حافظه نهان سیپییو
حافظه نهان CPU یا همان کش سی پی یو نوعی حافظهٔ سختافزاری است که توسط واحد پردازنده مرکزی کامپیوتر برای کاهش هزینه (زمان یا انرژی) میانگین دسترسی به دادهٔ حافظه اصلی استفاده میشود. در واقع کش یک حافظه کوچکتر و سریع تر است که در نزدیکی یک هستهٔ پردازنده قرار گرفتهاست و کپیهایی از دادههایی از مکانهای حافظه اصلی که مکرراً استفاده میشوند را ذخیره میکند. بیشتر CPUها دارای یک سلسله مراتب از چندین سطح حافظه نهان هستند(L1، L2، گاهی L3 و بندرت L4) هستند و در سطح یک، حافظههای نهان مخصوص-دستورالعمل و مخصوص-داده به صورت مجزا قرار دارند.
انواع دیگری از کشها وجود دارند (که جزو اندازهٔ کش مهمترین کشهای ذکر شده در بالا محسوب نمیشوند)، همچون بافر مرجع ترجمه (translation lookaside buffer) که بخشی از واحد مدیریت حافظه است که در بسیاری از CPUها وجود دارد. به TLB گاهی کش ترجمهٔ آدرس نیز میگویند.
مرور
زمانی که پردازنده سعی میکند تا یک مکان در حافظه اصلی را بخواند یا در یک مکان از حافظه اصلی بنویسد، اول چک میکند که آیا دادهٔ مربوط به مکان مورد نظر در حال حاضر در کش وجود دارد یا خیر. اگر وجود داشت، پردازنده از روی کش میخواند یا در آن مینویسد و به سراغ حافظه اصلی که بسیار کندتر است نمیرود.
اکثر پردازندههای جدید رومیزی یا سرور، حداقل دارای ۳ کش مستقل هستند: یک کش دستورالعمل برای سرعت بخشیدن به واکشی دستورالعمل فایل یا برنامهٔ قابل اجرا، یک کش داده برای سرعت بخشیدن به واکشی و ذخیرهٔ داده، و یک بافر مرجع برای ترجمه(translation lookaside buffer) که برای سرعت بخشیدن به ترجمهٔ آدرس مجازی به فیزیکی، هم برای دستورالعملهای فایل یا برنامهٔ قابل اجرا و هم برای داده استفاده میشود. میتوان فقط یک TLB برای دسترسی به دستورالعملها و داده فراهم کرد، یا اینکه دو TLB مجزا، یکی برای دستورالعمل (ITLB) و دیگری برای داده (DTLB) فراهم کرد. کش داده معمولاً به شکل سلسله مراتبی از سطوح بیشتر کش (L1، L2، و …) سازماندهی میشود. با این وجود، کش TLB جزئی از واحد مدیریت حافظه (MMU) است و مستقیماً به کشهای پردازنده مربوط نمیشود.
تاریخچه
تاریخچه اولیه فناوری کش تقریباً مصادف با ابداع و استفاده از حافظه مجازی است. به خاطر قیمت بالای نیمه رساناها در دهه ۱۹۶۰ کامپیوترها به سمت استفاده از حافظه مجازی سوق پیدا کردند. در روزهای اولیه سرعت دسترسی به حافظه تنها مقدار کمی با رجیستر فرق داشت ولی در دهه ۱۹۸۰ با ساخت پردازندههای پرسرعت شکاف سرعت بین پردازنده و حافظه بسیار بیشتر شد که این موضوع باعث پدید آمدن حافظههای میانی از جمله کش شد.
مدخلهای کش
داده بین حافظه و کش به شکل بلوکهایی با اندازه ثابت با نام خطوط کش یا بلوکهای کش جابجا میشود. زمانی که یک بلوک کش از حافظه به داخل کش کپی میشود، یک مدخل (entry) کش به وجود میآید. یک مدخل کش حاوی دادهٔ کپی شده و همچنین مکان حافظهٔ درخواستشده (تگ یا همان برچسب) است.
زمانی که پردازنده نیاز به خواندن یا نوشتن در مکانی از حافظه دارد، ابتدا یک مدخل مرتبط را در کش چک میکند. کش، محتویات مکان حافظهٔ مورد درخواست را در هر خط از کش که ممکن است حاوی آدرس مذکور باشد، چک میکند. اگر پردازنده دریابد که مکان مورد نظر حافظه در کش وجود دارد، آنگاه یک اصابت درست (cache hit) رخ میدهد. از سوی دیگر، اگر پردازنده مکان مورد نظر حافظه را در کش پیدا نکند، یک خطای کش (cache miss) رخ دادهاست. اگر اصابت درست رخ دهد، پردازنده بلافاصله دادهٔ موجود را در خطکش میخواند یا مینویسد. اگر یک خطای کش رخ دهد، کش مورد نظر، مدخل جدیدی را اختصاص میدهد و داده را از حافظهٔ اصلی در آن کپی میکند. سپس، درخواست مورد نظر با استفاده از محتویات کش برآورده میشود.
سیاستها
سیاستهای جایگزینی
هنگامی که یک خطای که رخ میدهد، کش مجبور است تا برای ایجاد فضا برای مدخل جدید یکی از مدخلهای موجود را اخراج کند. روشی را که کش برای انتخاب مدخل موردنظر برای اخراج انتخاب میکند، سیاست جایگزینی نام دارد. مسئله اساسی در رابطه با هر سیاست جایگزینی این است که کش باید پیشبینی کند که کدام مدخل موجود با احتمال کمتری در آینده استفاده خواهد شد. پیشبینی آینده دشوار است، بنابراین هیچ روش کاملی در بین انواع مختلف سیاستهای موجود وجود ندارد. یک سیاست جایگزینی رایج، ال از یو(least-recently used) نام دارد که به معنی موردی است که اخیراً کمتر از همه استفاده شدهاست و با استفاده از آن، مدخلی که اخیراً کمتر از همه مورد استفاده قرار گرفتهاست جایگزین میشود. با تبدیل برخی از محدودههای حافظه به شکل نواحی غیرقابل کش، میتوان با اجتناب از کش کردن بخشهایی از حافظه که به ندرت مجدداً استفاده میشوند، کارایی را بالا برد. این کار باعث اجتناب از بارگذاری چیزی به داخل کش میشود که مجدداً استفاده نخواهد شد. همچنین بسته به زمینه، مدخلهای کش ممکن است غیرفعال یا قفل شوند.
سیاستهای نوشتن
اگر دادهای در کش نوشته شود، بالاخره باید در حافظه اصلی نیز نوشته شود. زمانبندی این نوشتن، سیاست نوشتن نام دارد. در نوشتن فوری(write-through)، هر نوشتن در کش بلافاصله موجب نوشتن در حافظه اصلی میشود. از سوی دیگر، در کش نوع نوشتن تاخیری(write-back) یا همان کش نوع کپی تاخیری(copy-back)، نوشتنها بلافاصله در حافظه اصلی نمایان نمیشوند، بلکه کش مشخص میکند که در کدام مکانهای کش عمل نوشتن انجام شدهاست و آنها را برچسب کثیف میزند. دادهٔ موجود در این مکانها فقط زمانی در حافظه اصلی نوشته خواهد شد که از کش اخراج شود. به همین دلیل، یک خطای خواندن در یک کش از نوع نوشتن تأخیری، ممکن است گاهی نیازمند دو دسترسی به حافظه برای خدماتگیری باشد: اولی، برای نوشتن مکانهای کثیف در حافظه اصلی، و سپس دومی، برای خواندن مکان جدید از حافظه. همچنین نوشتن در یک مکان حافظه اصلی که هنوز در کش نقش بندی نشدهاست ممکن است باعث اخراج یک مکان هماکنون کثیف شود و بدین وسیله این فضای کش را برای مکان جدید حافظه خالی کند.
سیاستهای بینابینی نیز وجود دارند. کش مورد نظر ممکن است از نوع نوشتن فوری باشد اما نوشتنها ممکن است بهطور موقت در یک صف ذخیرهسازی داده نگه داشته شوند معمولاً با این هدف که چندین ذخیره را بتوان با یکدیگر پردازش کرد (میتواند منجر به کاهش زمانهای گردش گذرگاه و بهبود بهره بری از گذرگاه شود).
دادههای کش شده از حافظه اصلی ممکن است توسط ماهیتهای دیگر تغییر پیدا کنند (مثلاً ابزارهای جانبی با استفاده از دسترسی مستقیم به حافظه یا هستههای دیگر در یک پردازنده چند هسته ای)؛ در این حالت کپی موجود در کش ممکن است به روز نباشد یا اصطلاحاً قدیمی شود. در حالت دیگر، زمانی که یک پردازنده اصلی در یک سیستم چند پردازنده ای داده موجود در کش را به روز میکند، کپیهای داده در کشهای مربوط به پردازندههای دیگر قدیمی میشود. پروتکلهای ارتباط بین مدیرهای کش که موجب ثبات داده میشوند را اصطلاحاً پروتکلهای یکپارچگی کش مینامند.
عملکرد کش
روشهای اندازهگیری عملکرد کش در سالهای اخیر اهمیت پیدا کردهاست زیرا خلأ سرعت بین عملکرد حافظه و عملکرد پردازنده بهطور تصاعدی در حال افزایش است. کش برای کاهش این خلأ سرعت ارائه شد؛ لذا دانستن اینکه چگونه و تا چه حدی کش میتواند این خلاء بین سرعت پردازنده و حافظه را، خصوصاً در سیستمهای دارای کارایی بالا پر کند اهمیت پیدا کردهاست. مقدار اصابت درست در کش و مقدار خطای کش نقش مهمی در تعیین این کارایی ایفا میکند. برای بهبود کارایی کش کاهش نرخ خطا یکی از قدمهای اساسی است. همچنین کاهش زمان دسترسی به کش نیز باعث افزایش کارایی میشود.
معطلیهای پردازنده
زمان لازم برای واکشی یک خطکش از حافظه (تأخیر خواندن ناشی از یک خطای کش) اهمیت دارد زیرا پردازنده در هنگامی که منتظر یک خطکش است، کاری برای انجام دادن ندارد. زمانی که پردازنده در این وضعیت قرار میگیرد اصطلاحاً میگوییم که دچار معطلی(stall) شدهاست. از آنجایی که پردازندهها در مقایسه با حافظه اصلی سریعتر شدهاند، معطلیهای ناشی از خطای کش موجب از دست رفتن پردازشهای بالقوه بیشتری میشود. پردازندههای جدید میتوانند صدها دستورالعمل را در فاصله زمانی واکشی فقط یک خطکش از حافظه اصلی انجام دهند.
تکنیکهای مختلفی به کار گرفته شده تا در طی این زمان پردازنده را مشغول نگه دارد، از جمله اجرای خارج از نوبت که در آن پردازنده تلاش میکند تا بعد از اینکه دستورالعملی که منتظر کش است داده را از دست میدهد، دستورالعملهای مستقلی را اجرا کند. تکنولوژی دیگر که توسط بسیاری از پردازندهها استفاده میشود، چند ریسه ای همزمان است که در آن به ریسه دیگر اجازه داده میشود تا در زمانی که ریسه اول منتظر منابع مورد نیاز پردازنده است، از هسته پردازنده استفاده کند.
جزییات کار
وقتی پردازنده نیاز دارد که دادهای را بخواند یا بنویسد ابتدا چک میکند که در کش موجود است یا نه، این کار به وسیله مقایسه آدرس مکان حافظه با همه تگهای موجود در کش که ممکن است حاوی آدرس باشد صورت میپذیرد. اگر پردازنده آدرس مکان مورد نظر حافظه را در کش بیابد میگوییم که یک برخورد کش رخ داده در غیر این صورت گوییم که یک خطای کش روی دادهاست. در صورت برخورد پردازنده به سرعت دادهها را از خطکش میخواند یا مینویسد. نسبتی از دسترسیها که منجر به برخورد میشود را نرخ برخورد گویند و مقیاسی است برای اندازهگیری کارایی یک الگوریتم یا برنامه. در صورت بروز خطا کش مدخلی دیگر را در نظر میگیرد. اگر دادهای در کش نوشته شود باید در حافظه اصلی نیز نوشته شود. زمان این نگارش به وسیله سیاست نگارش کنترل میشود.[1]
مرتبط سازی
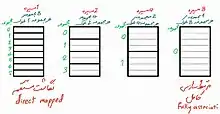
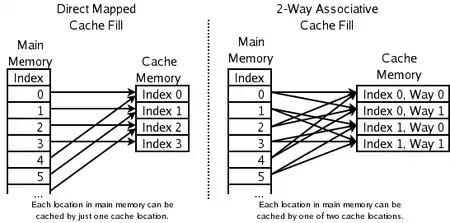
سیاست قراردهی مشخص میکند که یک کپی از یک مدخل خاص از حافظه اصلی درکجای کش باید قرار گیرد. اگر سیاست قرار دهی آزاد باشد تا برای نگه داشتن کپی هر مدخلی از کش را انتخاب کند، آنگاه مثلاً گفته میشود که کش مرتبط سازی کامل(fully associative) است. از سوی دیگر، اگر هر مدخل در حافظه اصلی بتواند فقط در یک مکان از کش برود آن گاه گفته میشود که کش دارای نگاشت مستقیم است. بسیاری از کشها روش بینابینی را انتخاب میکنند که در آن هر مدخل در حافظه اصلی میتواند به هر کدام از N مکان موجود در کش برود و به این روش نگاشت مجموعه N سویه گویند.[3] برای مثال کش داده سطح-یک در AMD Athlon در واقع یک کش نگاشت مجموعه دو سویه است به این معنی که هر مکان خاص در حافظه اصلی در هر یک از دو مکان موجود در کش داده سطح یک میتوانند کش شوند.
انتخاب تعداد درست میزان مرتبط سازی مستلزم یک سبکسنگین کردن است. اگر ده مکان وجود داشته باشد که سیاست قرار دهی بتواند یک مکان حافظه را در آنها نگاشت کند آنگاه برای اینکه ببینیم آیا مکان مذکور در کش قرار دارد یا خیر، باید در بین ده مدخل کش جستجو کنیم. جستجو کردن مکانهای بیشتر به معنی مصرف انرژی بیشتر و مساحت چیپ بیشتر و بهطور بالقوه زمان بیشتر است. از سوی دیگر، کشهایی که دارای ارتباط بیشتری هستند دچار خطای کمتری میشوند بگونهای که پردازنده زمان کمتری را برای خواندن از حافظه اصلی که کندتر است تلف میکند. دستورالعمل کلی این است که دو برابر کردن میزان ارتباط از نگاشت مستقیم به مجموعه دو سویه یا از مجموعه دو سویه به مجموعه چهار سویه تقریباً اثری مشابه با دو برابر کردن اندازه کش روی افزایش میزان اصابت صحیح دارد. با این حال افزایش دادن ارتباط به بیش از مجموعههای چهار سویه چندان باعث افزایش میزان اصابتهای صحیح نمیشود[4] و بهطور کلی به دلایل دیگر انجام میشود. برخی پردازندهها میتوانند به صورت پویا میزان ارتباط کشهای خود را در وضعیتهای کم مصرف کاهش دهند که روشی برای کاهش مصرف انرژی است.[5]
در زیر به ترتیب بدترین و سادهترین تا بهترین و پیچیدهترین آمدهاست:
- کش دارای نگاشت مستقیم- دارای زمان بهترین حالت خوب اما در بدترین حالت غیرقابل پیشبینی است.
- کش ارتباطی مجموعههای ۲ سویه
- کش ارتباطی مجموعههای ۲ سویه متمایل شده[6]
- کش ارتباطی مجموعههای ۴ سویه
- کش ارتباطی مجموعههای ۸ سویه - یک انتخاب رایج برای پیادهسازیهای بعدی
- کش ارتباطی مجموعههای ۱۲ سویه- مشابه با ۸ سویه
- کش مرتبط سازی کامل- بهترین نرخ خطا اما فقط برای تعداد محدودی از مدخلها عملی است.
کش با نگاشت مستقیم
در این سازماندهی کش، هر مکان در حافظه اصلی میتواند فقط به یک مدخل در کش برود بنابراین یک کش دارای نگاشت مستقیم را میتوان یک کش ارتباطی تک سویه نیز نامید. این روش به معنی دقیق کلمه فاقد سیاست قراردهی است زیرا هیچگونه انتخابی در رابطه با محتویات مدخلی از کش که باید بیرون شود وجود ندارد. این بدان معنی است که اگر دو مکان در یک مدخل نگاشت شوند ممکن است به صورت مداوم یکدیگر را بیرون اندازند. اگرچه یک کش دارای نگاشت مستقیم سادهتر است اما باید نسبت به یک کش ارتباطی خیلی بزرگتر باشد تا بتواند کارایی مشابهی داشته باشد و همچنین نوع کش غیرقابل پیشبینی تر است. فرض کنید x شماره بلاک در کش است و y شماره بلاک در حافظه باشد و n تعداد بلاکها در کش باشد، آنگاه عمل نگاشت با کمک معادله x = y mod n انجام میشود.
کش ارتباطی مجموعههای دو سویه
اگر هر مکان در حافظه اصلی را بتوان در یکی از دو مکان در کش نگاشت کرد آنگاه سؤال منطقی این است که: کدام یک از این دو باید انتخاب شود؟ سادهترین و رایجترین طرح مورد استفاده که در دیاگرام سمت راست در بالا نشان داده شدهاست استفاده از کم ارزشترین بیتهای اندکس مکان حافظه به عنوان اندکس برای حافظه کش میباشد و اینکه برای هر اندکس دو مدخل داشته باشیم. یک مزیت این طرح این است که برچسبهای ذخیره شده در کش لازم نیست تا دربرگیرنده آن بخشی از آدرس حافظه اصلی که توسط اندکس حافظه کش به صورت غیر مستقیم مشخص میشود باشند. از آن جایی که برچسبهای کش بیتهای کمتری دارند بنابراین نیازمند ترانزیستورهای کمتری هستند، فضای کمتری در برد مدار پردازنده یا چیپ ریزپردازنده میگیرند و قابل خواندن و مقایسه به صورت سریع تر هستند. همچنین LRU نیز مخصوصاً ساده میشود زیرا فقط لازم است تا یک بیت به ازای هر جفت ذخیره شود.
اجرای حدسی
یکی از مزایای کش نگاشت مستقیم این است که امکان گمانه زنی ساده و سریع را فراهم میکند. هنگامی که آدرس مورد نظر محاسبه شد آنگاه اندکسی از کش که ممکن است حاوی کپی آن مکان حافظه باشد مشخص است. این مدخل کش را میتوان خواند و پردازنده قبل از اینکه بهطور کامل چک کند آیا برچسب مورد نظر واقعاً با آدرس درخواست شده همخوانی دارد میتواند با داده مورد نظر کارش را ادامه دهد.
ایده اینکه پردازنده قبل از اینکه چککردن همخوانی برچسب تمام شود، از دادهٔ کش شده استفاده کند را میتوان در طرحهای ارتباطی نیز به کار برد. یک زیر مجموعه از برچسب به نام اشاره (hint) را میتوان برای انتخاب فقط یکی از مدخلهای احتمالی کش نگاشت شده در آدرس مورد درخواست استفاده کرد. سپس میتوان از مدخل انتخاب شده توسط اشاره به صورت موازی با چک کردن تگ کامل استفاده کرد. تکنیک اشاره زمانی که در زمینه ترجمه آدرس استفاده میشود بهترین نتیجه را میدهد.
کشش ارتباطی دو سویه متمایل شده
طرحهای دیگری نیز پیشنهاد شدهاند نظیر کش متمایل که در آن همانند بالا اندکس برای مسیر صفر مستقیم است اما اندکس برای مسیر یک، به وسیلهٔ یک تابع درهم سازی شکل میگیرد. یک تابع درهم سازی خوب این ویژگی را دارد که آدرسهایی که با نگاشت مستقیم با هم تداخل پیدا میکنند، زمانی که با تابع درهم سازی نگاشت میشوند دیگر تمایلی به تداخل ندارند و بنابراین این احتمال خیلی کمتر است که یک برنامه دچار حجم قابل پیشبینی زیادی از خطاهای تداخلی ناشی از الگوهای دسترسی معیوب شود. البته مشکل این روش این است که تأخیر بیشتری به خاطر محاسبه تابع درهم سازی وجود دارد. علاوه بر این زمانی که وقت آن میرسد که یک خط جدید بارگذاری شود و یک خط قدیمی خارج گردد ممکن است دشوار باشد تا مشخص کنیم که کدام خط موجود اخیراً کمترین استفاده را داشته، زیرا خط جدید با دادهٔ موجود در اندیسهای متفاوت در هر مسیر تداخل پیدا میکند. پیگیری LRU برای کشهای بدون تمایل معمولاً بر یک اساس به-ازای-هر-مجموعه انجام میگیرد. با این وجود کشهای ارتباطی متمایل در مقایسه با کشهای ارتباطی مجموعه ای مرسوم برتری خیلی بالاتری دارند.
کشهای ارتباطی کاذب
یک کش ارتباطی مجموعه ای واقعی همه مسیرهای احتمالی را به صورت همزمان چک میکند و برای این کار از یک چیزی شبیه حافظه محتوای-قابل-آدرس دهی استفاده میکند. یک کش ارتباطی کاذب در هر لحظه یک مسیر احتمالی را به صورت جداگانه تست میکند. یک کش درهم سازی-دوباره درهم سازی و کش ارتباطی ستونی مثالهایی از کش ارتباطی کاذب هستند.
در حالت شایع یک اصابت صحیح در اولین مسیر تست شده، یک کش ارتباطی کاذب به اندازه یک کش نگاشت مستقیم سریع است، اما در مقایسه با یک کش نگاشت مستقیم میزان خطای تداخلی بسیار کمتری دارد که تقریباً برابر با میزان خطای یک کش کاملاً ارتباطی است.
ساختار مدخل کش
مدخلهای ردیفهای کش معمولاً ساختار زیر را دارند:
| tag | data block | flag bits |
قطعهٔ داده (خطکش) حاوی داده واقعی واکشی شده از حافظه اصلی است. قسمت برچسب حاوی (بخشی از) آدرس داده واقعی واکشی شده از حافظه اصلی است. اندازه کش در واقع همان مقدار دادهٔ حافظه اصلی است که میتواند نگه دارد. این اندازه را میتوان از طریق ضرب تعداد بایتهای ذخیره شده در هر قطعهٔ داده در تعداد قطعات ذخیره شده در کش محاسبه کرد (بیتهای برچسب، فلگ و کد تصحیح خطا در اندازه لحاظ نمیشوند[8] اگرچه روی مساحت فیزیکی کش تأثیرگذار هستند). یک آدرس مؤثر حافظه که همراه با خطکش (قطعهٔ حافظه) است به قسمتهای زیر تقسیم میشود: به ترتیب از با ارزشترین بیتها تا کم ارزشترین بیتها: برچسب، اندکس و جابجایی (آفست) قطعه.[9][10]
| tag | index | block offset |
اندیس نشان میدهد که داده در کدام مجموعه کش قرار گرفتهاست. اگر تعداد مجموعهای کش برابر s باشد آنگاه طول اندیس برابر است.

جابجایی قطعه مشخص کننده داده دلخواه در داخل قطعهٔ داده ذخیره شده در داخل ردیف کش است. بهطور معمول اندازه آدرس مؤثر بر حسب بایت است به گونهای که طول جابجایی قطعه برابر بیت است که در آن b تعداد بایتها به ازای هر قطعه دادهاست.

برچسب، حاوی با ارزشترین بیتهای آدرس است که با تمام ردیفهای موجود در مجموعه کنونی (مجموعه ای که توسط اندیس استخراج شدهاست) مقایسه میشود تا مشخص شود آیا مجموعه مذکور حاوی آدرس درخواست شده هست یا خیر. اگر چنین باشد یک اصابت درست کش رخ میدهد. طول برچسب بر حسب بیت به شکل زیر محاسبه میشود:
tag_length = address_length - index_length - block_offset_length
برخی نویسندگان برای آفست قطعه فقط اصطلاح آفست[11] یا جابجایی را به کار میبرند.[12][13]
مثال
پردازنده پنتیوم ۴ اولیه دارای یک کش دادهٔ L1 ارتباطی مجموعه ۴ مسیره با اندازه ۸ کیبی بایت بود، که اندازهٔ بلاکهای کش آن برابر ۶۴ بایت بود. از این رو تعداد بلاکهای کش برابر
8 KiB / 64 = 128
بود. تعداد مجموعهها برابر با تعداد بلاکها تقسیم بر تعداد مسیرهای ارتباطی است که برابر است با
128 / 4 = 32
مجموعه و از این رو
25 = 32
اندیس مختلف.
26 = 64
آفست ممکن وجود داشت. از آنجایی که طول آدرس پردازنده برابر با ۳۲ بیت بود در نتیجه اندازه فضای تگ برابر با
32 - 5 - 6 = 21
بیت بود.
پردازنده اینتل پنتیوم ۴ همچنین دارای یک کش مجتمع سطح دو ارتباطی مجموعه ۸ مسیره با اندازه
256 KiB
بود که اندازهٔ بلاکهای کش آن برابر ۱۲۸ بایت بود. این به معنی است که
32 - 8 - 7 = 17
بیت برای فضای برچسب باقی میماند.[11]
بیتهای پرچم
یک کش دستورالعمل فقط به یک بیت پرچم (فلگ) در هر مدخل ردیف کش نیاز دارد: بیت معتبر. بیت معتبر نشان میدهد که آیا بلوک کش با دادهٔ معتبر بارگیری شدهاست یا خیر.
هنگام روشن شدن، سختافزار تمام بیتهای معتبر را در تمام کشها روی «نامعتبر» تنظیم میکند. برخی از سیستمها بیت معتبر را در زمانهای دیگری نیز روی «نامعتبر» تنظیم میکنند، مانند زمانی که سختافزار نظارت گذرگاه چند رئیسه در کش یک پردازنده، یک مخابرهٔ آدرس را از پردازنده دیگری میشنود و متوجه میشود که برخی از قطعههای داده در کش محلی مذکور اکنون کهنه است و باید نامعتبر شود.
کش داده معمولاً به دو بیت فلگ در هر خطکش نیاز دارد - یک بیت معتبر و یک بیت کثیف. اگر بیت کثیف ست شده باشد، به این معنی است که خطکش مربوطه از زمان خواندن از حافظه اصلی ("کثیف شده") تغییر کردهاست، به این معنی که پردازنده دادههایی را در آن خط نوشتهاست و مقدار جدید هنوز در حافظه اصلی کپی نشدهاست.
خطای کش
خطای کش، تلاشی ناموفق برای خواندن یا نوشتن قطعه ای از داده در حافظه نهان است، که منجر به دسترسی به حافظه اصلی با تأخیر بسیار طولانیتر میشود. سه نوع از خطای حافظه پنهان وجود دارد: خطای خواندن دستورالعمل، خطای خواندن داده، و خطای نوشتن داده.
خطاهای خواندن کش از یک کش دستورالعمل، بیشترین تأخیر را به وجود میآورد، زیرا پردازنده یا حداقل ریسهٔ اجرا باید منتظر بماند (متوقف شود) تا دستورالعمل از حافظه اصلی واکشی شود. خطاهای خواندن کش از یک کش داده معمولاً تأخیر کمتری ایجاد میکند، زیرا دستورالعملهایی که به حافظه نهان وابسته نیستند، میتوانند آغاز شوند و تا زمانی که داده از حافظه اصلی برگردد، اجرا شوند و پس از بازگشت داده، اجرای دستورالعملهای وابسته از سر گرفته میشود. خطاهای نوشتن کش در کش داده بهطور کلی باعث کمترین تأخیر میشود، زیرا نوشتن میتواند در صف قرار گیرد و محدودیتهای کمی در اجرای دستورالعملهای بعدی وجود دارد؛ پردازنده میتواند تا زمان پر شدن صف ادامه دهد.
ترجمه آدرس
بیشتر پردازندههای دارای کاربرد عمومی نوعی حافظه مجازی را پیادهسازی میکنند. بهطور خلاصه، یا هر برنامه ای که روی دستگاه در حال اجرا است فضای آدرس ساده شده خود را که حاوی کد و داده مخصوص آن است، میبیند یا اینکه، همه برنامهها در یک فضای آدرس مجازی مشترک اجرا میشوند. یک برنامه با محاسبه، مقایسه، خواندن و نوشتن در آدرسهای فضای آدرس مجازی خود، به جای آدرسهای فضای آدرس فیزیکی، اجرا میشود و بدین گونه، برنامهها سادهتر میشوند و در نتیجه نوشتن آنها آسانتر است.
در حافظه مجازی، پردازنده موظف است تا آدرسهای مجازی تولید شده توسط برنامه را به آدرسهای فیزیکی حافظه اصلی ترجمه کند. بخشی از پردازنده که این ترجمه را انجام میدهد به عنوان واحد مدیریت حافظه (MMU) شناخته میشود. مسیر سریع از طریق MMU میتواند ترجمههایی را که در کش ترجمه آدرس (Translation lookaside buffer) ذخیره شدهاند، انجام دهد. TLB نوعی کش برای نگاشتها از جدول صفحهٔ سیستم عامل، جدول سگمان یا هر دو است.
با هدف بحث حاضر، سه ویژگی مهم در ترجمه آدرس وجود دارد:
- تأخیر(latency): بعد از اینکه آدرس مجازی از طریق تولیدکننده آدرس موجود شد، آدرس فیزیکی بعد از مدتی، شاید چند چرخه، توسط MMU در دسترس قرار میگیرد.
- مستعار(Aliasing): چندین آدرس مجازی میتوانند در یک آدرس فیزیکی نگاشت شوند. اکثر پردازندهها تضمین میکنند که تمام به روزرسانیهای این آدرس فیزیکی به ترتیب موجود در برنامه انجام میشود. برای ارائه این ضمانت ، پردازنده باید اطمینان حاصل کند که فقط یک نسخه از آدرس فیزیکی در هر زمان مشخص در حافظه پنهان قرار دارد.
- دانهدانه بودن(granularity): فضای آدرس مجازی به صفحات تقسیم میشود. به عنوان مثال، یک فضای آدرس مجازی ۴ گیبی بایتی ممکن است در ۱۰۴۸۵۷۶ صفحه با اندازه ۴ خیلی بایت تقسیم شود، که هر یک از آنها میتواند بهطور مستقل نگاشت شود. ممکن است اندازههای متعددی از صفحه پشتیبانی شود.
برخی از سیستمهای حافظه مجازی اولیه بسیار کند بودند زیرا نیاز به دسترسی به جدول صفحه (در حافظه اصلی) قبل از دسترسی برنامهنویسی شده به حافظه اصلی داشتند.
بدون داشتن حافظه نهان، این امر بهطور مؤثر سرعت دسترسی به حافظه را به نصف کاهش میدهد. اولین حافظه نهان سختافزاری مورد استفاده در سیستم رایانه ای در واقع حافظه نهان داده یا دستورالعمل نبود، بلکه TLB بود.
بر اساس اینکه اندیس یا برچسب با آدرس فیزیکی یا مجازی مطابقت دارد، حافظه پنهان را میتوان به چهار نوع تقسیم کرد:
کش از نوع فیزیکی فهرست شده و فیزیکی برچسب گذاری شده (Physically indexed, physically tagged) از آدرس فیزیکی هم برای اندیس و هم برای برچسب استفاده میکنند. اگرچه این کار ساده است و از مشکلات نام مستعار جلوگیری میکند، اما کند است، زیرا قبل از جستجوی آدرس در حافظه کش، باید آدرس فیزیکی را جستجو کرد (که میتواند شامل خطای TLB و دسترسی به حافظه اصلی باشد).
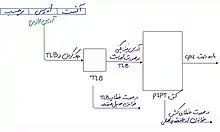
کش از نوع مجازی فهرست شده و مجازی برچسب گذاری شده (Virtually indexed, virtually tagged) از آدرس مجازی هم برای فهرست و هم برای برچسب استفاده میکند. این طرح کش میتواند به جستجوی سریعتر منجر شود، زیرا در ابتدا برای تعیین آدرس فیزیکی یک آدرس مجازی داده شده نیازی به مراجعه به MMU نیست. با این حال، VIVT از مشکلات نام مستعار رنج میبرد، جایی که چندین آدرس مجازی مختلف ممکن است به یک آدرس فیزیکی ارجاع کنند. نتیجه این است که این آدرسها علیرغم ارجاع به یک حافظه یکسان، جداگانه کش میشوند و باعث ایجاد مشکلات یکپارچگی میشوند. اگرچه راه حلهایی برای این مشکل وجود دارد[14] اما آنها برای پروتکلهای یکپارچگی استاندارد کارایی ندارند. مشکل دیگر تشابه ظاهری(homonyms) است، جایی که یک آدرس مجازی به چندین آدرس فیزیکی مختلف نگاشت میشود. تشخیص این نگاشتها صرفاً با مشاهده اندیس مجازی بتنهایی امکانپذیر نیست، گرچه راه حلهای بالقوه عبارتند از: شستشوی حافظه پنهان پس از تعویضی زمینه، الزام کردن فضاهای آدرس به ناهمپوشانی، برچسب زدن آدرس مجازی با شناسه فضای آدرس (address space ID). علاوه بر این، یک مشکل وجود دارد که نگاشتهای مجازی به فیزیکی میتوانند تغییر کنند، که به شستشوی خطوط کش نیاز دارد، زیرا VAها دیگر معتبر نیستند. اگر برچسبها از آدرسهای فیزیکی (VIPT) استفاده کنند، همه این مشکلات حذف میشوند.
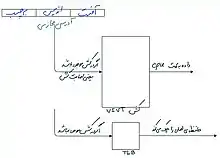
کش از نوع مجازی فهرست شده، و فیزیکی برچسب گذاری شده (VIPT) از آدرس مجازی برای فهرست بندی و آدرس فیزیکی موجود برای برچسب استفاده میکند. مزیت آن نسبت به PIPT تأخیر کمتر است، زیرا میتوان بهطور همزمان با ترجمه TLB، خطکش را جستجو کرد، اما تا زمانی که آدرس فیزیکی در دسترس نباشد، برچسب قابل مقایسه نیست. مزیت نسبت به VIVT این است که از آنجا که برچسب آدرس فیزیکی دارد، حافظه پنهان میتواند مشابهات را تشخیص دهد. از نظر تئوری، VIPT نیاز به بیت بیشتری برای برچسب دارد زیرا برخی از بیتهای اندیس میتوانند بین آدرسهای مجازی و فیزیکی متفاوت باشند (به عنوان مثال بیت ۱۲ به بالا برای صفحه 4KiB) و باید هم در اندیس مجازی و هم در برچسب فیزیکی گنجانده شود. در عمل این مشکل ساز نیست، زیرا برای جلوگیری از مشکلات یکپارچگی، کشهای VIPT طوری طراحی شدهاند که چنین بیتهای فهرستی ندارند (به عنوان مثال، با محدود کردن تعداد کل بیتهای فهرست و جابجایی بلوک به ۱۲ برای صفحات 4KiB)؛ این امر باعث میشود تا اندازه حافظه پنهان VIPT حداکثر برابر با اندازه صفحه ضرب در میزان ارتباط حافظه پنهان شود.
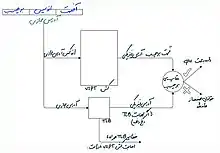
کش از نوع به طریق فیزیکی فهرست شده و به طریق مجازی برچسب گذاری شده (PIVT) اغلب در متون ادعا میشود که بی فایده و غیر موجود است.[15] با این حال، MIPS R6000 از این نوع حافظه پنهان به عنوان تنها پیادهسازی شناخته شده استفاده میکند.[16] R6000 به شکل منطق تزویج امیتری پیادهسازی شدهاست، که یک فناوری بسیار سریع است و برای حافظههای بزرگ مانند TLB مناسب نیست. R6000 با قرار دادن حافظه TLB در یک قسمت اختصاصی از حافظه نهان سطح دو، با داشتن یک «برش» TLB کوچک و با سرعت بالا روی چیپ، این مسئله را حل میکند. حافظه نهان با آدرس فیزیکی بدست آمده از برش TLB فهرست بندی میشود. با این حال، از آنجا که قطعه TLB فقط آن دسته از بیتهای آدرس مجازی را که برای فهرست بندی حافظه پنهان ضروری هستند ترجمه میکند و از هیچ برچسبی استفاده نمیکند، ممکن است اصابتهای کاذب در حافظه پنهانی رخ دهد که با برچسب گذاری با آدرس مجازی برطرف میشود.
سرعت این رویداد مجدد (تأخیر بار) برای عملکرد پردازنده بسیار مهم است و بنابراین اکثر کشهای سطح ۱ جدید بطریق مجازی فهرست بندی میشوند، که حداقل این امکان را میدهد تا جستجو در TLB واحد مدیریت حافظه به موازات واکشی داده از RAM کش پیش برود.
اما فهرست بندی مجازی برای همه سطوح حافظه نهان بهترین گزینه نیست. هزینه مدیریت مستعارهای مجازی با افزایش اندازه حافظه نهان افزایش مییابد و در نتیجه بیشتر کشهای سطح ۲ و بالاتر بطریق فیزیکی فهرست بندی میشوند.
از زمانهای گذشته، حافظه نهان هم از آدرسهای مجازی و هم از آدرسهای فیزیکی برای برچسبهای کش استفاده میکرد، اگرچه برچسب گذاری مجازی اکنون غیرمعمول است. اگر جستجوی TLB بتواند قبل از جستجوی RAM کش به پایان برسد، آنگاه آدرس فیزیکی به موقع برای مقایسه برچسب در دسترس است و نیازی به برچسب گذاری مجازی نیست؛ بنابراین، معمولاً حافظههای نهان بزرگ بهطور فیزیکی برچسب گذاری میشوند و فقط حافظههای نهان کوچک، با تأخیر بسیار کم، بهطور مجازی برچسب گذاری میشوند. در پردازندههای عمومی جدید، vhints جایگزین برچسب گذاری مجازی شدهاست.
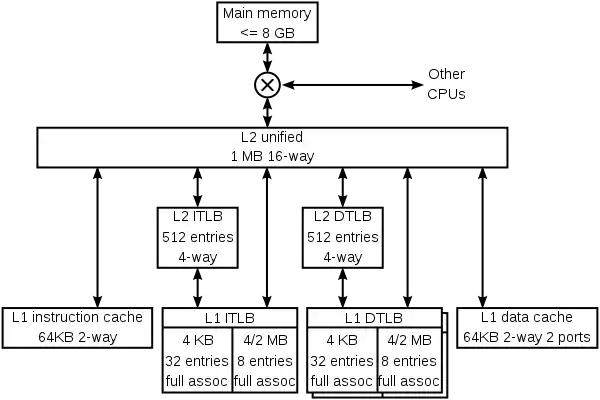
سلسله مراتب کش در یک پردازنده مدرن
پردازندههای مدرن کشهای زیادی روی یک چیپ دارند.
کشهای اختصاصی
پردازندههای لولهکشی شده از طریق نقاط مختلف روی لولهکشی به حافظه دسترسی دارند. این پردازندهها از الگوریتم فون نیومن برای عمل استفاده میکنند که در هر یک از پنج مرحله یک کش اختصاصی دارند.
کش قربانی
کش قربانی کشی است که بلوکهایی که توسط پردازنده واکشی شدهاند را نگه میدارد.
کش تریس
کشی است که در پنتیوم۴ برای افزایش پهنای باند واکشی دستورها و کاهش مصرف انرژی مورد استفاده قرار گرفت.
کشهای چند سطحی
مسئله دیگر ایجاد توازن بین تأخیر کش و نرخ برخورد آن است. کشهای بزرگتر دارای نرخ برخورد بیشتر هستند ولی تأخیر بیشتری نیز دارند. به همین خاطر اکثر کامیپوترهای امروزی از چند سطح کش استفاده میکنند که در آن کشهای کوچک و سریع به وسیله کشهای بزرگتر ولی کندتر پشتیبانی میشوند.
منابع
- TMS320C66x DSP Cache User Guide (PDF), Texas Instruments, November 2010, p. 1-5
- Gupta, Ankur (Feb 13, 2018). "Cache Organization Set 1 (Introduction)". geeksforgeeks. Retrieved May 13, 2021.
- "Cache design" (PDF). ucsd.edu. 2010-12-02. p. 10–15. Retrieved 2014-02-24.
- IEEE Xplore - Phased set associative cache design for reduced power consumption. Ieeexplore.ieee.org (2009-08-11). Retrieved on 2013-07-30.
- Sanjeev Jahagirdar; Varghese George; Inder Sodhi; Ryan Wells (2012). "Power Management of the Third Generation Intel Core Micro Architecture formerly codenamed Ivy Bridge" (PDF). hotchips.org. p. 18. Retrieved 2015-12-16.
- André Seznec (1993). "A Case for Two-Way Skewed-Associative Caches". ACM SIGARCH Computer Architecture News. 21 (2): 169–178. doi:10.1145/173682.165152.
- Patterson, David (2012). Computer Organization and Design. Elsevier, Inc. p. 459. doi:10.1016/B978-0-12-374750-1.00005-0/. ISBN 978-0-12-374750-1.
- Nathan N. Sadler; Daniel J. Sorin (2006). "Choosing an Error Protection Scheme for a Microprocessor's L1 Data Cache" (PDF). p. 4.
- John L. Hennessy; David A. Patterson (2011). Computer Architecture: A Quantitative Approach. p. B-9. ISBN 978-0-12-383872-8.
- David A. Patterson; John L. Hennessy (2009). Computer Organization and Design: The Hardware/Software Interface. p. 484. ISBN 978-0-12-374493-7.
- Gene Cooperman (2003). "Cache Basics".
- Ben Dugan (2002). "Concerning Cache".
- Harvey G. Cragon. "Memory systems and pipelined processors". 1996. شابک ۰−۸۶۷۲۰−۴۷۴−۵ , شابک ۹۷۸−۰−۸۶۷۲۰−۴۷۴−۲ . "Chapter 4.1: Cache Addressing, Virtual or Real" p. 209
- Kaxiras, Stefanos; Ros, Alberto (2013). A New Perspective for Efficient Virtual-Cache Coherence. 40th International Symposium on Computer Architecture (ISCA). pp. 535–547. CiteSeerX 10.1.1.307.9125. doi:10.1145/2485922.2485968. ISBN 978-1-4503-2079-5. S2CID 15434231.
- "Understanding Caching". Linux Journal. Retrieved 2010-05-02.
- Taylor, George; Davies, Peter; Farmwald, Michael (1990). "The TLB Slice - A Low-Cost High-Speed Address Translation Mechanism". CH2887-8/90/0000/0355$01.OO.
مشارکتکنندگان ویکیپدیا. «CPU cache». در دانشنامهٔ ویکیپدیای انگلیسی، بازبینیشده در ۲۲ اردیبهشت ۱۴۰۰.