمل کمتر است. البته هنوز به CPU اجازهٔ دسترسی همزمان به دو Bus حافظه یا بیشتر داده میشود. بیشترین بهبود انجام شده شامل تفکیک cache داده و دستورالعمل با یک فضای آدرس مشترک است. هنگامی که CPU از cache اجرا میکند، به عنوان یک ماشین هاروارد خالص عمل میکند. وقتی که به حافظهٔ مرتبهٔ بالاتر دسترسی مییابد، شبیه یک ماشین فون نیومن عمل میکند (که کد میتواند مانند داده منتقل شوند، که یک تکنیک قوی است). این بهبود در پردازندههای مدرن به صورت گستردهای انجام شدهاست، مانند معماری ARM و پردازندههای x86. گاهی به صورت خلاصه معماری هاروارد بهبود یافته، معماری هاروارد گفته میشود.
بهبود دیگر در این معماری، ایجاد یک مسیر بین حافظه دستورالعمل (مثل ROM یا حافظه flash) و CPU که باعث میشود کلمههای حافظه دستورالعمل، به صورت دادهٔ فقط خواندنی عمل کنند. این روش در برخی میکروکنترلرها از جمله Atmel AVR استفاده شدهاست. این روش اجازه میدهد که دادههای ثابت مانند رشتههای متنی یا جدولهای تابعی، بدون داشتن کپی اولیه، برای جلوگیری از گرسنگی (و گرسنگی توان) دادههای حافظه برای متغیرهای خواندنی/ نوشتنی، درحافظهٔ اصلی در دسترس قرارگیرند زبانهای ماشین، دستورالعملهای خاصی دارند که داده را از حافظه دستورالعمل میخوانند. (این با دستورالعملهایی که خودشان دادهٔ ثابت نهفته هستند، فرق دارد، اگرچه برای ثابتهای مستقل، هردو مکانیزم برای یکدیگر قابل استفاده هستند)
سرعت
در سالهای اخیر، سرعت CPU در مقایسه با سرعت دسترسی به حافظه اصلی، رشد بسیاری داشتهاست. توجه شود که به منظور افزایش کارایی، تعداد دفعات دسترسی به حافظه اصلی کاهش یافتهاست. اگر برای مثال هر دستورالعمل که در CPU اجرا میشود نیازمند یک دسترسی به حافظه باشد، سرعت CPU زیاد نمیشود – مشکل محدودیت حافظه پدید میآید.
ممکن است بتوان حافظههای خیلی سریع ساخت اما با در نظر گرفتن ملاحظات قیمت، توان و مسیر یابی سیگنال فقط برای حافظههای با حجم کم امکانپذیر است. راه حل آن است که یک مقدار کم از حافظهٔ خیلی سریع که به آن CPU cache میگویند فراهم گردد و دادهای که اخیراً مورد دسترسی بوده را نگه میدارد. تا وقتی دادهای که CPU به آن نیاز دارد در cache باشد، کارایی بیشتر از زمانی است که cache آن داده را از حافظهٔ اصلی دریافت کند.
طراحی داخلی در برابر طراحی خارجی
تراشههای طراحی CPU مدرن، با کارایی بالا ویژگیهای معماری هاروارد و Harvard را با هم ترکیب میکنند. مخصوصاً ورژن چندبخشی کردن معماری بهبودیافتهٔ هاروارد بسیار متداول است. حافظهٔ cache CPU به cache دستورالعمل و cache داده تقسیم میشود. هنگامی که CPU به cache دسترسی پیدا میکند، معماری به صورت هاروارد است. معمولاً زمانی فقدان cache رخ میدهد و داده از حافظه اصلی گرفته میشود که به قسمتهای داده و دستورالعمل تقسیم نشود. اگرچه داشتن کنترل کنندههای جداگانهٔ حافظه برای دسترسی همزمان به ROM و (NOR) حافظه flash بهتر است.
بنابراین اگرچه در برخی contextها معماری فون نیومن آشکار است، اما مانند زمانی که داده و کد از یک کنترل کنندهٔ حافظه میآیند پیادهسازی سختافزاری به سودمندی معماری هاروارد برای دسترسی cache و کمینه کردن دسترسی به حافظه اصلی میرسد.
به علاوه، CPUها اغلب دارای بافرهای نوشتن هستند که این امکان را برای CPU فراهم میکند که بعد از نوشتن در ناحیهٔ غیرcache اقدام کنند. طبیعت حافظهٔ معماری فون نیومن وقتی آشکار میشود که دستورالعملها به عنوان داده توسط CPU نوشته میشوند و نرمافزار باید cache آن را تأمین نماید (cache داده و دستورالعمل) و بافر نوشتن قبل از اجرای اجرای دستورالعملهایی که اندکی بیش نوشته شدهاند، همگام سازی شود.
استفاده مدرن از معماری هاروارد
مزیت عمدهٔ معماری خام هاروارد، همزمان سازی دسترسی به بیش از یک حافظه سیستم است. زمان دسترسی به حافظهٔ به وسیلهٔ معماری بهبود یافته هاروارد، به وسیله سیستم cache CPU کاهش یافتهاست. اخیراً ماشینهای با معماری خام هاروارد در برنامههایی بیشتر استفاده میشوند که مصالحهٔ هزینه و صرفه جویی توان از حذف cache در آنها مطرح است؛ مهمتر از آن، جریمهٔ برنامهنویسی ناشی از تفکیک ویژگیهای کد و فضاهای آدرس دهی داده.
- پردازندههای سیگنال دیجیتال: معمولاً الگوریتمهای کوچک و بسیار بهینهسازی شدهٔ پردازش صوت یا ویدیو را اجرا میکند آنها از cache کردن اجتناب میکنند. چرا که رفتار آنها باید بسیار تجدید پذیر باشد. دشواری کپی کردن با چندین فضای آدرس دهی نگرانی دوم برای افزایش سرعت اجرا است؛ بنابراین برخی از DSPها چندین حافظهٔ داده را در یک فضای آدرس دهی قرار میدهند تا SLMD و VLIW را تسهیل کنند. برای مثال پردازندههای C55x ،Texas Instruments TMS320، چندین bus دادهٔ موازی (دو bus خواندنی، دو bus نوشتنی) و یکbus دستورالعمل را استفاده میکنند.
- میکروکنترلرها با داشتن مقدار کم حافظهٔ برنامه (حافظهٔ flash) و داده (SRAM) شناخته میشوند و از مزیت معماری هاروارد برای افزایش سرعت پردازش با همزمان سازی دسترسی به حافظه داده و دستورالعمل استفاده میکنند. محل ذخیرهسازی جدا به معنای این است که حافظهٔ داده و دستورالعملها ممکن است دارای عرض بیت مختلف باشند. مثلاً از دستورالعملهای ۱۶ بیتی و دادههای ۸ بیتی استفاده کنند. همچنین به این معناست که پیش واکشی دستورالعمل میتواند به صورت موازی با سایر فعالیتها انجام گیرد. مثلاً PIC توسط Microchip Technology Inc و AVR توسط Atmel crop (که در حال حاضر قسمتی کهMicrochip Technology است).
درهر کدام از این نمونهها، استفاده از دستورالعملهای خاص به منظور دسترسی به حافظهٔ برنامه رایج است. مانند آنکه از داده، برای جدولهای فقط خواندنی یا برنامهنویسی مجدد استفاده میشود. این پردازندهها، پردازندههای با معماری بهبود یافتهٔ هاروارد هستند.
منابع
- «vs. 030: the Crowded Fast Lan». "386. Dr. Dobb's Journal, January 1988.