رایانش موازی
رایانش موازی نوعی رایانش است که در آن بسیاری از محاسبات یا فرایندها بهطور همزمان انجام میشوند.[1] مشکلات بزرگ را اغلب میتوان به مشکلات کوچکتر تقسیم کرد، سپس میتوان همزمان آنها را حل کرد. چندین فرم مختلف رایانش موازی وجود دارد: سطح بیت، سطح دستورالعمل، دادهها و موازی کاری(task parallelism). موازی سازی مدت هاست که در رایانش دارای عملکرد بالا (ابر رایانه) مورد استفاده قرار میگیرد، اما به دلیل محدودیتهای فیزیکی که مانع از افزایش فرکانس (frequency scaling) بیشتر میشوند، اقبال گستردهتری پیدا کردهاست.[2] از آنجا که مصرف برق (و در نتیجه تولید گرما) توسط رایانهها در سالهای اخیر به یک نگرانی تبدیل شدهاست،[3] رایانش موازی به الگوی غالب در معماری رایانه تبدیل شدهاست، که عمدتاً به صورت پردازندههای چند هسته ای است.[4]
| پارادایمهای برنامهنویسی |
|---|
|

رایانش موازی(parallel) ارتباط نزدیکی با رایانش همروند(concurrent) دارد - آنها اغلب با هم مورد استفاده قرار میگیرند و اغلب با هم ادغام میشوند، گرچه این دو متمایز هستند: این امکان وجود دارد تا موازی سازی بدون همروندی (مانند موازی سازی در سطح بیت) و همروندی بدون موازی سازی (مانند چند وظیفه ای با به اشتراک گذاری زمان در یک پردازنده تک هسته ای).[5][6] در رایانش موازی، یک وظیفهٔ محاسباتی بهطور مرسوم به چندین، معمولاً تعداد زیادی، زیر وظیفهٔ بسیار مشابه تقسیم میشود که میتوانند بهطور مستقل پردازش شوند و نتایج آنها پس از اتمام، ترکیب شوند. در مقابل، در رایانش همروند، فرایندهای مختلف غالباً وظایف مرتبط را رفع و رجوع نمیکنند؛ اگر هم این کار را بکنند، همانطور که در رایانش توزیع شده معمول است، وظایف جداگانه ممکن است ماهیت متنوعی داشته باشند و اغلب هنگام اجرا به برخی از ارتباطات بین فرآیندی نیاز دارند.
رایانههای موازی را میتوان تقریباً بر اساس سطحی از موازی سازی که سختافزار پشتیبانی میکند، طبقهبندی کرد، در این میان رایانههای چند هسته ای و چند پردازنده دارای چندین عنصر پردازشی در یک ماشین واحد هستند، در حالی که خوشهها(clusters)، رایانش شدیداً موازی (massively paralle computing) و شبکهها(grids) از چندین رایانه برای کار با بر روی یک وظیفه استفاده میکنند. برای تسریع در انجام کارهای خاص، گاهی اوقات از معماریهای کامپیوتری موازی خاص در کنار پردازندههای سنتی استفاده میشود.
در بعضی موارد، موازی سازی برای برنامهنویس شفاف است، مانند موازی سازی در سطح بیت یا در سطح دستورالعمل، اما نوشتن الگوریتمهای صریحاً موازی، به ویژه آنهایی که از همروندی استفاده میکنند، دشوارتر از موارد متوالی است،[7] زیرا همروندی باعث بوجود آمدن چندین کلاس جدید از اشکالات نرمافزاری بالقوه میشود، که شرایط مسابقه ای شایعترین آنها است. ارتباط و همگام سازی بین زیر-وظایف مختلف معمولاً از بزرگترین موانع دستیابی به عملکرد بهینه در برنامهٔ موازی است.
در قانون آمدال، یک حداکثر مجاز نظری برای افزایش سرعت یک برنامه واحد در نتیجه موازی سازی وجود دارد.
زمینه
بهطور مرسوم، نرمافزار کامپیوتر برای رایانش متوالی (sequential computing) نوشته شدهاست. برای حل یک مسئله، الگوریتمی به شکل یک جریان متوالی از دستورالعملها ساخته و اجرا میشود. این دستورالعملها در یک واحد پردازش مرکزی در یک رایانه اجرا میشوند. فقط یک دستورالعمل میتواند در هر زمان اجرا شود - پس از پایان آن دستورالعمل، دستور بعدی اجرا میشود.[8]
از طرف دیگر، رایانش موازی از چندین عنصر پردازش گر بهطور همزمان برای حل یک مسئله استفاده میکند. این امر با تقسیم مسئله به قسمتهای مستقل حاصل میشود تا هر عنصر پردازش گر بتواند سهمی از الگوریتم را همزمان با بقیه اجرا کند. عناصر پردازش گر میتوانند متنوع باشند و شامل منابعی مانند یک رایانه با چندین پردازنده، چندین رایانه شبکه شده، سختافزار تخصصی یا هر ترکیبی از موارد فوق هستند.[8] از نظر تاریخی رایانش موازی برای محاسبات علمی و شبیهسازی مسئلههای علمی، به ویژه در علوم طبیعی و مهندسی، مانند هواشناسی استفاده میشد. این امر منجر به طراحی سختافزار و نرمافزار موازی و همچنین رایانش با کارایی بالا شد.[9]
افزایش فرکانس دلیل اصلی بهبود عملکرد رایانه(computer performance) از اواسط دهه ۱۹۸۰ تا ۲۰۰۴ بود. زمان اجرای یک برنامه برابر است با تعداد دستورالعملها ضربدر متوسط زمان برای هر دستورالعمل. با ثابت نگه داشتن همه عوامل دیگر، افزایش فرکانس ساعت باعث کاهش میانگین زمان اجرای دستورالعمل میشود؛ بنابراین افزایش فرکانس باعث کاهش زمان اجرا برای همه برنامههای غالبا-محاسباتی (compute-bound) میشود.[10] با این حال، مصرف برق (P) یک تراشه با معادلهٔ زیر محاسبه میشود:
P = C × V 2 × F
که در آن، C ظرفیتی است که در هر چرخهٔ ساعت سوئیچ میشود (متناسب با تعداد ترانزیستورهایی که ورودیهای آنها تغییر میکند)، V ولتاژ و F فرکانس پردازنده (تعداد چرخه در ثانیه) است.[11] افزایش فرکانس باعث افزایش میزان توان مصرفی در پردازنده میشود. افزایش مصرف انرژی پردازنده در نهایت منجر به لغو پردازندههای Tejas و Jayhawk اینتل در ۸ مه ۲۰۰۴ شد، که بهطور کلی به عنوان پایان افزایش فرکانس به عنوان الگوی غالب معماری رایانه ذکر میشود.[12] برای مقابله با مشکل مصرف برق و گرم شدن بیش از حد واحد پردازش مرکزی اصلی (CPU یا پردازنده)، تولیدکنندگان شروع به تولید پردازندههای چند هسته ای کارامد از نظر مصرف انرژی کردند. هسته واحد محاسباتی پردازنده است و در پردازندههای چند هسته ای هر هسته مستقل است و هستهها میتوانند بهطور همزمان به یک حافظه دسترسی داشته باشد. پردازندههای چند هسته ای رایانش موازی را به رایانههای خانگی آوردهاند؛ بنابراین موازی سازی برنامههای سریالی تبدیل به کار اصلی برنامهنویسی شدهاست. در سال ۲۰۱۲ پردازندههای چهار هسته ای در رایانههای خانگی معمول شدند، در حالی که سرورها دارای ۱۰ یا ۱۲ هستهٔ پردازنده بودند. از قانون مور میتوان پیشبینی کرد که تعداد هستهها در هر پردازنده هر ۱۸–۲۴ ماه دو برابر شود. این میتواند به این معنی باشد که پس از سال ۲۰۲۰ یک پردازنده معمولی دهها یا صدها هسته دارد.[13]
یک سیستم عامل باید اطمینان حاصل کند که وظایف مختلف و برنامههای کاربر بهطور موازی بر روی هستههای موجود اجرا میشوند. با این وجود، برای اینکه یک برنامه نرمافزاری سریالی از معماری چند هسته ای کاملاً بهره ببرد، برنامهنویس باید ساختار کد آن را تغییر دهد و این را موازی سازی کند. سرعت بخشیدن به زمان اجرای نرمافزار اپلیکیشن دیگر از طریق افزایش فرکانس امکانپذیر نیست، و در عوض برنامه نویسان برای استفاده از قدرت محاسباتی فزاینده معماریهای چند هسته ای، باید کد نرمافزار خود را موازی سازی کنند.[14]
قانون آمدال و قانون گوستافسون

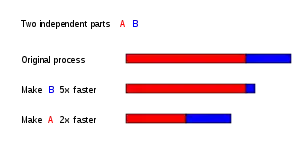
در حالت مطلوب، افزایش سرعت از طریق موازی سازی خطی خواهد بود - دو برابر شدن تعداد عناصر پردازش گر باید زمان اجرا را به نصف کاهش دهد و اگر تعداد عناصر پردازشگر برای بار دوم دو برابر شود، باز هم باید زمان اجرا نصف شود. با این حال، تعداد بسیار کمی از الگوریتمهای موازی افزایش سرعت بهینه را به دست میآورند. بیشتر آنها برای تعداد کمی از عناصر پردازش گر افزایش سرعت تقریباً خطی دارند که برای تعداد زیاد به یک مقدار ثابت میرسد و صاف میشود.
افزایش سرعت بالقوه یک الگوریتم در یک سیستم رایانش موازی توسط قانون آمدال بدست میآید:[15]

که در آن:
- Slatency، افزایش سرعت بالقوه در تأخیر اجرای کل کار است؛
- s افزایش سرعت در تأخیر اجرای قسمت قابل موازی سازی کار است.
- p درصدی از زمان کل اجرای برنامه است که متعلق به بخشی از برنامه است که قابل موازی سازی است.
از آنجا که Slatency < 1/(1 - p)، این نشان میدهد که قسمت کوچکی از برنامه که نمیتواند موازی سازی شود، افزایش سرعت(speedup) کلی حاصل از موازی سازی را محدود میکند. برنامه ای که یک مسئله بزرگ ریاضی یا مهندسی را حل میکند، معمولاً از چندین قسمت قابل موازی سازی و چند قسمت غیرقابل موازی (متوالی) تشکیل میشود. اگر قسمت غیرقابل موازی سازی یک برنامه ۱۰٪ از کل زمان اجرا را تشکیل دهد (۰٫۹ = p)، هر قدر تعداد پردازندهها را افزایش دهیم، نمیتوانیم بیش از ۱۰ برابر افزایش سرعت داشته باشیم. این امر موجب یک محدودیت حداکثری در رابطه با سودمندی افزودن واحدهای اجرایی موازی بیشتر میشود. «وقتی یک کار به دلیل محدودیتهای ناشی از توالی قابل تقسیم نیست، اعمال تلاش بیشتر هیچ تأثیری در زمانبندی آن ندارد. طول دورهٔ حاملگی نه ماه است، مهم نیست که چند زن به آن اختصاص داده شود.»[16]
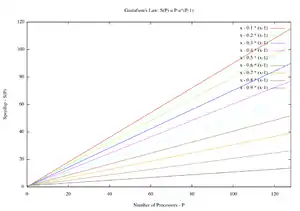
قانون آمدال فقط در مواردی اعمال میشود که اندازه مسئله ثابت باشد. در عمل، با در دسترس قرار گرفتن منابع محاسباتی بیشتر، آنها تمایل دارند که از مسئلههای بزرگتر (مجموعه دادههای بزرگتر) استفاده کنند، و زمان صرف شده در قسمت قابل موازی سازی اغلب سریعتر از کار ذاتاً سریالی رشد میکند.[17] در این حالت، قانون گوستافسون ارزیابی کمتر بدبینانه و بیشتر واقع بینانه از کارایی موازی سازی ارائه میدهد:[18]

هر دو قانون آمدال و گوستافسون فرض میکنند که زمان اجرای قسمت متوالی برنامه مستقل از تعداد پردازندهها است. قانون آمدال فرض میکند که کل مسئله دارای اندازه ثابت است به طوری که کل کار انجام شده بهطور موازی نیز مستقل از تعداد پردازندهها است، در حالی که قانون گوستافسون فرض میکند که کل کار انجام شده به صورت موازی ارتباط خطی با تعداد پردازندهها دارد.
وابستگیها
درک وابستگی دادهها در اجرای الگوریتمهای موازی اساسی است. هیچ برنامه ای نمیتواند سریعتر از طولانیترین زنجیره محاسبات وابسته (معروف به مسیر بحرانی) اجرا شود، زیرا محاسباتی که به محاسبات قبلی در زنجیره بستگی دارند باید به ترتیب اجرا شوند. با این حال، بیشتر الگوریتمها صرفاً از یک زنجیره طولانی محاسبات وابسته تشکیل نشدهاند. معمولاً فرصتهایی برای اجرای محاسبات مستقل بهطور موازی وجود دارد.
فرض کنید Pi و Pj دو بخش برنامه باشند. شرایط برنشتاین[19] زمانی را توصیف میکند که این دو مستقل باشند و بتوانند بهطور موازی اجرا شوند. برای Pi، فرض کنید Ii همه متغیرهای ورودی و Oi متغیرهای خروجی باشند، و به همین شکل، برای Pj. دو قسمت Pi و Pj در صورت برآورده کردن شرایط زیر مستقل هستند



نقض شرط اول وابستگی جریان را ایجاد میکند، به این معنی که اولین بخش نتیجه ای تولید میکند که توسط بخش دوم استفاده میشود. شرط دوم نشان دهندهٔ ضد وابستگی است، بدین معنی که قطعه دوم متغیر مورد نیاز بخش اول را تولید میکند. شرط سوم و نهایی وابستگی خروجی را نشان میدهد: وقتی دو بخش در یک مکان بنویسند، نتیجهٔ نهایی مربوط به آخرین قسمت اجرا شده از نظر منطقی است.[20]
توابع زیر را در نظر بگیرید، که انواع مختلفی از وابستگیها را نشان میدهد:
1: function Dep(a, b) 2: c := a * b 3: d := 3 * c 4: end function
در این مثال، دستورالعمل ۳ نمیتواند قبل از (یا حتی به موازات) دستورالعمل ۲ اجرا شود، زیرا دستورالعمل ۳ از نتیجه دستورالعمل ۲ استفاده میکند. این کار شرط اول را نقض میکند، بنابراین وابستگی جریان را ایجاد میکند.
1: function NoDep(a, b) 2: c := a * b 3: d := 3 * b 4: e := a + b 5: end function
در این مثال، هیچ وابستگی بین دستورالعملها وجود ندارد، بنابراین میتوان همه آنها را بهطور موازی اجرا کرد.
شرایط برنشتاین اجازه نمیدهد حافظه بین فرآیندهای مختلف تقسیم شود. برای این کار، برخی از ابزارهای اعمال نظم بین دسترسیها لازم است؛ مانند سمافورها، موانع یا سایر روشهای همگام سازی.
شرایط مسابقه، انحصار متقابل، همگام سازی و کند شدن موازی
وظایف فرعی(subtask) در یک برنامه موازی را اغلب رشته مینامند. برخی از معماریهای موازی رایانه ای از نوعی رشتههای کوچکتر و سبک که به عنوان الیاف معروف هستند استفاده میکنند، در حالی که برخی دیگر از رشتههای بزرگتر به نام پردازش استفاده میکنند. با این حال، «رشته ها» بهطور کلی به عنوان یک اصطلاح عمومی برای وظایف فرعی استفاده میشود.[21] رشتهها اغلب به دسترسی همزمان به یک شی یا منبع دیگر احتیاج دارند؛ مثلاً وقتی که آنها باید متغیری را که بین آنها به اشتراک گذاشته شدهاست به روز کنند. بدون همگام سازی، دستورالعملهای بین دو رشته به هر ترتیب ممکن است در لابلای هم قرار گیرند. به عنوان مثال، برنامه زیر را در نظر بگیرید:
| Thread A | Thread B |
| 1A: Read variable V | 1B: Read variable V |
| 2A: Add 1 to variable V | 2B: Add 1 to variable V |
| 3A: Write back to variable V | 3B: Write back to variable V |
اگر دستورالعمل 1B بین 1A و 3A اجرا شود، یا اگر دستورالعمل 1A بین 1B و 3B اجرا شود، برنامه دادههای نادرستی تولید میکند. این حالت باعث ایجاد یک شرایط مسابقه ای میشود. برنامهنویس برای ایجاد انحصار متقابل باید از قفل استفاده کند. قفل یک ساختار زبان برنامهنویسی است که به یک رشته اجازه میدهد تا کنترل یک متغیر را بدست گرفته و از خواندن یا نوشتن در آن توسط سایر رشتهها جلوگیری کند، تا زمانی که قفل آن متغیر باز شود. ریسمان نگهدارنده قفل برای اجرای بخش بحرانی آن (بخشی از برنامه که نیاز به دسترسی انحصاری به برخی از متغیرها دارد) و باز کردن قفل داده پس از اتمام کارش آزاد است؛ بنابراین، برای تضمین اجرای صحیح برنامه، میتوان برنامه فوق را برای استفاده از قفل بازنویسی کرد:
| Thread A | Thread B |
| 1A: Lock variable V | 1B: Lock variable V |
| 2A: Read variable V | 2B: Read variable V |
| 3A: Add 1 to variable V | 3B: Add 1 to variable V |
| 4A: Write back to variable V | 4B: Write back to variable V |
| 5A: Unlock variable V | 5B: Unlock variable V |
یک رشته با موفقیت متغیر V را قفل میکند، در حالی که از رشته دیگر ممانعت میشود - تا زمانی که قفل V دوباره باز شود نمیتواند ادامه دهد. این وضعیت اجرای صحیح برنامه را تضمین میکند. در صورتی که نیاز به دسترسی رشتهها به منابع بصورت سریالی باشد، ممکن است وجود قفل برای اطمینان از اجرای صحیح برنامه ضروری باشد، اما استفاده از قفلها میتواند برنامه را بسیار کند کند و بر قابلیت اطمینان آن تأثیر بگذارد.[22]
قفل کردن متغیرهای متعدد با استفاده از قفلهای غیر یکجا ممکن است موجب بنبست در برنامه شود. یک قفل یکجا (اتمیک) همزمان چندین متغیر را با هم قفل میکند. اگر نتواند همه آنها را با هم قفل کند، هیچیک را قفل نمیکند. اگر دو رشته بخواهند با استفاده از قفلهای غیر یکجا دو متغیر مشترک را قفل کنند، ممکن است که یک ریسه یکی از آنها را قفل کند و ریسه دوم متغیر دیگر را قفل کند. در چنین شرایطی، هیچکدام از دو رشته نمیتواند کامل شوند و بنبست بوجود میآید.[23]
در بسیاری از برنامههای موازی باید وظایف فرعی بهطور همگام انجام شود. این امر مستلزم استفاده از مانع(barrier) است. موانع معمولاً با استفاده از قفل یا سمافور اجرا میشوند.[24] یک کلاس از الگوریتمها، که تحت عنوان الگوریتمهای بدون قفل و بدون انتظار شناخته میشوند، درکنار هم، از استفاده از قفل و موانع جلوگیری میکنند. با این حال، اجرای این روش بهطور کلی دشوار است و نیاز به ساختارهای دادهای دارد که به درستی طراحی شده باشند.[25]
همه موازی سازیها منجر به افزایش سرعت نمیشوند. بهطور کلی، با تقسیم وظایف به رشتههای بیشتر و بیشتر، این رشتهها بخشی از زمان فزایندهٔ خود را، صرف برقراری ارتباط با یکدیگر میکنند یا منتظر یکدیگر هستند تا به منابع دسترسی پیدا کنند.[26][27] هنگامی که سربار ناشی از رقابت بر سر منابع یا ارتباطات، بر زمان صرف شده برای محاسبات دیگر غلبه پیدا کند، موازی سازی بیشتر (یعنی تقسیم بار کاری بین تعداد بیشتری از ریسهها) بیشتر موجب افزایش زمان مورد نیاز برای اتمام میشود تا کاهش آن. این مشکل که به کند شدن موازی(parallel slowdown) معروف است،[28] در برخی موارد با تجزیه و تحلیل و طراحی مجدد نرمافزار قابل بهبود است.[29]
تاریخچه
دهه ۱۹۵۰
ایده استفاده از موازی سازی چنددستور، چندداده (به انگلیسی: Multiple Instruction, Multiple Data) یا به اختصار (en:MIMD) به سال ۱۹۵۴ بر میگردد، جایی که اولین کامپیوتر تجاری محاسبات اعداد ممیز شناور توسط جن آمدال در شرکت آی بی ام با نام ۷۰۴ تولید شد. در آوریل ۱۹۵۸ اس. جیل (فرانتی)، بحث انشعاب و انتظار را در برنامهنویسی موازی مطرح کرد. همچنین در همین سال دو تن از محققان شرکت آی بی ام به نامهای جان کوک و دنییل اسلوتنیک، ایده استفاده از موازی سازی در محاسبات عددی را برای اولین بار مطرح کردند.
دهه ۱۹۶۰
در سال ۱۹۶۲ شرکت باروز، کامپیوتر دی ۸۲۵ که دارای ۴ پردازنده و توانایی دسترسی به ۱۶ ماژول حافظه از طریق سوییچ چلیپایی بود را معرفی کرد. در سال ۱۹۶۷، آمدال و اسلوتنیک در کنفرانس پردازش اطلاعات در آمریکا، قانون آمدال را معرفی کردند که محدودیت افزایش سرعت در برابر موازی سازی را مطرح میکند. در سال ۱۹۶۹ شرکت هانی ول، سیستم چندپردازندهای را معرفی کرد که دارای ۸ پردازنده به صورت موازی بود.
دهه ۱۹۸۰
اولین کامپیوتر مدرن یک دستور، چند داده (به انگلیسی: Single Instruction, Multiple Data) یا به اختصار (en:SIMD) در سال ۱۹۸۷ با نام ماشین متفکر توسط دنی هیلز و شرلی هندلر بازسازی شد.
دهه ۱۹۹۰
در دهه ۱۹۹۰ تولید کامپیوترهای یک دستور، چندداده روند رو به رشدی پیدا کردند، در سال ۱۹۹۵ شرکت سانمیکروسیستم UltraSPARC را معرفی کرد. همچنین شرکت اینتل در سال ۱۹۹۶ اولین کامپیوتر رو میزی دارای سیستم یکدستور، چندداده برای سیستمهای ۳۲ بیتی معرفی کرد. در سال ۱۹۹۶ استاندارد (en:POSIX Threads) برای برنامهنویسی چند نخی معرفی شد. همچنین در این دهه معماری (en:OpenMP) در سال ۱۹۹۷ برای برنامهنویسی سیستمهای موازی با زبان فرترن معرفی گردید، و در سال ۱۹۹۸ نیز نسخه C/C++ این معماری معرفی شد.
سال ۲۰۰۰ تا کنون
از سال ۲۰۰۰ تا کنون نسخههای بهبود یافتهای از OpenMP ارائه شدهاست. در سال ۲۰۰۰ نسخه ۲٫۰ فرترن و در سال ۲۰۰۲ نسخه ۲٫۰ سی پلاس پلاس OpenMP ارائه شد. نسخه ۲٫۵ در سال ۲۰۰۵ و نسخه ۳٫۰ در سال ۲۰۰۸ ارائه شد. نسخه ۴٫۰ برنامه در سال ۲۰۱۲ ارائه شد.
ارتباط بین پردازشها
پردازشها (به انگلیسی: Process) در برنامهنویسی موازی برای انجام محاسبات خود نیاز به برقراری ارتباط با یکدیگر دارند، که روشهای زیر برای این کار میباشند:
- حافظه اشتراکی (en: Shared Memory)
- تبادل پیام (en: Message Passing)
- مدل ضمنی (به انگلیسی: Implicit)
حافظه اشتراکی
در حافظه اشتراکی، وظایف (به انگلیسی: Task) موازی برای برقراری ارتباط با یکدیگر از یک فضای آدرس اشتراکی که توانایی نوشتن و خواندن غیرهمزمان (به انگلیسی: asynchronous) را دارد استفاده میکنند. در این حالت برای کنترل دسترسیهای همزمان (به انگلیسی: synchronous) وظایف به این آدرسها نیاز به مکانیزمهایی مانند قفلها، سمافورها و مانیتورها میباشد.
تبادل پیام
در این روش، وظایف موازی دادههای مورد نیاز را از طریق پیام برای یکدیگر ارسال میکنند، که این ارتباطات میتوانند همزمان یا غیرهمزمان باشند. در روش غیرهمزمان فرستنده پیام خود را بدون توجه به آمادگی گیرنده ارسال میکند.
مدل ضمنی
در این مدل، ارتباط بین وظایف بدون دخالت برنامهنویس انجام میشود. به این صورت که کامپایلر این کار را انجام میدهد.
اصول برنامهنویسی موازی
یافتن موازات کافی در برنامه(قانون آمدال)
طبق قانون آمدال در برنامهنویسی موازی، باید طوری برنامه را به دو قسمت موازی و سریال تقسیم کرد، که مقدار سرباری (به انگلیسی: Overhead) که به سیستم به دلیل تقسیم وظایف میان نخها/پردازندهها تحمیل میشود از مقدار سودی که به دلیل موازی کردن برنامه بدست میآوریم کمتر باشد.
دانهدانه کردن
هنگام تقسیم وظایف، باید به اندازه قسمتی از برنامه که قرار است به صورت موازی اجرا شود توجه داشت. به این صورت که در صورت زیاد بودن تعداد آنها و کوچک بودن این قسمتها سربار بسیار زیادی به سیستم تحمیل خواهد شد، و در صورتی که اندازه این قسمتها بسیار بزرگ باشد، در آن صورت این قسمتها تقریباً به صورت سریال اجرا میشود که افزایش سرعتی در این حالت نخواهیم داشت.
محلی سازی
سرعت دسترسی به حافظههای دارای حجم بالا کم بوده، و سرعت دسترسی به حافظههای دارای حجم پایین زیاد میباشد. با توجه به این امر، برنامهنویس باید طوری عمل کند که الگوریتمهای موجود در برنامه باید بیشتر کار خود را روی دادههای موجود در حافظه محلی (به انگلیسی: Local Memory) انجام دهند.
عدم تعادل بار
عدم تعادل بار (به انگلیسی: Load Imbalance) به حالتی گفته میشود که در آن بعضی از پردازندهها در برخی زمانها به دلایل زیر کاری را انجام نمیدهند:
- موزات ناکافی.
- وظایف غیرهماندازه.
تعادل بار به دو صورت ایستا (به انگلیسی: Static)، یا پویا (به انگلیسی: Dynamic) در زمان اجرا انجام میپذیرد.
همگام سازی
بسیاری از الگوریتمهایی که برای اجرای موازی فرمانهای، موازیسازی میشوند، الگوریتمهایی هستند که پردازشهای موازی حاصل از آنها بدون نیاز به ارتباط با دیگر پردازشها، به محاسبات خود پرداخته و آن را ادامه میدهند. اما الگوریتمهای دیگری نیز وجود دارند که در آنها هر پردازنده محاسبات تکراری یکسانی را روی یک جزء متمایز دادهای انجام میدهد، اما پردازندهها باید در انتهای هر تکرار با یکدیگر همگام (به انگلیسی: Sync) شوند و نتایج میانی خود را در اختیار دیگر پردازندهها قرار دهند. یک روش مورد استفاده برای همگامسازی استفاده از حصاربند (به انگلیسی: Barrier) است که در این روش پردازشهای اولیه که دستورالعمل حصاربندی را اجرا میکنند تا زمانی که تمام پردازشهای دیگر وارد این نقطه شوند، در انتظار باقی میمانند.
شرایط مسابقه
شرایط مسابقه (به انگلیسی: Race Condition) یکی از خطاهای رایج در برنامهنویسی موازی به دلیل دسترسی همزمان وظایف به منابع میباشد که این خطاها به صورت غیرقطعی بوده (به انگلیسی: non-deterministic) و لذا تشخیص آنها سخت میباشد. برای جلوگیری از به وجود آمدن این شرایط میتوان از قفلهای سختافزاری یا نرمافزاری استفاده کرد.
ابزارهای برنامهنویسی موازی
با استفاده از ابزارها، برنامهنویس میتواند خود به طراحی روند اجرای موازی برنامه بپردازد و برای اموری مانند متغیرهای اشتراکی، وابستگی ورودی و خروجی رشتههای موازی، ارتباط میان رشتههای پردازشی یا پردازهها و تجزیهپذیری بنیادی راهحل مسئله مورد نظر تصمیم بگیرد و شیوه توزیع شدن محاسبه، متغیرها و اشیا را طراحی کند. این دسته ابزارها خود به دو گروه عمده تقسیم میشوند:
- ابزارهای برنامهسازی برای سیستمهای دارای حافظه اشتراکی
- ابزارهای برنامهنویسی برای سیستمهای دارای حافظه توزیعشده (en: Distributed Memory).
POSIX Threads
مجموعهای از کتابخانههای استاندارد به زبان C، که دارای توابعی برای برنامهنویسی موازی چندنخی میباشد و معمولاً با عنوان Pthreads شناخته میشود. در Pthreads نخها از یک فضای آدرس دهی مشترک استفاده میکنند که کنترل و همگامسازی دسترسی نخها به این حافظه بر عهده برنامهنویس میباشد. همچنین هر نخ فضای آدرس مخصوص به خود را دارد. Pthreads برای برنامههای که دارای ویژگیهای زیر هستند، میتواند مناسب باشد:
- چند وظیفه به صورت همزمان، قابلیت اجرای پردازش روی دادههای برنامه را داشته باشند.
- قطعههای از برنامه که زمان زیادی را منتظر ورودی/خروجی میمانند.
- برنامههایی که در آنها برخی کارها نسبت به بقیه دارای اولویت باشد. (وقفههای اولویت)
دلایل استفاده از Pthreads
- Pthreads، هنگام اجرای برنامه کار پردازنده را با کار ورودی/خروجی همپوشانی میسازد.
- نخها با سربار بسیار کمتری نسبت به پردازشها در سیستم ایجاد میشوند.
- تمام نخها در داخل یک پردازش، از یک فضای آدرس اشتراکی استفاده میکنند.
OpenMP(open multi-processing)
OpenMP یک واسط برنامهنویسی کاربردی (en: API) برای برنامهنویسی موازی رشتهها در سیستمهای حافظه اشتراکی با یکی از سه زبان C, C++ یا فورترن است و از معماریهای مختلفی از جمله پلتفرمهای ویندوز و یونیکس پشتیبانی میکند. البته تولیدکنندگان کامپایلر برای زبانهای دیگر از جمله جاوا نیز امکان نوشتن برنامه با رابط OpenMP را فراهم کردهاند. باید توجه داشت، OpenMP تضمین نمیکند که از حافظه اشتراکی استفاده بهینه خواهد کرد. همچنین مواردی مانند وابستگی دادهها، شرایط مسابقه یا بنبستها(به انگلیسی: deadlock) باید توسط خود برنامهنویس در کد برنامه کنترل شود وOpenMP عموماً نمیتواند کاری دربارهٔ آنها انجام دهد. همزمان سازی ورودی و خروجی هنگام دسترسی موازی و چک کردن ترتیب اجرای کد برنامه نیز از جمله وظایف برنامهنویس است و از عهده OpenMP خارج است. بهاین ترتیب، برنامهنویس باید ساختار کد و الگوریتم خود را کاملاً کنترل کرده و اطمینان حاصل کند که موارد ذکر شده در اجرای برنامه رخ نخواهد داد.
دلایل و مزایای استفاده از OpenMP
- سختی استفاده از کتابخانههای مربوط به نخها، رابطهایی (به انگلیسی: Interface) مانند Pthreads دارای تعداد زیادی فراخوانی کتابخانهای (به انگلیسی: Library Call) برای مقدار دهی اولیه(به انگلیسی: Initialization)، همگام سازی، ساخت نخ و دیگر کارها دارند.
- سادگی انجام موازیسازی برنامه سریال با برچسب زنی(به انگلیسی: Annotation) کد برنامه که موازات را نشان میدهد.
- مقیاس پذیری (به انگلیسی: Scalibility) و کارایی خوب در صورت استفاده صحیح.
- قابل حمل بودن(به انگلیسی: Portable) برنامه نوشته شده با OpenMP، به دلیل پشتیبانی بسیاری از کامپایلرها از OpenMP.
- عدم نیاز به برنامهنویسیهای پیچیده توسط برنامهنویس.
- اجرا شدن هر نخ برنامه در OpenMP توسط نخهای سختافزاری.
رابط عبور پیام
متداولترین شیوه برنامهنویسی موازی استفاده از MPI میباشد. رابط عبور پیام، ویژگیهای یک واسط برنامهنویسی کاربردی کلی برای برنامهنویسی موازی را برای سیستمهای دارای حافظه توزیعیافته مانند کلاسترهای تیغهای و مجموعه آنها تعیین میکند و به خودی خود یک ابزار نیست، بلکه یک طرح ویژگیها (به انگلیسی: Specification) و یک پروتکل ارتباطی بهشمار میرود و همانگونه که از نامش پیداست، شیوه صحبت کردن سیستمهای موازی با هم را تعیین میکنند. مهمترین مزیت روش رابط عبور پیام به سایر روشهای عبور پیام، قابل حمل بودن و سرعت بالای آن میباشد. سرعت بالای این روش به این دلیل است که هنگام اجرا بر روی هر سختافزاری برای آن سختافزار بهینه میشود. مزیت بزرگ دیگر این روش، توانایی فراخوانی توابع آن با زبانهای C++، C، فورترن، جاوا، C# و پایتون میباشد.
زبانهای برنامهنویسی موازی
زبانهای برنامهنویسی همزمان، کتابخانهها، رابطهای برنامه کاربردی، و مدلهای برنامهنویسی موازی (مانند اسکلت الگوریتمی) برای برنامهنویسی موازی کامپیوترها ایجاد شدهاست. این بهطور کلی به چند کلاس بر مبنای حافظه معماری مشترک، حافظه توزیع شده و حافظه توزیع شده مشترک تقسیم میشود. زبانهای برنامهنویسی حافظه مشترک با دستکاری متغیرهای حافظه مشترک ارتباط برقرار کنید. حافظه توزیع شده از عبور پیام استفاده میکنند. تردهای POSIX و OpenMP هردو بیشتر از رابطهای برنامههای کاربردی حافظه مشترک استفاده میکنند، درحالی که رابط عبور پیام (MPI) بیشتر از رابطهای برنامه کاربردی سیستم عبور پیام استفاده میکند.[30]
در کنار رهیافتهایی مانند MPI و OpenMP که قابلیتهای مورد نیاز برای برنامهنویسی موازی با زبانهای شناختهشدهای مانند C و فرترن را فراهم میآورند، شمار قابل توجهی زبان برنامهنویسی مستقل، از اساس برای نوشتن کدهای پردازش موازی ایجاد شدهاند.
لیندا
لیندا به دستهای از زبانهای برنامهنویسی موازی تعلق دارد که در آنها تقسیم کارهای درون برنامه به رشتهها و فرستادن رشتهها به پردازندهها باید بهطور صریح در متن کد مشخص شود، اما ارتباط میان رشتههای ایجادشده بر عهده برنامهنویس نیست.
لیندا به خودی خود یک زبان قابل استفاده مستقیم نیست و به اصطلاح یک زبان هماهنگسازی (به انگلیسی: Coordination) خوانده میشود. پیادهسازیهایی از آن برای بسیاری از زبانهای برنامهنویسی و اسکریپتنویسی متداول، از جمله جاوا، C و C++، پایتون و روبی ارائه شدهاست. خصلت اصلی لیندا آن است که به جای مدل ارتباط نقطه به نقطه که در بیشتر رهیافتهای برنامهنویسی موازی دنبال میشود، مفهومی به نام فضای چندگانه (به انگلیسی: tuple space) را ارائه میکند که بستر اصلی موازیسازی در مدل این زبان است. فضای چندگانه یک مخزن عمومی دادهها است که دادهها را میتوان در آن ذخیره و سپس از آن بازیابی کرد.[31]
ارلنگ
ارلنگ یک زبان زمان اجرا است که از ابتدا با هدف مستقیم ایجاد برنامههای موازی بیدرنگ با آستانه تحمل خطای بالا و تا حد زیادی با در نظر داشتن سیستمهای مخابراتی نوشتهشدهاست. ارتباط میان پردازشها در ارلنگ صریح است و همانند OpenMP باید توسط برنامهنویس تعیین شود، اما بر خلافOpenMP، ارلنگ از تبادل پیام برای ارتباط میان روندها استفاده میشود. ارلنگ زبانی مبتنی بر تابعها است، به این مفهوم که پردازش دادهها در یک برنامه ارلنگ در قالب محاسبه تابعهای ریاضی صورت میپذیرد و تقریباً همه چیز با تعریف کردن تابعها انجام میشود. موازیسازی پردازش در ارلنگ با تعریف کردن روندهایی که اشتراکی با هم ندارند، انجام میشود. ارتباط میان این روندها توسط یک سیستم تبادل پیام ناهمگام انجام میشود.[31]
چارم++
چارم++، زبانی مبتنی بر C++ است که با هدف آسان کردن برنامهنویسی موازی و با ارائه قابلیتهای برنامهنویسی موازی در سطح بالایی از انتزاع ارائه شدهاست. مبنای موازیسازی برنامه در چارم++، بر تجزیهکردن برنامه بهشماری شیء به نام Chare است. Chareها با یکدیگر تعامل دارند و به پیامها وابسته هستند. Chareها در زمان اجرای برنامه با یک سیستم زمان اجرای پویا به پردازندههای مختلف متناظر میشوند که چارم++، امکان تغییر دادن این تناظر هنگام اجرای برنامه را فراهم میآورد. چنین امکانی برای متعادل کردن بار پردازشی روی پردازندهها در زمان اجرا مفید است. امکان برنامهنویسی با شیوهای مبتنی بر رابط عبوری پیام، نیز با ارائه یک پیادهسازی از آن به نام رابط عبوری تطبیقی پیام به اختصار AMPI در لایهای روی چارم++، فراهم شدهاست.[31]
Unified Parallel C
زبانی بر پایه C99 است که قابلیتهای آن را برای برنامهنویسی موازی برای سیستمهای دارای حافظه اشتراکی یا توزیعیافته گسترش میدهد. مبنای برنامهنویسی در UPC بر پایه اشتراک داده میان پردازندههای مختلف است، به گونهای که همه پردازندهها به تمام متغیرها در برنامه دسترسی دارند، اما هر متغیر در اصل به یک پردازنده مشخص تعلق دارد. موازیسازی برنامه هنگام آغاز اجرا شدن آن تعیین میشود و در طول اجرا تغییر نمیکند، زیرا تناظر میان متغیرها با پردازندهها را در میانه اجرای برنامه نمیتوان تغییر داد. برای نوشتن برنامههای پردازش موازی به اینگونه، UPC چهار دسته ساختار به ابزارهای عادی C میافزاید:
- یک مدل صریح اجرای موازی.
- فضای حافظه اشتراکی.
- شیوههایی برای همگامسازی متغیرها
- مدلی برای بررسی سازگاری درونی حافظه اشتراکی و شیوههایی برای مدیریت حافظه.[31]
کاربردهای پردازش موازی
پیشبینی وضعیت اب و هوایی: استفاده از مدلهای ریاضی از اقیانوس و جو و گرفتن مشاهدات فعلی آب و هوا و پردازش این دادهها با مدلهای کامپیوتری برای پیشبینی وضعیت آینده آب و هوا.
مسائل اقتصادی جامعه: پردازش موازی برای مدلسازی اقتصاد یک جهان یا ملت استفاده میشود. سیستم برنامهها که شامل دستگاههای محاسبه خوشه ای هستند، برای پیادهسازی الگوریتمهای موازی در راستای بهینهسازی در چنین مدلهای اقتصادی استفاده میشود.
هوش مصنوعی و اتوماسیون: هوش مصنوعی یا هوش ماشینی (به انگلیسی: Artificial Intelligence)هوشی که یک ماشین در شرایط مختلف از خود نشان میدهد، گفته میشود. که در این سیستمها تا حد زیادی از پردازش موازی استفاده میشود. به عنوان مثال در ۴ عمل ۱)پردازش تصویر ۲)پردازش زبانهای طبیعی ۳) تشخیص الگوها ۴)سیستمهای خبره ف پردازش موازی کاربرد دارد.
نرمافزار پزشکی: پردازش موازی در پردازش تصویر پزشکی استفاده میشود. به عنوان مثال برای اسکن بدن انسان و اسکن مغز انسان، در بازسازی MRI برای تشخیص مهرهها استفاده میشود.
منابع
- Gottlieb, Allan; Almasi, George S. (1989). Highly parallel computing. Redwood City, Calif.: Benjamin/Cummings. ISBN 978-0-8053-0177-9.
- S.V. Adve et al. (November 2008). "Parallel Computing Research at Illinois: The UPCRC Agenda" بایگانیشده در ۲۰۱۸-۰۱-۱۱ توسط Wayback Machine (PDF). Parallel@Illinois, University of Illinois at Urbana-Champaign. "The main techniques for these performance benefits—increased clock frequency and smarter but increasingly complex architectures—are now hitting the so-called power wall. The computer industry has accepted that future performance increases must largely come from increasing the number of processors (or cores) on a die, rather than making a single core go faster."
- Asanovic et al. Old [conventional wisdom]: Power is free, but transistors are expensive. New [conventional wisdom] is [that] power is expensive, but transistors are "free".
- Asanovic, Krste et al. (December 18, 2006). "The Landscape of Parallel Computing Research: A View from Berkeley" (PDF). University of California, Berkeley. Technical Report No. UCB/EECS-2006-183. "Old [conventional wisdom]: Increasing clock frequency is the primary method of improving processor performance. New [conventional wisdom]: Increasing parallelism is the primary method of improving processor performance… Even representatives from Intel, a company generally associated with the 'higher clock-speed is better' position, warned that traditional approaches to maximizing performance through maximizing clock speed have been pushed to their limits."
- "Concurrency is not Parallelism", Waza conference Jan 11, 2012, Rob Pike (slides بایگانیشده در ۲۰۱۵-۰۷-۳۰ توسط Wayback Machine) (video)
- "Parallelism vs. Concurrency". Haskell Wiki.
- Hennessy, John L.; Patterson, David A.; Larus, James R. (1999). Computer organization and design: the hardware/software interface (2. ed. , 3rd print. ed.). San Francisco: Kaufmann. ISBN 978-1-55860-428-5.
- Barney, Blaise. "Introduction to Parallel Computing". Lawrence Livermore National Laboratory. Archived from the original on 29 June 2013. Retrieved 2007-11-09.
- Thomas Rauber; Gudula Rünger (2013). Parallel Programming: for Multicore and Cluster Systems. Springer Science & Business Media. p. 1. ISBN 978-3-642-37801-0.
- Hennessy, John L.; Patterson, David A. (2002). Computer architecture / a quantitative approach (3rd ed.). San Francisco, Calif.: International Thomson. p. 43. ISBN 978-1-55860-724-8.
- Rabaey, Jan M. (1996). Digital integrated circuits: a design perspective. Upper Saddle River, N.J.: Prentice-Hall. p. 235. ISBN 978-0-13-178609-7.
- Flynn, Laurie J. (8 May 2004). "Intel Halts Development Of 2 New Microprocessors". New York Times. Retrieved 5 June 2012.
- Thomas Rauber; Gudula Rünger (2013). Parallel Programming: for Multicore and Cluster Systems. Springer Science & Business Media. p. 2. ISBN 978-3-642-37801-0.
- Thomas Rauber; Gudula Rünger (2013). Parallel Programming: for Multicore and Cluster Systems. Springer Science & Business Media. p. 3. ISBN 978-3-642-37801-0.
- Amdahl, Gene M. (1967). "Validity of the single processor approach to achieving large scale computing capabilities". Proceeding AFIPS '67 (Spring) Proceedings of the April 18–20, 1967, Spring Joint Computer Conference: 483–485. doi:10.1145/1465482.1465560.
- Brooks, Frederick P. (1996). The mythical man month essays on software engineering (Anniversary ed. , repr. with corr. , 5. [Dr.] ed.). Reading, Mass. [u.a.]: Addison-Wesley. ISBN 978-0-201-83595-3.
- Michael McCool; James Reinders; Arch Robison (2013). Structured Parallel Programming: Patterns for Efficient Computation. Elsevier. p. 61.
- Gustafson, John L. (May 1988). "Reevaluating Amdahl's law". Communications of the ACM. 31 (5): 532–533. CiteSeerX 10.1.1.509.6892. doi:10.1145/42411.42415. S2CID 33937392. Archived from the original on 2007-09-27.
- Bernstein, A. J. (1 October 1966). "Analysis of Programs for Parallel Processing". IEEE Transactions on Electronic Computers. EC-15 (5): 757–763. doi:10.1109/PGEC.1966.264565.
- Roosta, Seyed H. (2000). Parallel processing and parallel algorithms: theory and computation. New York, NY [u.a.]: Springer. p. 114. ISBN 978-0-387-98716-3.
- "Processes and Threads". Microsoft Developer Network. Microsoft Corp. 2018. Retrieved 2018-05-10.
- Krauss, Kirk J (2018). "Thread Safety for Performance". Develop for Performance. Retrieved 2018-05-10.
- Tanenbaum, Andrew S. (2002-02-01). Introduction to Operating System Deadlocks. Informit. Pearson Education, Informit. Retrieved 2018-05-10.
- Cecil, David (2015-11-03). "Synchronization internals – the semaphore". Embedded. AspenCore. Retrieved 2018-05-10.
- Preshing, Jeff (2012-06-08). "An Introduction to Lock-Free Programming". Preshing on Programming. Retrieved 2018-05-10.
- "What's the opposite of "embarrassingly parallel"?". StackOverflow. Retrieved 2018-05-10.
- Schwartz, David (2011-08-15). "What is thread contention?". StackOverflow. Retrieved 2018-05-10.
- Kukanov, Alexey (2008-03-04). "Why a simple test can get parallel slowdown". Retrieved 2015-02-15.
- Krauss, Kirk J (2018). "Threading for Performance". Develop for Performance. Retrieved 2018-05-10.
- ^ The Sidney Fernbach Award given to MPI inventor Bill Gropp refers to MPI as "the dominant HPC communications interface"
- «پایگاه اطلاعرسانی ماهنامه شبکه». ۲۸ فروردین ۱۳۹۲.
- جزوه درس برنامهنویسی موازی، فرشاد خونجوش، دانشکده برق و کامپیوتر، دانشگاه شیراز.
- جزوه درس برنامهنویسی موازی، رضا عظیمی، دانشکده برق و کامپیوتر، دانشگاه شیراز.
- PowerPoint lecture, Professor Saman Amarasinghe, MIT, http://groups.csail.mit.edu/cag/ps3/lectures.shtml بایگانیشده در ۳ سپتامبر ۲۰۱۵ توسط Wayback Machine
- PowerPoint lecture, Professors Arvind and Joe Elmer, MIT, http://csg.csail.mit.edu/6.823/lecnotes.html
- Parallel Programming C with MPI and OpenMP By Michael J. Quinn
- List of concurrent and parallel programming languages
- https://www.slideshare.net
- Efficient multitasking: parallel versus serial processing of multiple tasks ,Rico Fischer1 and Franziska Plessow,Front Psychol. 2015; 6: 1366
| در ویکیانبار پروندههایی دربارهٔ رایانش موازی موجود است. |
Note: This template roughly follows the 2012 ACM Computing Classification System. | |
| سختافزار | |
| سازمان سامانههای رایانه |
|
| شبکه رایانهای | |
| سازمان نرمافزار | |
| نظریه زبانهای برنامهنویسی و ابزار توسعه نرمافزار | |
| توسعه نرمافزار | |
| نظریه محاسبات | |
| الگوریتمها | |
| ریاضیات رایانه | |
| سامانه اطلاعاتی | |
| امنیت رایانه | |
| تعامل انسان و رایانه | |
| همروندی | |
| هوش مصنوعی | |
| یادگیری ماشین | |
| گرافیک رایانهای | |
| رایانش کاربردی | |
توجه: بنا بر سامانه ردهبندی رایانش ایسیام علم رایانه همچنین میتواند به موضوعها یا زمینههای گوناگون تقسیم شود.
| |