واحد پردازش مرکزی
واحد پردازش مرکزی (به انگلیسی: central processing unit) یا همان پردازنده مرکزی، پردازنده اصلی، یا فقط پردازنده، یک مدار الکترونیکی است که دستورالعملهایی را اجرا میکند که یک برنامه کامپیوتری را تشکیل میدهند. واحد پردازنده مرکزی، اعمال اصلی محاسباتی، منطقی، کنترل و ورودی/خروجی (input/output) را انجام میدهد. این اعمال توسط دستورالعملهای برنامه مشخص میشوند. آنچه که ذکر شد تفاوت بسیاری با اجزای خارجی، نظیر: حافظه اصلی و مدار ورودی/خروجی و پردازندههای اختصاصی نظیر واحد پردازنده گرافیکی (graphics processing units) دارد.[1]


فرم، طراحی، و پیادهسازی سی پی یوها در طول زمان تغییر کردهاست، اما عملیات پایه ای آنها تقریباً بدون تغییر باقی ماندهاست. اجزای اصلی یک سی پی یو عبارتند از: واحد منطق و محاسبه(arithmetic logic unit) که عملیات حسابی و منطقی را انجام میدهد، رجیسترهای (ثباتهای) پردازنده که برای ALU عملوند فراهم میکنند و نتایج عملیات را ذخیره میکنند، و یک واحد کنترل که عمل واکشی دستورالعملها از حافظه و اجرای آنها را با هدایت کردن عملیات هماهنگ ALU، رجیسترها و سایر اجزا سازماندهی میکند.
اکثر سی پی یوهای جدید، روی ریزپردازندههای مدار مجتمع (integrated circuit)، با یک یا بیش از یک سی پی یو، روی یک تراشهٔ IC نیمه هادی اکسید فلز (metal-oxide-semiconductor) پیادهسازی میشوند. تراشههای ریزپردازندهها که دارای چندین سی پی یو هستند، پردازندههای چند هسته ای نام دارند. میتوان سی پی یوهای فیزیکی منفرد، با نام هستههای پردازنده، را نیز چند ریسمانی (multithreading) کرد تا سی پی یوهای منطقی یا مجازی بیشتری به وجود آید.
یک آی سی که حاوی یک سی پی یو است، ممکن است دارای حافظه، رابطهای محیطی، و سایر اجزای یک کامپیوتر باشد؛ این ابزارهای مجتمع در مجموع میکروکنترلر یا سیستمهای روی یک تراشه (systems on a chip) نام دارند.
پردازندههای آرایه ای یا پردازندههای برداری (vector) دارای چندین پردازنده هستند که به صورت موازی عمل میکنند و هیچ واحدی در مرکزیت قرار ندارد سی پی یوهای مجازی یک فرم انتزاعی از منابع محاسباتی مجتمع پویا هستند.[2]
تاریخچه

کامپیوترهای ابتدایی همچون ENIAC، برای انجام کارهای مختلف باید سیم کشی مجدد میشدند، از این جهت به آنها «کامپیوترهای برنامه-ثابت» میگفتند.[3]اصطلاح «واحد پردازش مرکزی»، از اوایل سال ۱۹۵۵ استفاده شدهاست.[4][5] از آنجایی که اصطلاح سی پی یو بهطور کلی، به ابزاری برای اجرای نرمافزار (برنامهٔ کامپیوتر) اطلاق میشود، ابتداییترین ابزارهایی که به درستی سی پی یو نام گرفتند، در واقع با ابداع رایانههای با قابلیت ذخیرهٔ برنامه به وجود آمدند.
ایدهٔ یک کامپیوتر ذخیره کنندهٔ برنامه، قبل از این در طراحی سیستم ENIAC آقای J. Presper Eckert و John William Mauchly وجود داشت، اما در ابتدا حذف شد تا پروژه زودتر تمام شود.[6]در ۳۰ ژوئن ۱۹۴۵ و قبل از ساخت ENIAC، ریاضیدانی به نام John von Neumann مقاله ای را تحت عنوان "اولین پیش نویس یک گزارش در رابطه با ادواک (EDVAC) " منتشر کرد، که توصیفی کلی از یک کامپیوتر ذخیره کنندهٔ برنامه بود که سرانجام، در اوت ۱۹۴۹ کامل شد.[7] کامپیوتر ادواک طوری طراحی شد تا تعداد خاصی از دستورالعملها (یا عملیات) مختلف را اجرا کند. با تفاوت چشمگیر، برنامههای نوشته شده برای EDVAC قابل ذخیرهسازی در حافظه ی سریع کامپیوتر بود و نه به شکل سیم کشی فیزیکی در کامپیوتر.[8] این نوآوری موجب برطرف شدن برخی محدودیتهای شدید ENIAC شد، که عبارت بودند از: مدت زمان و تلاش زیاد برای پیکربندی مجدد کامپیوتر برای انجام یک کار جدید.[9] با استفاده از طراحی آقای John von Neumann، برنامه ای که کامپیوتر EDVAC میتوانست اجرا کند، به سادگی با تغییر دادن محتویات حافظه قابل تغییر بود. با این وجود، EDVAC اولین کامپیوتر ذخیره کنندهٔ برنامه نبود. نوزاد منچستر (Manchester Baby)، یک کامپیوتر کوچک تحقیقاتی با قابلیت ذخیرهسازی برنامه بود که اولین برنامه را در ۲۱ ژوئن ۱۹۴۸ اجرا کرد[10] و کامپیوتر Manchester Mark 1 اولین برنامه خود را در شب ۱۶ یا ۱۷ام ژوئن ۱۹۴۵ اجرا کرد.[11]
اولین سی پی یوها دارای طراحی سلیقه ای بودند و به عنوان بخشی از یک کامپیوتر بزرگتر و گاهی خاص استفاده میشدند.[12] با این حال، این روش سلیقه ای طراحی سی پی یوها برای کاربری خاص، بهطور چشمگیری راه را برای تولید پردازندههایی با کاربرد چندگانه و به صورت انبوه هموار کرد. این استانداردسازی، در دورهٔ رایانههای بزرگ (mainframe) ترانزیستوری گسسته و ریز رایانه ها(minicomputer) شروع شد و با فراگیری مدارهای مجتمع، به سرعت شتاب پیدا کرد. مدار مجتمع، امکان طراحی و تولید سی پی یوهای پیچیدهتر را تا حد تحمل نانومتری فراهم کرد.[13] هم کوچک سازی و هم استانداردسازی سی پی یوها، موجب افزایش و فراگیری ابزارهای دیجیتال در زندگی مدرن شد، که بسیار بیشتر از کاربرد محدود آنها در ماشینهای محاسباتی اختصاصی بود. ریزپردازندههای جدید در ابزارهای الکترونیک، از خودروها گرفته[14] تا گوشیهای همراه[15] و حتی گاهی در اسباب بازیها وجود دارند.[16][17]
آقای جان وان نویمان، بخاطر طراحی کامپیوتر ذخیره کنندهٔ برنامه شناخته شدهاست، که به خاطر تلاش وی برای ساخت EDVAC است. بعدها این طراحی، معماری وان نویمان نام گرفت. با این وجود، افرادی قبل از او، نظیر آقای Konrad Zuse ایدههای مشابهی را پیشنهاد و پیادهسازی کردند.[18] معماری هاروارد نیز، که مربوط به Harvard Mark I است و قبل از EDVAC کامل شد،[19][20] از طراحی ذخیرهسازی برنامه استفاده کرد، که به جای حافظه الکترونیک، از نوار کاغذی سوراخ شده استفاده میکرد.[21] تفاوت کلیدی بین معماریهای آقای von Neumann و هاروارد این است که در معماری هاروارد، ذخیرهسازی و استفاده از دستورالعملهای سی پی یو از دادهها جدا شدهاست، در حالیکه در معماری von Neumann از حافظه یکسانی برای ذخیرهٔ دادهها و دستورالعملها استفاده میشود.[22] اکثر سی پی یوهای جدید برمبنای von Neumann طراحی شدهاند. اما معماری هاروارد نیز وجود دارد، خصوصاً در کاربردهای نهفته، برای مثال، میکروکنترلرهای ای وی آر Atmel، در واقع پردازندههای مبتنی بر معماری هاروارد هستند.[23]
رله ها(relay) و لامپهای خلاء(vacuum tubes) یا همان لولههای ترمیونیک بهطور شایعی به عنوان عناصر سوئیچ استفاده میشدند.[24][25] یک کامپیوتر کاربردی نیاز به هزاران یا دهها هزار ابزار سوئیچ دارد. سرعت کلی یک سیستم وابسته به سرعت سوئیچها است. کامپیوترهای لامپ خلاء (نظیر EDVAC) بهطور میانگین ۸ ساعت از یک شکست تا شکست بعدی زمان میبردند، در حالیکه کامپیوترهای رله ای نظیر، Harvard Mark I (که کندتر اما قدیمی تر است) بندرت دچار شکست میشدند.[5] درنهایت، سی پی یوهای مبتنی بر لامپها ی خلاء غلبه پیدا کردند، زیرا مزایای سرعت چشمگیر بیشتر از مشکل قابل اعتماد بودن است. اکثر این سی پی یوهای همگام، در مقایسه با طراحیهای میکروالکترونیک جدید دارای سرعتهای ساعتی پایین بودند. در آن زمان، فرکانسهای سیگنال ساعت بهطور شایع در محدوده ۱۰۰ کیلو هرتز تا ۴ مگاهرتز بود که این سرعت، به میزان زیادی به دلیل سرعت ابزارهای سوئیچ مورد استفاده در داخل آنها، محدود میشد.[26]
پردازندههای ترانزیستوری

پیچیدگی طراحی پردازندهها، همزمان با آسان شدن ساخت ابزارهای الکترونیک کوچکتر و قابل اعتماد تر در نتیجهٔ افزایش تکنولوژیهای مختلف، افزایش یافت. اولین پیشرفت در نتیجه ابداع ترانزیستور حاصل شد. در طی دهههای ۱۹۵۰ و ۱۹۶۰، دیگر لازم نبود که برای ساخت پردازندههای ترانزیستوری از عناصر سوئیچ حجیم، نامطمئن، و شکننده همچون لامپهای خلاء و رلهها استفاده کرد.[27] با این پیشرفتها، پردازندههای پیچیدهتر و قابل اطمینان تر، بر روی یک یا چندین بورد مدار چاپی که حاوی اجزاء گسسته (منفرد) بودند، پیادهسازی شدند.
در سال ۱۹۶۴، شرکت آی بی ام، یک معماری رایانه به نام آی بی ام سیستم ۳۶۰ IBM System/360 ارائه کرد، که در مجموعه ای از کامپیوترهایی استفاده شد که قادر بودند برنامههای مشابهی را، با سرعتها و کارایی متفاوت اجرا کنند.[28] این نوآوری در آن زمان اهمیت چشمگیری داشت، زیرا اکثر کامپیوترهای الکترونیک، حتی آنهایی که توسط یک شرکت ساخته میشدند، با یکدیگر ناسازگار بودند. شرکت آی بی ام برای ارتقاء این نوآوری، از مفهوم یک ریز برنامه (یا همان ریز کد) استفاده کرد که هنوز کاربرد گستردهای در پردازندههای جدید دارد.[29] معماری System/360، آنقدر محبوب شد که برای دههها بازار رایانههای بزرگ را به دست گرفت، و هنوز هم توسط کامپیوترهای جدید مشابهی نظیر آی بی ام سری Z ادامه پیدا کردهاست.[30][31] در سال ۱۹۶۵، شرکت تجهیزات دیجیتال (Digital Equipment Corporation)، یک کامپیوتر تأثیرگذار دیگر را با هدف فروش علمی و تحقیقاتی ارائه کرد، که PDP-8 نام داشت.[32] کامپیوترهای ترانزیستوری مزایای منحصر به فرد متعددی در مقایسه با کامپیوترهای پیشین داشتند. ترانزیستورها علاوه بر افزایش دادن قابلیت اعتماد و کاهش مصرف انرژی، همچنین به پردازندهها این امکان را دادند تا با سرعتهای بسیار بالاتر کار کنند، زیرا زمان سوئیچ یک ترانزیستور، در مقایسه با یک لامپ خلأ یا رله کوتاهتر است.[33]
به واسطه افزایش قابلیت اطمینان و سرعت عناصر سوئیچ (که در حال حاضر تقریباً تماما ترانزیستور هستند)، سرعت ساعت پردازندهها در این زمان، به سادگی، به دهها مگاهرتز رسید.[34] علاوه بر این، در حالیکه ترانزیستورهای گسسته و پردازندههای مدار مجتمع استفادهٔ بسیار زیادی داشتند، طراحیهایی جدید با کارایی بالا، همچون پردازندههای برداری اس ام دی (تک دستورالعمل، چندین داده) شروع به ظهور کردند.[35] این طراحیهای تحقیقاتی ابتدایی، بعدها باعث ظهور دورهٔ ابررایانههای اختصاصی، نظیر ابررایانههای ساخته شده توسط شرکت Cray Inc و Fujitsu Ltd شد.[35]
سی پی یوهای مجتمع کوچک-مقیاس
در این دوره، روشی برای تولید تعداد زیادی ترانزیستور بهم متصل در یک فضای فشرده ابداع شد. مدار مجتمع این امکان را فراهم کرد تا تعداد زیادی ترانزیستور را بتوان بر روی یک دای (die) نیمه هادی یا همان chipتولید کرد. در
ابتدا فقط مدارهای دیجیتال غیر اختصاصی بسیار پایه ای همچون گیتهای NOR در داخل آی سیها کوچک سازی شدند.[36] بهطور کلی، پردازندههایی که مبتنی بر این آی سیهای «بلوک سازنده» هستند، ابزارهای «مجتمع کوچک-مقیاس» (small-scale integration) نام دارند. آی سیهای SSI، نظیر آی سیهایی که در کامپیوتر هدایت کننده آپولو استفاده شدند، معمولاً حاوی حداکثر دهها ترانزیستور بودند. برای ساخت یک پردازندهٔ کامل با استفاده از آی سیهای SSI نیاز به هزاران چیپ بود، با این حال، اینها در مقایسه با طراحیهای ترانزیستوری گسستهٔ پیشین، مصرف انرژی و فضای بسیار کمتری داشتند.[37]
سیستم ۳۷۰ آی بی ام، که به دنبال ۳۶۰ آی بی ام آمد، به جای ماژولهای ترانزیستوری-گسسته با تکنولوژی Solid Logic Technology، از آی سیهای SSI استفاده کرد.[38][39] سیستم PDP-8/I و KI10 PDP-10 متعلق به شرکت DEC نیز، ترانزیستورهای مورد استفاده در سیستمهای PDP-8 و PDP-10 را کنار گذاشت، و به سراغ آی سیهای SSI رفت[40]و سیستم خطی PDP-11 آن، که بسیار محبوب بود، در ابتدا توسط آی سیهای SSI ساخته شد، اما سرانجام با استفاده از اجزای LSI، در زمانی که این اجزا عملی شده بودند، پیادهسازی شد.
سی پی یوهای مجتمع بزرگ-مقیاس
ماسفت (metal-oxide-semiconductor field-effect transistor)، یا همان ترانزیستور ماس، توسط آقایان Mohamed Atalla و Dawon Kahng در آزمایشگاه Bell Labs، در سال ۱۹۵۹ اختراع شد و در سال ۱۹۶۰ ثبت شد.[41]این امر منجر به تولید مدار مجتمع MOS شد، که در سال ۱۹۶۰ توسط Atalla و در سال ۱۹۶۱ توسط Kahng مطرح شد[42]و سپس توسط Fred Heiman و Steven Hofstein در شرکت RCA، در سال ۱۹۶۲ تولید شد. ماسفت با داشتن مقیاس پذیری بالا[43]و مصرف انرژی بسیار کمتر[44] و تراکم بالاتر در مقایسه با ترانزیستورهای پیوند دوقطبی، امکان تولید مدارهای مجتمع با تراکم بالا را فراهم کرد.[45][46]
آقای Lee Boysel مقالات تأثیرگذاری را، از جمله یک «بیانیه» در سال ۱۹۶۷، که در آن توضیح میداد چگونه یک کامپیوتر بزرگ ۳۲ بیتی را با استفاده از تعداد نسبتاً کمی از مدارهای مجتمع مقیاس بزرگ بسازیم، منتشر کرد. تنها روش برای ساخت چیپهای LSI که دارای ۱۰۰ یا بیش از ۱۰۰ گیت بودند،[47][48]استفاده از فرایند تولید نیمه هادی اکسید فلز (PMOS , NMOS , CMOS) بود. با این حال، برخی شرکتها، همچنان پردازندهها را با استفاده از چیپهای منطق ترانزیستور-ترانزیستور (transistor–transistor logic) دوقطبی میساختند، زیرا ترانزیستورهای پیوند دوقطبی تا زمان دهه ۱۹۷۰ در مقایسه با تراشههای ماس سریع تر بودند (چند شرکت، هم چون Datapoint، تا اوایل دهه ۱۹۸۰، پردازندهها را با استفاده از چیپهای TTL میساختند).[48] در دههٔ ۱۹۶۰، آی سیهای ماس کندتر بودند و در ابتدا، فقط در مواردی که مصرف انرژی کمتربود، مفید بودند.[49][50] به دنبال ابداع تکنولوژی ماس بر مبنای دروازه سیلیکونی توسط Federico Faggin در شرکت Fairchild Semiconductor، آی سیهای MOS به میزان زیادی جایگزین TTL دو قطبی، به عنوان تکنولوژی استاندارد تراشه در اوایل دهه ۱۹۷۰ شدند.[51]
با پیشرفت تکنولوژی میکرو الکترونیک، ترانزیستورهای بیشتری در داخل آی سیها قرار داده شدند، که باعث کاهش تعداد آی سیهای مورد نیاز برای یک پردازنده شد. آی سیهای MSI و LSI، تعداد ترانزیستورها را به صدها و سپس هزاران عدد افزایش داد. در سال ۱۹۶۸، تعداد آی سیهای مورد نیاز برای ساخت یک پردازنده کامل، به تعداد ۲۴ آی سی از ۸ نوع کاهش پیدا کرد، که هر کدام حاوی تقریباً هزار ماسفت بودند.[52]اولین پیادهسازی سیستم PDP-11 به طریق LSI، با داشتن تفاوت بسیار با نسلهای قبلی SSI و MSI آن، حاوی یک پردازنده بود که فقط از چهار مدار مجتمع LSI تشکیل شده بود.[53]
ریزپردازندهها
پیشرفت در زمینه تکنولوژی مدار مجتمع ماس، منجر به ابداع ریز پردازنده در اوایل دههٔ ۱۹۷۰ شد.[54] از زمان ارائهٔ اولین ریزپردازندهٔ تجاری، یعنی اینتل ۴۰۰۴ در سال ۱۹۷۱، و اولین ریزپردازنده ای که بهطور گسترده مورد استفاده قرار گرفت، یعنی اینتل ۸۰۸۰ در سال ۱۹۷۴، این کلاس از پردازندهها، تقریباً بهطور کامل، تمام روشهای دیگر پیادهسازی پردازنده را از رده خارج کردهاند. تولیدکنندههای رایانههای بزرگ و مینی کامپیوترها در آن زمان، برنامههای تولید آی سی مالکیتی را آغاز کردند، تا معماریهای کامپیوتری قدیمی خود را ارتقا دهند و سرانجام، ریز پردازندههایی ابداع کردند که با مجموعهٔ دستورالعمل و همچنین با سختافزار و نرمافزار قدیمی آنها نیز سازگاری داشتند. با در نظر گرفتن پیشرفت و موفقیت همهگیر کامپیوترهای شخصی، در حال حاضر، اصطلاح سی پی یو تقریباً بهطور کامل به ریزپردازندهها اطلاق میشود. میتوان چندین سی پی یو (به نام هسته) را در یک چیپ پردازشی با هم ترکیب کرد.[55]
نسلهای قبلی پردازندهها، به شکل اجزای گسسته و آی سیهای کوچک متعدد در یک یا بیش از یک برد مدار پیادهسازی میشدند.[56] این در حالی است که، ریز پردازندهها، درواقع، پردازندههایی هستند که با استفاده از تعداد بسیار کمی از آی سیها (معمولاً فقط یکی) تولید میشوند.[57] در نتیجهٔ پیادهسازی روی یک دای، اندازهٔ کلی پردازندهها کوچکتر شد که منجر به افزایش سرعت سوئیچ شد، که دلیل آن، فاکتورهای فیزیکی نظیر کاهش ظرفیت خازنی پارازیتی بود.[58][59] این امر باعث شدهاست تا ریزپردازندههای همگام، دارای سرعتهای ساعتی با محدودهٔ دهها مگاهرتز تا چندین گیگاهرتز باشند. علاوه بر این، قابلیت ساخت ترانزیستورهای بسیار کوچک در یک آی سی، باعث افزایش پیچیدگی و تعداد ترانزیستورها در یک پردازشگر، به میزان چندین برابر، شد. این رویه ای که بهطور گسترده مشاهده میشود، تحت قانون مور توصیف میشود، که ثابت شدهاست، پیشبینی کننده ای نسبتاً دقیق برای رشد پیچیدگی پردازنده (و سایر آی سیها) تا سال ۲۰۱۶ بود.[60][61]
اگرچه پیچیدگی، اندازه، ساختار، و فرم کلی پردازندهها از سال ۱۹۵۰ بسیار تغییر کردهاست،[62] اما طراحی و عملکرد اساسی آنها زیاد تغییر نکردهاست. تقریباً تمام پردازندههای مرسوم امروزی را میتوان به شکل بسیار دقیقی، به فرم ماشینهای ذخیره کننده برنامه ای فون نویمان، توصیف کرد.[63] از آنجایی که قانون مور دیگر صدق نمیکند، نگرانیهایی پیرامون محدودیتهای تکنولوژی ترانزیستوری مدار مجتمع بهوجود آمدهاست. کوچک سازی بسیار زیاد دروازههای الکترونیک موجب شدهاست تا اثرات پدیدههایی نظیر، مهاجرت الکتریکی (electromigration) و نشت تحت-آستانه ای (subthreshold leakage) بسیار چشمگیرتر شوند.[64][65] این نگرانیهای جدیدتر، از جمله فاکتورهایی هستند که موجب شدهاند تا محققان به دنبال روشهای جدید محاسبه، نظیر کامپیوتر کوانتومی و همچنین توسعهٔ استفاده از موازی سازی و سایر روشهایی که مزایای مدل کلاسیک فون نویمان را افزایش میدهند، باشند.
هسته و فرکانس
همیشه تعداد هستهٔ بالاتر به معنای سریع تر بودن پردازنده نیست، زیرا مهمترین مؤلفه مطرح شده برای سرعت پردازنده، فرکانس کلاک پردازنده است. افزایش تعداد هستههای پردازنده، همیشه دلیل بر افزایش سرعت پردازش هسته نمیباشد چراکه هنوز هم چیپهایی هستند که تعداد هستهٔ بالایی دارند ولی از روش عملکرد پردازش موازی استفاده نمیکنند. سرعت پردازنده نشانگر تعداد عملی است که یک هسته میتواند در هر ثانیه انجام دهد.
واحد اندازهگیری فرکانس پردازنده، گیگاهرتز است که با علامت GHz نشان داده میشود. پسوند گیگا در زبان انگلیسی به معنی میلیارد است.[66] فرکانس پردازندهها با فرکانس پایه یا کلاک پایه (Base clock) شناخته میشود. پردازندههای جدید شرکتهای اینتل و AMD تا 4GHz فرکانس ساخته شدهاند.
طرز کار
طرز کار
کارکرد اساسی اکثر پردازنده، صرفه نظر از فرم فیزیکی آنها، اجرای مجموعه ای از دستورالعملهای ذخیره شدهاست که برنامه نام دارد. دستورالعملهایی که قرار است اجرا شوند، در نوعی حافظهٔ کامپیوتر ذخیره میشوند. تقریباً تمام پردازندهها در طی عملکرد خود، از سه مرحلهٔ واکشی، کد گشایی، و اجرا که در مجموع چرخهٔ دستورالعمل نامیده میشود، تبعیت میکنند.
بعد از اجرای یک دستورالعمل، کل فرایند تکرار میشود و چرخهٔ بعدی دستورالعمل، بهطور معمول، دستورالعمل بعدی را، در نتیجهٔ افزایش مقدار شمارنده برنامه، واکشی میکند. اگر یک دستورالعمل پرش اجرا شود، مقدار شمارندهٔ برنامه طوری تغییر میکند که آدرس دستورالعملی که به آن پرش انجام شدهاست، در آن ذخیره شود و اجرای برنامه بهطور نرمال ادامه پیدا میکند. در پردازندههای پیچیدهتر میتوان چندین دستورالعمل را بهطور همزمان واکشی، رمزگشایی، و اجرا کرد. در این قسمت، آنچه که توصیف میشود، بهطور کلی خط تولید RISC کلاسیک نام دارد که استفادهٔ زیادی در پردازندههای ساده در بسیاری از ابزارهای الکترونیک دارد (که معمولاً با نام میکروکنترلر شناخته میشوند) و به میزان زیادی نقش مهم حافظه نهان پردازنده را و همچنین مرحله واکشی خط تولید را نادیده میگیرد.
برخی دستورالعملها به جای اینکه دادهٔ حاصل را بهطور مستقیم تولید کنند، شمارنده برنامه را دستکاری میکنند. چنین دستورالعملهایی بهطور کلی، پرش نام دارند و موجب تسهیل اجرای رفتارهایی از برنامه، از جمله: حلقهها، اجرای شرطی برنامه (از طریق استفاده از یک پرش شرطی) و همچنین موجودیت توابع را تسهیل میکنند. در برخی پردازندهها، برخی دستورالعملها قادرند تا وضعیت بیتها را در یک رجیستر فلگ تغییر دهند. این فلگها را میتوان برای تأثیرگذاری روی رفتار یک برنامه استفاده کرد، زیرا معمولاً نشان دهنده نتایج عملیات مختلف هستند. برای مثال، در چنین پردازندههایی یک دستورالعمل «مقایسه»، دو مقدار را ارزیابی میکند و بیتهای موجود در رجیستر فلگ را ست میکند یا پاک میکند، که نشان میدهد کدام یک بزرگتر است و اینکه آیا آنها برابرند یا خیر. یکی از این فلگها را مجدداً میتوان توسط یک دستورالعمل پرش، برای تعیین جریان برنامه استفاده کرد.
واکشی
اولین مرحله واکشی (Fetch) نام دارد که در واقع وظیفهٔ استخراج یک دستورالعمل (که توسط تعدادی یا صفی از اعداد نشان داده میشود) را از حافظه برنامه بر عهده دارد. مکان دستورالعمل (آدرس) در حافظهٔ برنامه، توسط شمارنده برنامه (Program Counter یا PC، که در ریزپردازندههای x86 اینتل به آن «اشارهگر دستورالعمل» نیز گفته میشود) تعیین میشود، که عددی را ذخیره میکند که نشانگر آدرس دستورالعمل بعدی برای واکشی است. بعد از اینکه دستورالعمل واکشی شد، مقدار شمارندهٔ برنامه به میزان اندازهٔ دستورالعمل افزایش مییابد، تا آدرس دستورالعمل بعدی در توالی مورد نظر، در آن قرار گیرد. معمولاً دستورالعملی که قرار است واکشی شود، باید از یک حافظهٔ نسبتاً کند واکشی شود، که باعث میشود تا پردازنده منتظر بماند تا دستورالعمل برگردد. این مشکل به میزان زیادی در پردازندههای جدید، با استفاده از حافظههای نهان و معماریهای خط تولید، کمتر شدهاست.
رمزگشایی
دستورالعملی که توسط پردازنده از حافظه واکشی میشود، در واقع مشخص میکند که پردازنده قرار است چه کاری انجام دهد. در مرحلهٔ رمزگشایی (decoding) که توسط یک مدار با نام رمزگشاء دستورالعمل انجام میشود، دستورالعمل مورد نظر به سیگنالهایی تبدیل میشود که قسمتهای دیگر پردازنده را کنترل میکنند.
شیوهٔ تفسیر دستورالعمل، توسط معماری مجموعه دستورالعمل (ISA) پردازنده تعریف میشود. معمولاً، گروهی از بیتها (با نام، یک فضا) در داخل دستورالعمل، که آپ کد نام دارد، مشخص میکند که چه عملیاتی باید انجام شود و معمولاً، فضای باقی مانده، اطلاعات تکمیلی مورد نیاز برای عملیات مذکور، مثلاً عملوندها را فراهم میآورد. این عملوندها ممکن است به شکل یک مقدار ثابت (مقدار فوری) باشند، یا به شکل مکان یک مقدار باشند که ممکن است، این مکان یک رجیستر پردازنده یا یک آدرس حافظه باشد. انتخاب هر یک از این حالتها، از طریق حالتهای آدرس دهی انجام میشود.
در برخی طراحیهای پردازنده، رمزگشاء دستورالعمل به شکل یک مدار سختافزاری شش میخه و غیرقابل تغییر پیادهسازی میشود، در حالیکه در پردازندههای دیگر، برای ترجمهٔ دستورالعملها به مجموعههایی از سیگنالهای پیکربندی پردازنده، از یک ریز برنامه استفاده میشود. این سیگنالها در طی چندین پالس ساعت، بهطور متوالی اعمال میشوند. در برخی موارد، حافظه ای که برنامه را ذخیره میکند، قابل نوشتن مجدد است، که در نتیجه میتوان روش رمزگشایی دستورالعملها توسط پردازنده را تغییر داد.
اجرا
بعد از مراحل واکشی و رمزگشایی، مرحله اجرا(execution) انجام میشود. بسته به معماری پردازنده، این مرحله ممکن است حاوی یک عمل یا صفی از اعمال باشد. در طی هر عمل، قسمتهای مختلف پردازنده به صورت الکتریکی به گونهای متصل میشوند تا بتوانند تمام یا بخشی از عملیات مورد نظر را انجام دهند و سپس عمل، بهطور معمول، در پاسخ به یک پالس ساعت کامل میشود.
در بسیاری مواقع، نتایج حاصل، در داخل یک رجیستر داخلی پردازنده نوشته میشوند تا توسط دستورالعملهای بعدی به سرعت قابل دسترسی باشند. در سایر موارد، نتایج ممکن است در حافظه اصلی نوشته شوند که کندتر است اما ارزانتر و دارای ظرفیت بالاتر است.
برای مثال، اگر قرار باشد که یک دستورالعمل جمع اجرا شود، ورودیهای واحد محاسبه و منطق به یک جفت از منابع عملوند (اعدادی که قرار است جمع شوند) متصل میشوند، سپس ALU، طوری پیکربندی میشود تا یک عمل جمع را انجام دهد و حاصل جمع عملوندهای ورودیهای آن، در خروجی آن ظاهر میشود، و خروجی ALU، به محل ذخیره ای (مثلاً، یک رجیستر یا حافظه) که قرار است حاصل جمع را دریافت کند، متصل میشود. هنگامی که یک پالس ساعت رخ میدهد، این حاصل جمع، به محل ذخیره منتقل میشود و اگر حاصل جمع خیلی بزرگ باشد (یعنی بزرگتر از اندازه کلمهٔ خروجی ALU) باشد، آنگاه، یک فلگ سرریز محاسبه ای ست خواهد شد.
ساختار و پیادهسازی

در داخل مدار پردازندهٔ اصلی، مجموعهای از عملیات اساسی شش میخ (hardwired) شدهاست که مجموعهٔ دستورالعمل نام دارد. چنین عملیاتی ممکن است شامل مثلاً: جمع کردن یا تفریق کردن دو عدد، مقایسهٔ دو عدد، یا پرش به بخش دیگری از یک برنامه باشد. هر عملیات اساسی توسط ترکیب خاصی از بیتها با نام آپ کد زبان ماشین نمایش داده میشود. پردازندهٔ اصلی در زمان اجرای دستورالعملها در یک برنامه زبان ماشین، تصمیم میگیرد که چه عملیاتی را با کد گشایی آپ کد مورد نظر انجام دهد. یک دستورالعمل زبان ماشین کامل حاوی یک آپ کد، و در بسیاری موارد بیتهای دیگری است که آرگومانهای خاصی را برای عملیات مذکور مشخص میکنند (برای مثال اعدادی که باید با هم جمع شوند، در یک عملیات جمع). یک برنامهٔ زبان ماشین، مجموعه ای از دستورالعملهای زبان ماشین است که پردازنده اجرا میکند.
عملیات ریاضی واقعی برای هر دستورالعمل، توسط یک مدار منطقی ترکیبی در داخل پردازنده سی پی یو به نام واحد محاسبه و منطق یا همان ALU انجام میگیرد. بهطور کلی، یک پردازنده برای انجام یک دستورالعمل مراحل زیر را انجام میدهد: ابتدا آن را از حافظه واکشی میکند، سپس برای انجام یک عملیات از ALU استفاده میکند، و در نهایت نتیجه را در حافظه ذخیره میکند. علاوه بر دستورالعملهای ریاضیاتی اعداد صحیح و عملیات منطقی، دستورالعملهای ماشین مختلف دیگری وجود دارد، نظیر: دستورالعملهای مربوط به بارگیری داده از حافظه و ذخیرهسازی آن در حافظه، عملیات انشعاب و عملیات ریاضی روی اعداد ممیز شناور که توسط واحد ممیز شناور (FPU) در سی پی یو انجام میشود.[67]
واحد کنترل
واحد کنترل (control unit)، جزئی از سی پی یو است که عملیات پردازنده را هدایت میکند. این واحد به حافظهٔ کامپیوتر، واحد محاسبه و منطق، و ابزارهای ورودی و خروجی میگوید که چگونه به دستورالعملهایی که به پردازنده فرستاده شدهاند، پاسخ دهند.
این واحد با فراهم کردن سیگنالهای زمانبندی و کنترل، عملیات سایر واحدها را هدایت میکند. بیشتر منابع کامپیوتر، توسط واحد کنترل مدیریت میشود. واحد کنترل، جریان داده را بین سی پی یو و سایر ابزارها هدایت میکند. جان فون نویمن واحد کنترل را به عنوان بخشی از معماری فون نویمناضافه کرد. در طراحیهای کامپیوتری جدید، واحد کنترل معمولاً یک بخش داخلی از سی پی یو است که نقش و عملیات کلی آن، از اول تغییری نکردهاست.[68]
واحد محاسبه و منطق
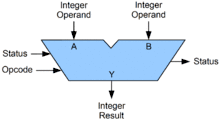
واحد محاسبه و منطق (The arithmetic logic unit)، یک مدار دیجیتال در داخل پردازنده است که عملیات محاسباتی و عملیات منطقی بیت به بیت را انجام میدهد. ورودیهای ALU عبارتند از: کلمات داده که قرار است روی آن عملیات انجام شود (با نام عملوند)، اطلاعات وضعیتی از عملیات قبلی، و یک کد از واحد کنترل که نشان میدهد کدام عملیات باید انجام شود. بسته به دستورالعملی که اجرا میشود، عملوندهای مورد نیاز ممکن است از رجیسترهای داخلی پردازنده یا حافظه خارجی بیایند، یا اینکه ثابتهایی باشند که توسط خود ALU تولید میشوند.
زمانی که تمام سیگنالها برقرار میشوند و در سرتاسر مدار منتشر میشوند، نتیجهٔ عملیات انجام گرفته در خروجیهای ALU ظاهر میشود. این نتایج شامل یک کلمهٔ داده میشود که ممکن است در یک رجیستر یا حافظه ذخیره شود، و همچنین شامل اطلاعات وضعیتی میشود، که بهطور معمول در یک رجیستر داخلی خاص سی پی یو که برای این هدف منظور شدهاست، ذخیره میشود.
واحد تولید آدرس
واحد تولید آدرس (Address generation unit) که گاهی واحد محاسبهٔ آدرس (address computation unit) نیز نامیده میشود، یک واحد اجرایی در داخل پردازنده است که آدرسهایی را که توسط سی پی یو برای دسترسی به حافظهٔ اصلی استفاده میشوند، محاسبه میکند. با محول کردن وظیفه محاسبات آدرس به یک مدار جداگانه که بهطور موازی با مابقی سی پی یو کار میکند، میتوان تعداد چرخههای مورد نیاز سی پی یو برای اجرای دستورالعملهای مختلف ماشین را کاهش داد، و بدین طریق عملکرد را بهبود داد.
پردازنده، در حالی که عملیات مختلفی را انجام میدهد، لازم است تا آدرسهایی را که برای واکشی داده از حافظه لازم هستند، محاسبه کند. برای مثال، باید قبل از اینکه سی پی یو بتواند داده را از مکانهای واقعی حافظه واکشی کند، مکانهای داخل-حافظه ای عناصر آرایه محاسبه شوند. این محاسبات تولید آدرس عبارتند از: عملیات محاسباتی مختلف برای اعداد صحیح نظیر، جمع کردن، تفریق کردن، عملیات باقیمانده(modulo) و جابجاییهای بیت. معمولاً محاسبه کردن یک آدرس حافظه، نیاز به بیش از یک دستورالعمل عمومی ماشین دارد، که لزوماً به سرعت کد گشایی و اجرا نمیشود. با اضافه کردن یک AGU به طراحی یک پردازنده و همچنین با ارائهٔ دستورالعملهای اختصاصی که از AGU استفاده میکنند، میتوان بار محاسبات مختلف تولید آدرس را از گردن مابقی سی پی یو برداشت و این محاسبات معمولاً به سرعت در یک چرخهٔ سی پی یو قابل اجرا هستند.
قابلیتهای یک AGU بستگی به یک سی پی یو خاص و معماری آن دارد؛ بنابراین، برخی AGUها عملیات بیشتری را برای محاسبهٔ آدرس، پیادهسازی و نمایان میکنند، در حالیکه برخی دیگر، علاوه بر این، دستورالعملهای اختصاصی پیشرفته ای را لحاظ میکنند که میتوانند روی عملوندهای متعدد به صورت همزمان اجرا شوند. علاوه بر این، برخی معماریهای سی پی یو، دارای شیوههای متعددی هستند تا بتوانند بیش از یک عملیات محاسبه آدرس را، به صورت همزمان انجام دهند و به این طریق، با بهرهگیری از ماهیت سوپراسکالر طراحیهای پیشرفتهٔ سی پی یو، کارایی را بالا ببرند. برای مثال، اینتل، AGUهای متعددی را در داخل ریزمعماریهای Sandy Bridge و Haswell خود ادغام میکند، که باعث میشود تا از طریق فراهم آوردن امکان اجرای چندین دستورالعمل دسترسی-به -حافظه به صورت موازی، پهنای باند زیر-سیستم حافظهٔ سی پی یو افزایش یابد.
واحد مدیریت حافظه
اکثر ریزپردازندههای پیشرفته (در کامپیوترهای رومیزی، لپ تاپ، و سرور) دارای یک واحد مدیریت حافظه(memory management unit) هستند که آدرسهای منطقی را به آدرسهای فیزیکی RAM ترجمه میکنند، و همچنین موجب حفاظت از حافظه و قابلیت صفحه بندی(paging) میشوند که برای حافظه مجازی مفید است. پردازندههای سادهتر، خصوصاً میکروکنترلرها، معمولاً فاقد واحد مدیریت حافظه هستند.
حافظه نهان (کش)
حافظه نهان (cache) پردازنده، در واقع، نوعی حافظهٔ نهان سختافزاری است که توسط واحد پردازش مرکزی یک کامپیوتر، برای کاهش میانگین هزینهٔ (زمان یا انرژی) دسترسی به داده موجود در حافظه اصلی استفاده میشود. یک حافظه نهان، در واقع یک حافظه کوچکتر و سریعتر است که به هستهٔ یک پردازنده نزدیکتر است و کپیهایی از دادههایی از مکانهای حافظه اصلی که مکرراً استفاده میشوند را ذخیره میکند. اکثر سی پی یوها، دارای کشهای مستقل و متنوع، از جمله: کشهای دستورالعمل و کشهای داده هستند، که در آن، کش داده معمولاً به شکل یک سلسله مراتب از سطوح بیشتر کش سازماندهی میشود (L1, L2, L3, L4, ...).
تمام پردازندههای جدید (سریع) (به استثناء موارد اختصاصی اندک)، دارای سطوح متعددی از کشهای پردازنده هستند. اولین پردازندهها که از کش استفاده کردند، فقط دارای یک سطح کش بودند که برخلاف کشهای سطح یک جدید، به دو قسمت: L1d (برای داده) و L1i (برای دستورالعمل) تقسیم نمیشدند. تقریباً تمام پردازندههای جدید که دارای کش هستند، دارای یک کش دو قسمتی در سطح یک هستند، و همچنین دارای کش سطح ۲ و در پردازندههای بزرگتر، کش سطح سه نیز هستند. سطح دوم کش معمولاً تقسیم نمیشود و به شکل یک مخزن مشترک برای کش تقسیم شدهٔ سطح ۱ عمل میکند. هر هسته از یک پردازنده چند هسته ای، دارای کش اختصاصی سطح ۲ است، که معمولاً بین هستهها به اشتراک گذاشته نمیشود. کش سطح ۳ و کشهای سطوح بالاتر، بین هستهها مشترک هستند و تقسیم نمیشوند. کش سطح ۴ در حال حاضر رایج نیست، و بهطور کلی، از جنس حافظهٔ دسترسی تصادفی پویا(DRAM) در یک چیپ یا دای مجزا قرار دارد و به شکل حافظه دسترسی تصادفی ایستا (SRAM) نمیباشد. بهطور تاریخی، این قضیه، در رابطه با سطح ۱ نیز صادق بود، این در حالی است که، چیپهای بزرگتر، امکان ادغام آن و بهطور کلی تمام سطوح کش را، به استثناء سطح آخر فراهم آوردهاند. هر سطح اضافه ای از کش معمولاً بزرگتر است و به شکل متفاوتی بهینهسازی میشود.
پردازنده برای به دست آوردن داده، ابتدا حافظه نهان را چک میکند و پس از نیافتن اطلاعات، به سراغ حافظههای دیگر از جمله RAM میرود. حافظه نهان میتواند دارای چند سطح (Level) باشد که با حرف L در مشخصات پردازنده نوشته میشود. معمولاً پردازندهها تا ۳ لایه حافظه نهان دارند که لایه اول (L1) نسبت به دوم (L2) و دوم نیز نسبت به سوم (L3) دارای سرعت بیشتر و حافظه کمتری است. زمانیکه پردازنده میخواهد دادهای را مورد پردازش قرار دهد ابتدا به نزدیکترین حافظه سطح حافظه نهان خود نگاه میکند تا در صورت موجود بودن آن دستورالعمل را پردازش کند. سطح ۱ نزدیکترین سطح به پردازنده است. بدین ترتیب اگر دادهها در نزدیکترین سطح حافظه پنهان پردازنده یافت شد، مورد پردازش قرار میگیرد و اگر پیدا نشد به ترتیب به سطحهای بعدی میرود و در نهایت اگر پیدا نشد به حافظه اصلی رجوع میکند. کش سطح ۳ بین تمام هستهها به اشتراک گذاشته میشود و به همین خاطر ظرفیت بیشتری دارد.
انواع دیگری از کشها نیز وجود دارند (که جزو «اندازه کش» مهمترین کشهایی که در بالا ذکر شد، محسوب نمیشوند)، مثلاً translation lookaside buffer، که بخشی از واحد مدیریت حافظه(MMU) در اکثر پردازندهها است.
کشها، معمولاً دارای اندازههایی به شکل توانهایی از دو هستند: ۴، ۸، ۱۶ و … کیبی بایت(KiB) یا مبی بایت (MiB) (برای کشهای بزرگتر، غیر سطح ۱) اگرچه IBM z13، دارای ۹۶ KiB کش دستورالعمل سطح ۱ است.
نرخ ساعت
اکثر سی پی یوها، مدارهای همگام هستند، به این معنی است که آنها از یک سیگنال ساعت برای هماهنگکردن عملیات متوالی خود استفاده میکنند. سیگنال ساعت توسط یک مدار نوسانگر خارجی تولید میشود، که تعداد ثابتی از پالسها را در هر ثانیه، به شکل یک موج مربعی متناوب تولید میکند. فرکانس پالسهای ساعت مشخص میکند که سی پی یو با چه سرعتی دستورالعملها را اجرا کند و در نتیجه، با افزایش سرعت ساعت، دستورالعملهای بیشتری توسط سی پی یو در هر ثانیه اجرا خواهند شد.
برای اطمینان از عملکرد صحیح پردازنده، باید مدت دورهٔ ساعت، بیشتر از حداکثر زمان مورد نیاز برای منتشر شدن تمام سیگنالها در سرتاسر سی پی یو باشد. با ست کردن طول دورهٔ ساعت به میزان بالاتری از بدترین حالت مدت زمان تأخیر انتشار، میتوانیم تمام سی پی یو و روشی را که برای انتقال داده برمبنای لبههای بالا رونده و پایین روندهٔ سیگنال ساعت استفاده میکند، طراحی کنیم. مزیت این کار این است که پردازنده بهطور چشمگیری سادهتر میشود؛ هم از نظر طراحی و هم از نظر تعداد اجزا. البته این مشکل نیز وجود دارد که تمام سی پی یو باید منتظر کندترین عناصر خود باشد، حتی اگر بخشهایی از سی پی یو بسیار سریع تر باشد. این محدودیت، به میزان زیادی به وسیلهٔ روشهایی که موازی گرایی سی پی یو را افزایش میدهند، جبران شدهاست.
با این حال، بهبودهای معماری به تنهایی قادر به حل تمام معایب پردازندههای تماماً همگام نیستند. برای مثال، سیگنال ساعت، درمعرض تاخیرهای ناشی از هرگونه سیگنالهای الکتریکی دیگر است. سرعتهای بالای ساعت در سی پی یوهایی که بهطور فزاینده پیچیده شدهاند، باعث میشود تا نگه داشتن سیگنال ساعت به شکل هم فاز در تمام بخشهای واحد، دشوار شود. این امر باعث شدهاست تا در بسیاری از سی پی یوهای جدید، چندین سیگنال ساعت مشابه فراهم شود، تا مانع از این شود که یک سیگنال منفرد آنقدر تأخیر پیدا کند که موجب اختلال عملکرد پردازنده شود. مشکل مهم دیگری که بدنبال افزایش چشمگیر سرعت ساعت به وجود میآید، مقدار گرمایی است که توسط پردازنده آزاد میشود. تغییر مداوم ساعت موجب میشود تا بسیاری از قطعات، صرف نظر از اینکه آیا در آن لحظه استفاده میشوند یا خیر، دچار سوئیچ شوند. بهطور کلی، قطعه ای که در حال سوئیچ است، انرژی بیشتری را در مقایسه با عنصری که در وضعیت بدون تغییر است، مصرف میکنند؛ بنابراین، با افزایش سرعت ساعت و در نتیجه افزایش مصرف انرژی پردازنده، نیاز به انتشار گرمای بیشتری از طریق روشهای خنک کنندهٔ پردازنده است.
یک روش برای مقابله با سوئیچهای بیمورد، کلاک گیتینگ (Clock Gating) نام دارد که عبارت است از خاموش کردن سیگنال ساعت برای اجزای بلا استفاده (یعنی، عملاً غیرفعال کردن آنها). با این حال، پیادهسازی این روش نیز معمولاً دشوار است و استفاده رایجی ندارد، به جز در طراحیهای بسیار کم مصرف. یک طراحی اخیر سی پی یو که قابل ذکر است و از روش کلاک گیتینگ استفادهٔ زیادی میکند، پردازنده زنون (Xenon) (که برحسب دستورالعملهای PowerPC شرکت IBM طراحی شده) در اکس باکس ۳۶۰ است که از این طریق، مصرف انرژی اکس باکس ۳۶۰ بهطور چشمگیری کاهش پیدا کردهاست.[69] شیوهٔ دیگر برای مقابله با بخشی از مشکل سیگنال ساعت سرتاسری، برداشتن سیگنال ساعت به صورت یکپارچه است. اگرچه برداشتن سیگنال ساعت سرتاسری، باعث پیچیدهتر شدن فرایند طراحی به طرق مختلف میشود، با این حال، طراحیهای ناهمگام (یا بدون ساعت) در مقایسه با طراحیهای مشابه همگام، برتری قابل توجهی از لحاظ مصرف انرژی و انتشار گرما دارند. اگرچه تا حدودی ناشایع است، اما پردازندههایی تماماً ناهمگام ساخته شدهاند که از سیگنال ساعت سرتاسری استفاده نمیکنند. دو مثال قابل ذکر در این رابطه عبارتند از: AMULET منطبق بر ARM و MIPS R3000 منطبق بر MiniMIPS.
برخی طراحیهای سی پی یو، به جای اینکه سیگنال ساعت را به صورت کلی حذف کنند، فقط بخشهایی از سیستم مورد نظر را ناهمگام میکنند، مثلاً از ALUهای ناهمگام همراه با خط تولید سوپراسکالر، برای دستیابی به برخی فواید عملکردی در محاسبات استفاده میکنند. اگرچه در مجموع، مشخص نیست که آیا طراحیهای تماماً ناهمگام میتوانند در حد قابل مقایسه یا بهتری در مقایسه با طراحیهای همگام عمل کنند یا خیر، اما مشخص شدهاست که حداقل در محاسبات ریاضی سادهتر، کارایی بالاتری دارند. این ویژگی، همراه با برتری آنها در مصرف انرژی و انتشار گرما، آنها را تبدیل به گزینهٔ مناسبی برای کامپیوترهای نهفته کردهاست.[70]
ماژول تنظیم کنندهٔ ولتاژ
بسیاری از سی پی یوهای جدید، دارای یک قطعهٔ مجزا برای مدیریت انرژی هستند، که در دای ادغام شدهاست، و وظیفه آن، تنظیم کردن منبع ولتاژ به صورت دلخواه برای مدار سی پی یو است. و بدین طریق، تعادلی را بین عملکرد و مصرف انرژی برقرار میکند.
محدوده اعداد صحیح
هر پردازنده مقادیر عددی را به شیوه خاصی نمایش میدهد. برای مثال برخی کامپیوترهای دیجیتال قدیمی اعداد را به شکل مقادیر سیستم عددی ده دهی (پایه ۱۰) نشان میدادند و برخی دیگر از کامپیوترها از نمایشهای غیر معمول نظیر، ternary (پایه ۳) استفاده کردهاند. تقریباً تمامی پردازندههای جدید، اعداد را به فرم باینری (دودویی) نشان میدهند، که در آن هر رقم به وسیله یک کمیت فیزیکی دو مقداری، نظیر ولتاژ «بالا» یا «پایین» نمایش داده میشود.

اندازه و دقت اعداد صحیحی که یک پردازنده میتواند نمایش دهد، مربوط به نمایش عددی میشود. در رابطه با یک پردازنده باینری، این معیارها به وسیلهٔ تعداد بیتهایی (رقمهای چشمگیر یک عدد صحیح کدگذاری شده به طریق باینری) که پردازنده میتواند در یک عملیات پردازش کند، اندازهگیری میشود، که در واقع، اندازهٔ کلمه، پهنای بیت، پهنای مسیر داده، دقت عدد صحیح، یا اندازه عدد صحیح نام دارد. اندازهٔ عدد صحیح یک پردازنده، محدودهٔ مقادیر صحیحی که پردازنده میتواند بهطور مستقیم روی آن عملیات انجام دهد را مشخص میکند. برای مثال، یک پردازنده ۸ بیتی میتواند بهطور مستقیم، اعداد صحیحی را که به شکل ۸ بیت نمایش داده شدهاند و دارای یک محدوده مقادیر اعداد صحیح گسسته به میزان ۲۵۶ (28) هستند، دستکاری کند.
محدوده اعداد صحیح، همچنین میتواند روی تعداد مکانهایی از حافظه که پردازنده میتواند به صورت مستقیم آدرس دهی کند تأثیر بگذارد (یک آدرس یک مقدار صحیح است که نشان دهنده یک مکان خاص از حافظه است). برای مثال اگر یک پردازنده باینری، از ۳۲ بیت برای نمایش یک آدرس حافظه استفاده کند، آنگاه میتواند بهطور مستقیم 28 مکان حافظه را آدرسدهی کند. برای دور زدن این محدودیت، و به دلایل مختلف دیگر، برخی پردازندهها از مکانیسمهایی (نظیر، bank switching) استفاده میکنند تا بتوانند حافظه بیشتری را آدرس دهی کنند.
پردازندههایی که دارای اندازههای کلمه بزرگتر هستند، نیاز به مداربندی بیشتر دارند و در نتیجه از لحاظ فیزیکی بزرگتر هستند و هزینهٔ بیشتری میبرند و انرژی بیشتری مصرف میکنند (و بنابراین گرمای بیشتری تولید میکنند). در نتیجه، در کاربریهای جدید، بهطور رایج از میکروکنترلرهای ۴ یا ۸ بیتی استفاده میشود، با وجود اینکه پردازندههایی با اندازهٔ کلمه بسیار بزرگتر (همچون ۱۶، ۳۲، ۶۴ و حتی ۱۲۸ وجود دارند). با این حال، زمانیکه نیاز به عملکرد بالا داریم، مزایای اندازهٔ بزرگتر کلمه (محدودههای داده بزرگتر و فضاهای آدرس بزرگتر) ممکن است بر معایب آن چیره شود. مسیرهای دادهٔ داخلی یک پردازنده میتواند باریکتر از اندازه کلمه باشد، تا اندازه و هزینه کاهش یابد. برای مثال، اگرچه IBM System/360، یک مجموعه دستورالعمل ۳۲ بیتی بود، اما System/360 Model 30 و Model 40 دارای مسیرهای دادهٔ ۸ بیتی در واحد محاسبه و منطق بودند، به گونهای که یک عمل جمع ۳۲ بیتی، نیازمند چهار چرخه بود که برای هر ۸ بیت یک عملوند، یک چرخه لازم بود. اگرچه مجموعه دستورالعمل Motorola 68، یک مجموعه دستورالعمل ۳۲ بیتی بود، اما Motorola 68000 و Motorola 68010 دارای مسیرهای داده ۱۶ بیتی در واحد محاسبه و منطق بود، به گونهای که یک عمل جمع ۳۲ بیتی نیازمند دو چرخه بود.
برای بهرهگیری از برخی از مزایای طولهای کمتر و بیشتر بیت، بسیاری از مجموعه دستورالعملها دارای پهناهای بیت متفاوتی برای دادهٔ صحیح و ممیز شناور هستند. در این حالت، پردازندههایی که از این مجموعه دستورالعملها استفاده میکنند، میتوانند پهناهای بیت متفاوتی برای قسمتهای مختلف کامپیوتر داشته باشند. برای مثال، مجموعه دستورالعمل System/360 شرکت آی بی ام اساساً ۳۲ بیتی بود، اما از مقادیر ممیز شناور ۶۴ بیتی هم پشتیبانی میکرد تا دقت و محدودهٔ بیشتری را در رابطه با اعداد ممیز شناور فراهم کند. مدل System/360 Model 65 دارای یک جمعکننده ۸ بیتی برای محاسبات دسیمال و باینری ممیز ثابت بود و همزمان دارای یک جمعکننده ۶۰ بیتی برای محاسبات ممیز شناور نیز بود.[71] بسیاری از طراحیهای بعدی پردازنده از پهنای بیت ترکیبی مشابهی استفاده میکنند. علیالخصوص، زمانی که پردازنده برای اهداف عمومی استفاده میشود، باید یک تعادل منطقی بین قابلیت صحیح و نقطه شناور برقرار شود.
موازی سازی
توصیفی که از عملکرد پایهای یک پردازنده در بخش قبلی شد، سادهترین فرمی است که یک پردازنده میتواند داشته باشد. این نوع از پردازنده که معمولاً آن را ساب اسکالر(subscalar) مینامند، یک دستور را روی یک یا دو قطعهٔ داده، در یک زمان اجرا میکند. این فرایند موجب یک ناکارآمدی ذاتی در پردازندههای ساب اسکالر میشود. از آنجایی که فقط یک دستور در یک زمان اجرا میشود، کل پردازنده باید منتظر بماند تا آن دستور کامل شود تا بتواند به دستور بعدی برود. در نتیجه پردازندههای ساب اسکالر، در رابطه با دستوراتی که بیش از یک پالس ساعت (چرخهٔ ساعت) برای اجرا شدن کامل طول میکشند، معطل میماند. حتی اضافه کردن یک واحد اجرایی دیگر بهبود زیادی روی عملکرد ندارد، و در این حالت به جای اینکه یک مسیر معطل باشد، دو مسیر معطل میماند و تعداد ترانزیستورهای بلااستفاده افزایش مییابد. این طراحی، که در آن منابع اجرایی پردازنده میتواند فقط یک دستور در یک زمان اجرا کند، قادر خواهد بود تا نهایتاً فقط به عملکردی در حد اسکالر (یک دستور در یک چرخهٔ ساعت) برسد. با این وجود عملکرد آن تقریباً همیشه ساب اسکالر (کمتر از یک دستور در یک چرخه) است.
تلاش برای رسیدن به عملکردی در حد اسکالر یا بهتر از آن منجر به پیدایش انواعی از روشهای طراحی شد که باعث میشود تا پردازنده، کمتر به صورت خطی و بیشتر به صورت موازی عمل کند. در هنگام استفاده از اصطلاح موازی گرایی برای پردازندهها، دو اصطلاح بهطور کلی، برای طبقهبندی این تکنیکهای طراحی استفاده میشود:
- موازی سازی در سطح-دستور العمل (instruction-level parallelism)، که هدف آن افزایش سرعت اجرای دستورالعملها در داخل یک پردازنده است (یا به عبارتی افزایش استفاده از منابع اجرایی روی همان چیپ (on-die)).
- موازی سازی در سطح-وظایف (task-level parallelism)، که هدف آن افزایش تعداد ریسمان ها یا فرایندهایی است که یک پردازنده میتواند بهطور همزمان اجرا کند.
موازی سازی در سطح دستورالعمل
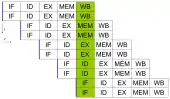
یکی از سادهترین روشهای مورد استفاده برای افزایش موازی گرایی این است که اولین مراحل واکشی و رمزگشایی دستورالعمل را پیش از اینکه اجرای دستورالعمل قبلی تمام شود، شروع کنیم. این روش سادهترین فرم یک تکنیک بنام خط لوله دستورالعمل (instruction pipelining) است و در تقریباً تمام پردازندههای عمومی جدید استفاده میشود. خط لوله دستورالعمل، با شکستن مسیر اجرا و تبدیل آن به مراحل جداگانه، باعث میشود تا در هر زمان بیش از یک دستورالعمل اجرا شود. این جدا کردن را میتوان با خط مونتاژ مقایسه کرد که در آن یک دستور در هر مرحله کاملتر میشود، تا اینکه کلا از خط خارج شود.
با این وجود، روش خط لوله، ممکن است موقعیتی را به وجود آورد که در آن نتایج عملیات قبلی برای کامل کردن عملیات بعدی لازم است. این وضعیت را معمولاً تقابل ناشی از وابستگی مینامند. برای جلوگیری از این وضعیت، باید توجه بیشتری شود تا در صورت رخ دادن این شرایط، بخشی از خط لوله دستورالعمل را به تأخیر بیاندازیم. بهطور طبیعی، برآورده کردن این شرایط نیازمند مداربندی اضافه است، بنابراین پردازندههای خط مونتاژی، پیچیدهتر از انواع ساب اسکالر هستند (البته، خیلی پیچیدهتر نیستند). یک پردازنده از نوع خط لوله، میتواند بسیار نزدیک به حد اسکالر شود، در این شرایط تنها مانع موجود وقفهها (دستورالعملی که بیش از یک چرخهٔ ساعتی در یک مرحله طول میکشد) هستند.
پیشرفت بیشتر در زمینهٔ ایدهٔ خط لوله، منجر به ابداع روشی شدهاست که زمان بیکاری اجزای پردازنده را حتی به میزان بیشتری کاهش میدهد. طراحیهایی که اصطلاحاً سوپراسکالر(superscalar) هستند شامل یک خط لوله دستورالعمل طولانی و چندین واحد اجرایی مشابه از جمله: واحدهای بارگزاری/ذخیرهسازی، واحدهای محاسبه و منطق، واحدهای ممیز شناور، و واحدهای تولید آدرس هستند.[72] در یک خط لوله سوپراسکالر، دستورالعملهای متعددی خوانده شده و به توزیع کننده ها(dispatcher) میروند، توزیع کننده تصمیم میگیرد که آیا دستورالعملهای مذکور میتوانند بهطور موازی (همزمان) اجرا شوند یا نه. در صورتی که پاسخ مثبت باشد، دستورالعملها در واحدهای اجرایی موجود توزیع (dispatch) میشوند. این کار باعث میشود تا چندین دستورالعمل بهطور همزمان اجرا شوند. بهطور کلی، هرقدر یک پردازندهٔ سوپراسکالر بتواند دستورالعملهای بیشتری را بهطور همزمان به واحدهای اجرایی در حال انتظار ارسال کند، دستورهای بیشتری در یک چرخهٔ مشخص اجرا میشوند.
بیشترین دشواری در طراحی یک معماری سوپراسکالر پردازنده مربوط به ساخت یک توزیعکنندهٔ مؤثر است. توزیع کننده، باید قادر باشد تا به سرعت و بدون اشتباه مشخص کند که آیا دستورالعملها میتوانند بهطور موازی اجرا شوند، و آنها را به شیوهای توزیع کند تا بیشترین واحدهای اجرایی ممکن را از بیکاری خارج کند. این امر نیازمند این است که خط لوله دستورالعمل بیشتر مواقع ممکن پر باشد و معماریهای سوپراسکالر را نیازمند مقادیر چشمگیری از حافظه نهان پردازنده(cache) میکند. همچنین، در این شرایط نیاز به تکنیکهای حیاتی پیشگیری از خطر همچون: پیشبینی انشعاب، اجرای حدسی، تغییر نام رجیستر، اجرای خارج از نوبت و حافظه تراکنشی، برای حفظ سطوح بالای کارایی داریم. پردازنده با تلاش برای پیشبینی کردن اینکه کدام شاخه یا مسیر در یک دستورالعمل شرطی انتخاب خواهد شد، میتواند تعداد دفعاتی را که تمام خط تولید باید معطل بماند تا یک دستورالعمل شرطی کامل شود، به حداقل برساند. اجرای خارج از نوبت تا حدودی ترتیب اجرای دستورالعملها را تغییر میدهد تا تاخیرهای ناشی از وابستگیهای داده را کاهش دهد. اجرای حدسی، با اجرا کردن بخشهایی از کد که ممکن است بعد از کامل شدن یک عملیات شرطی مورد نیاز نباشد، معمولاً موجب کمی افزایش در کارایی میشود. اجرای خارج از نوبت تا حدودی ترتیب اجرای دستورالعملها را تغییر میدهد تا تاخیرهای ناشی از وابستگیهای داده را کاهش دهد. همچنین، در مورد جریان یک دستورالعمل، جریان چندین داده- که در آن مقدار زیادی داده مشابه باید پردازش شود- پردازندههای جدید میتوانند بخشهایی از خط لوله را غیرفعال کنند تا، هنگامی که یک دستورالعمل به دفعات زیادی اجرا میشود، پردازنده بتواند مراحل واکشی و رمزگشایی را نادیده بگیرد و بنابراین باعث افزایش چشمگیر کارایی در مواقع خاصی، خصوصاً در موتورهای برنامه ای یکنواخت همچون نرمافزار ایجاد ویدئو و پردازش تصویر شود.
در مواردی که بخشی از پردازنده سوپر اسکالر است و بخشهایی نیست، آن بخشی که سوپراسکالر نیست، دچار افت عملکرد به دلیل معطلیهای زمانبندی میشود. اینتل پنتیوم P5 دارای دو واحد محاسبه و منطق سوپر اسکالر بود که هر کدام از آنها میتوانستند یک دستورالعمل را در هر چرخه ساعت بپذیرند، اما واحد ممیز شناور آن نمیتوانست یک دستورالعمل را در هر چرخه ساعت بپذیرد؛ بنابراین، ALU در رابطه با اعداد صحیح سوپراسکالر بود، اما در رابطه با ممیز شناور سوپراسکالر نبود. معماری نسل بعد از P5، یعنی P6 قابلیتهای سوپراسکالر را به ویژگیهای ممیز شناور خود اضافه کرد و بنابراین باعث افزایش چشمگیر در عملکرد دستورالعمل ممیز شناور شد. هم طراحی خط لوله ساده و هم طراحی سوپراسکالر، با فراهم آوردن امکان کامل کردن اجرای دستورالعملها با سرعتی فراتر از یک دستورالعمل در هر چرخه ساعت(ILP) برای یک پردازنده منفرد، موازی گرایی سطح دستورالعمل را در سی پی یو افزایش میدهند. اکثر طراحیهای جدید پردازنده حداقل تا حدودی سوپراسکالر هستند و تقریباً تمام پردازندههای عمومی که در دهه اخیر طراحی شدهاند سوپراسکالر هستند. در سالهای بعدی، بخشی از تأکید در طراحی کامپیوترهای دارای سطوح بالای موازی گرایی در سطح دستورالعمل، از سختافزار پردازنده دور شده و بر روی رابط نرمافزاری یا همان معماری مجموعه دستورالعمل (ISA) متمرکز شدهاست. رویکرد کلمه دستورالعمل بسیار طولانی (VLIW) باعث میشود تا مقداری از موازی گرایی در سطح-دستورالعمل به صورت ضمنی و مستقیماً توسط نرمافزار انجام گیرد، که منجر به کاهش بار کاری پردازنده برای افزایش ILP میشود و بدین گونه پیچیدگی طراحی کاهش یابد.
موازی گرایی در سطح وظایف
رویکرد دیگر برای بهبود کارایی، اجرای چندین ریسمان یا فرایند به صورت موازی است. این بخش از حوزهٔ تحقیقات را رایانش موازی گویند.[73] در تقسیمبندی فلین، این رویکرد جریان چندین دستورالعمل، جریان چندین داده (multiple instruction stream, multiple data stream) نام دارد.[74]
یک تکنولوژی که با این هدف استفاده شد، چند-پردازشی (multiprocessing) بود.[75] در ابتدا، فرم محبوب این تکنولوژی، چند پردازشی متقارن (symmetric multiprocessing) نام داشت که در آن، تعداد اندکی پردازنده یک نمای یکپارچه از سیستم حافظه خود را به اشتراک میگذارند. در این طرح بندی، هر سی پی یو دارای سختافزار اضافه برای حفظ یک نمای به روز متداوم از حافظه است. با اجتناب از نماهای کهنهٔ حافظه، این پردازندهها میتوانند روی یک برنامه همکاری کنند و برنامهها میتوانند از یک پردازنده به پردازندهٔ دیگر مهاجرت کنند. برای افزایش تعداد پردازندههای همکاری کننده به بیش از تعداد معدود، طرحبندیهایی نظیر: دسترسی به حافظه به شکل غیر-یکپارچه (non-uniform memory access) و پروتکلهای یکپارچه مبتنی بر-دایرکتوری (directory-based coherence protocols) در در دهه ۱۹۹۰ ارائه شدند. سیستمهای چند فرایندی متقارن، دارای تعداد کمی پردازندهها هستند، در حالیکه سیستمهای دسترسی به حافظه بهشکل غیر یکپارچه، با هزاران پردازنده ساخته شدهاند. در ابتدا، چند-پردازشی، با استفاده از چندین پردازندهٔ مجزا و بوردهایی برای پیادهسازی اتصالات بین آنها، ساخته شد. هنگامی که پردازندهها و اتصالات بین آنها تماماً روی یک چیپ منفرد پیادهسازی میشوند، این تکنولوژی را چند-پردازشی سطح-تراشه (chip-level multiprocessing) مینامند و تک-تراشهٔ مورد نظر را، یک پردازندهٔ چند هسته ای مینامند.
بعداً مشخص شد که موازی گرایی ظریف تر، میتواند با یک برنامه منفرد وجود داشته باشد. یک برنامهٔ منفرد ممکن است دارای چندین ریسمان (یا تابع) باشد، که میتوان آنها را به صورت مجزا یا موازی اجرا کرد. برخی از قدیمیترین موارد این تکنولوژی، فرآیندهای ورودی-خروجی همچون دسترسی-مستقیم-به-حافظه را به صورت یک ریسمان جدا از ریسمان محاسباتی، پیادهسازی میکردند. یک رویکرد کلی تر برای این تکنولوژی، در دهه ۱۹۷۰ ارائه شد که در آن، سیستمها طوری طراحی میشدند تا چندین ریسمان محاسباتی را به شکل موازی اجرا کنند. به این تکنولوژی، چندریسمانی (multi-threading) میگویند. این رویکرد، در مقایسه با رویکرد چند-پردازشی به صرفه تر است، زیرا فقط تعداد اندکی از بخشهای یک پردازنده برای پشتیبانی از چند ریسمانی باید تکثیر شوند، در حالیکه برای چند-پردازشی، باید کل پردازنده تکثیر شود. در رویکرد چند-ریسمانی، واحدهای اجرایی و سیستم حافظه (از جمله کشها)، در بین چندین ریسمان مشترک هستند. مشکل رویکرد چند-ریسمانی این است که پشتیبانی سختافزاری برای چند-ریسمانی در مقایسه با چند-پردازشی، برای نرمافزار نمایان تر است؛ بنابراین، نرمافزارهای ناظر همچون سیستم عامل، برای پشتیبانی از چند ریسمانی باید متحمل تغییرات زیادی شوند. یک نوع از چند ریسمانی که پیادهسازی شد، چند ریسمانی غیر همزمان نام دارد که در آن، یک ریسمان تا زمانی اجرا میشود که مجبور شود برای برگشتن داده از حافظه خارجی معطل شود، که در این هنگام، سی پی یو بلافاصله به ریسمان دیگری که آماده اجرا است تعویض زمینه میکند. این تعویض معمولاً، در یک چرخه ساعت پردازنده انجام میگیرد؛ مثلاً سیستم UltraSPARC از این روش استفاده میکند. نوع دیگری از چند ریسمانی، چند ریسمانی همزمان نام دارد، که در آن، دستورالعملهای مربوط به چندین ریسمان، به صورت موازی در داخل یک چرخه ساعت پردازنده اجرا میشوند.
به مدت چندین دهه، از ۱۹۷۰ تا اوایل ۲۰۰۰، در طراحی پردازندههای عمومی با کارایی بالا، تمرکز بیشتر روی دستیابی به موازی گرایی بالا در سطح-دستورالعمل، از طریق تکنولوژیهایی نظیر: خط لوله، حافظههای نهان، اجرای سوپراسکالر، اجرای خارج از نوبت و … بود. این روند، منجر به تولید پردازندههای بزرگ و پرمصرف نظیر اینتل پنتیوم ۴ شد. در اوایل دههٔ ۲۰۰۰، به دلیل رشد ناسازگاری بین فرکانسهای اجرایی پردازنده و فرکانسهای اجرایی حافظه و همچنین افزایش روزافزون تولید گرما توسط پردازنده که ناشی از تکنیکهای اختصاصی موازی گرایی در سطح-دستورالعمل بود، طراحان پردازنده دیگر قادر به دستیابی به کاراییهای بالاتر با استفاده از تکنیکهای ILP نبودند.
بعد از آن، طراحان پردازنده، از ایدههای بازار رایانههای تجاری، همچون فرایند تراکنش که در آن، مجموع کارایی چندین برنامه یا همان رایانش توان عملیاتی(throughput computing)، مهمتر از عملکرد یک ریسمان یا یک فرایند بود، استفاده کردند. همه گیر شدن طراحیهای پردازندههای دو هستهای و چند هسته ای و بهطور قابل ذکر، شباهت طراحیهای جدید اینتل به معماری کمتر سوپراسکالر P6، گواه بر این قضیه است. طراحیهای بعدی در خانوادههای متنوعی از پردازندهها، نمایانگر چند پردازشی در سطح-چیپ (CMP) بودند، از جمله: x86-64 Opteron وAthlon 64 X2 و SPARC UltraSPARC T1 و POWER4 و POWER5 IBM و همچنین چندین پردازندهٔ کنسول بازی ویدیویی، نظیر طراحی سه هسته ای PowerPC اکس باکس ۳۶۰ و ریزپردازنده سلولی ۷ هسته ای پلی استیشن ۳.
موازی گرایی در سطح-داده
یک مثال بهطور فزاینده مهم، اما کمتر رایج از پردازندهها (و در واقع بهطور کلی، رایانش) به موازی گرایی داده مربوط میشود. پردازندههایی که پیش تر در رابطه با آنها صحبت کردیم، تماماً از نوع اسکالر بودند. همانطور که نام آنها نشان میدهد، پردازندههای برداری با قطعات متعددی از داده در زمینه یک دستورالعمل مرتبط هستند، در حالیکه پردازندههای اسکالر، با یک قطعه از داده برای هر دستورالعمل سر و کار دارند. با استفاده از طبقهبندی فلین (Flynn's taxonomy)، این دو روش سر و کار با دادهها، بهطور کلی به ترتیب، جریان یک دستورالعمل، روی جریان چندین داده (single instruction stream, multiple data stream) و جریان یک دستورالعمل، روی جریان یک داده (single instruction stream, single data stream) نامیده میشود. عمده بهره بری در ساخت پردازندههایی که با بردارهای داده سر و کار دارند، در بهینهسازی وظایفی است که در آنها نیاز است تا برخی اعمال (برای مثال، یک جمع یا یک ضرب برداری) روی مجموعهٔ بزرگی از داده انجام شود. برخی مثالهای کلاسیک از این نوع وظایف عبارتند از: اپلیکیشنهای چند رسانهای (تصویر، ویدئو و صدا) و همچنین، انواع مختلفی از وظایف علمی و مهندسی. درحالی که یک پردازنده اسکالر باید تمام فرایند واکشی، رمزگشایی، و اجرای هر دستورالعمل و مقدار را در مجموعه ای از دادهها کامل کند، اما پردازنده برداری میتواند یک عملیات منفرد را روی مجموعه نسبتاً بزرگی از داده، فقط با یک دستورالعمل انجام دهد. این حالت، فقط زمانی امکانپذیر است که اپلیکیشن مورد نظر نیاز به مراحل متعددی دارد که عملیات مشابهی را روی مجموعه بزرگی از داده انجام میدهند.
بسیاری از پردازندههای برداری ابتدایی نظیر Cray-1، تقریباً به صورت کامل مربوط به تحقیقات علمی و کاربردهای رمزنگاری بودند. با این وجود، از آنجایی که چند رسانهای به میزان زیادی به سمت دیجیتال رفتهاست، نیاز به فرمی از SIMD در پردازندههای عمومی بیشتر شدهاست. کمی بعد از اینکه واحدهای ممیز شناور تبدیل به بخش ثابتی از پردازندههای عمومی شدند، اختصاص و پیادهسازی واحدهای اجرایی SIMD نیز در پردازندههای عمومی شروع شد. بعضی از این واحدهای اختصاصی SIMD نظیر:Multimedia Acceleration eXtensions در شرکت HP و MMX در شرکت اینتل فقط مربوط به اعداد صحیح میشد، که نوعی محدودیت قابل توجه برای برخی توسعهدهندگان نرمافزار بود، زیرا بسیاری از اپلیکیشنهایی که از SIMD سود میبرند، اساساً با اعداد ممیز شناور سر و کار دارد. بهطور روزافزون، توسعه دهندگان نرمافزار، این طراحیهای ابتدایی را اصلاح و به فرم واحدهای اختصاصی SIMD پیشرفتهٔ جدید بازسازی کردند، که معمولاً بخشی از یک معماری مجموعه دستورالعمل است. مثالهای مهمی از این موارد جدید عبارتند از: Streaming SIMD Extensions از شرکت اینتل و PowerPC-related AltiVec (یا همان VMX).
پردازندههای مجازی
رایانش ابری میتواند به شکل تقسیمبندی عملیات پردازنده مابین واحدهای پردازش مرکزی مجازی (virtual central processing units) باشد.[76] یک میزبان، معادل مجازی یک ماشین فیزیکی است که روی آن، یک سیستم مجازی عمل میکند.[77] زمانی که چندین ماشین فیزیکی با یکدیگر کار میکنند و به صورت یکپارچه مدیریت میشوند، این رایانش گروهی و منابع حافظه یک خوشه(cluster) را به وجود میآورد. در برخی سیستمها، این امکان وجود دارد تا به صورت پویا، از خوشه کم کنیم یا به آن اضافه کنیم. منابع موجود در یک میزبان و سطح خوشه را میتوان به مخازن منبع با اجزای ظریف(fine granularity) تقسیم کرد.
عملکرد
عملکرد یا سرعت یک پردازنده بستگی به فاکتورهایی از جمله سرعت ساعت (بهطور کلی، به صورت مضربهایی از هرتز داده میشود) و تعداد دستورالعملها در هر کلاک (instructions per clock, IPC) دارد، که مجموعاً با یکدیگر، معیار تعداد دستورالعملهای انجام شده در هر ثانیه(instructions per second, IPS) را تشکیل میدهند.[78] بسیاری از مقادیر IPS گزارش شده، نشان دهند ی نرخ اجرای «حداکثری» بر روی توالیهای دستورالعمل ساختگی با انشعابات معدود هستند، در حالیکه بار کاری واقعی، شامل ترکیبی از دستورالعملها و اپلیکیشنهایی میشود که مدت زمان اجرای برخی از آنها نسبت به بقیه بیشتر است. کارایی سلسله مراتب حافظه نیز به میزان زیادی روی کارایی پردازنده تأثیر میگذارد. این موضوع به ندرت در محاسبات میپس لحاظ شدهاست. به خاطر این مشکلات، تستهای استاندارد مختلفی که معمولاً برای این هدف محک(benchmark) نامیده میشوند- همچون SPECint- ابداع شدهاند، تا بتوانند کارایی واقعی را در موارد رایج اندازهگیری کنند.
کارایی پردازش کامپیوترها، با استفاده از پردازندههای چند هسته ای که اساساً اتصال دو یا بیش از دو پردازندهٔ مجزا (با نام هستهها، در این زمینه) در یک مدار مجتمع است، افزایش مییابد.[79] بهطور ایدهآل، یک پردازندهٔ دو هسته ای تقریباً قدرت معادل دو برابر یک پردازنده تک هستهای دارد، اما در واقعیت، افزایش کارایی بسیار کمتر از این است و حدود تقریباً ۵۰٪ است که دلیل آن، الگوریتمهای نرمافزاری و پیادهسازیهای ناکامل است.[80] افزایش تعداد هستهها در یک پردازنده (یعنی دو هسته ای، چهار هسته ای و …) موجب افزایش میزان بار کاری قابل انجام توسط پردازنده میشود. این بدان معنی است که این پردازندهها میتوانند وقایع ناهمگام، وقفهها و … را که در حجم زیاد میتوانند اثرات مخربی روی عملکرد پردازنده داشته باشند، مدیریت کنند. این هستهها را میتوان به شکل طبقات مختلف در یک ساختمان پردازش در نظر گرفت که هر طبقه یک وظیفهٔ متفاوت را انجام میدهد. گاهی این هستهها، در زمانی که یک هسته به تنهایی برای مدیریت اطلاعات کافی نباشد، میتوانند کاری مشابه با هستههای مجاور خود انجام دهند.
به دلیل قابلیتهای خاص پردازندههای جدید همچون: چند-ریسمانی همزمان و فناوری Uncore، که شامل اشتراک گذاری منابع واقعی پردازنده، در کنار میل به افزایش بهرهوری میشود، نظارت کردن بر سطوح کارایی و میزان استفاده از سختافزار بهتدریج، تبدیل به یک عمل پیچیدهتر شدهاست.[81] در نتیجه برخی پردازندهها، منطق سختافزاری اضافهای را پیادهسازی میکنند که کار آن نظارت بر میزان استفادهٔ واقعی از قسمتهای مختلف پردازنده است و میتوانند شمارندههای مختلفی را برای نرمافزار فراهم میکنند؛ به عنوان: مثال تکنولوژی Performance Counter Monitor اینتل.[82]
اورکلاک
بالا بردن میزان نرخ زمانی کلاک و که سبب تولید هشریت (میزان محاسبه اطلاعات توسط پردازنده در واحد زمان است)، بیشتر در واحد زمان و انجام سریع تری محاسبه در بازه زمانی میشود. پردازندههایی که قفلشان بازگشایی شده باشد را میتوان اورکلاک کرد و مزیت اورکلاک، انجام سریع تر پردازش و رندرهای سنگین توسط پردازنده است. مضرات اورکلاک بالا رفتن دمای پردازنده برای محاسبه و در نتیجه استفاده مداوم سبب پایین آمدن عمر پردازش گر میشود.[83] عمل Overclocking نیازمند دانش کافی در زمینه سختافزار میباشد و هرگونه اقدام نادرست، آسیبهای جبران ناپذیری به پردازندهها وارد میکند. تنها پردازندههایی اورکلاک میشوند که قابلیت اورکلاک شدن را در پسوند خود داشته باشند.
پردازنده سرور

این نوع پردازندهها از توانمندی بالاتری نسبت به پردازندههای معمولی خود برخوردار است.
زیآن (Xeon) نامی است که اینتل بر روی پردازندههای مخصوص به سرور گذاشته که اولین زیآن در سال ۱۹۹۸ به بازار عرضه شد. پردازندههای زیآن با بهرهگیری از فناوری فراریسمانی که اجازه میدهد یک تراشه همزمان دو ریسمان را با هم اجرا کند، راندمان بهتری ارایه میکنند.[84]
در هر فعالیت یا ایجاد یا اصلاحی در سرور، پردازنده سرور در حالت پردازش خواهد بود.
شرکتهای تولیدکننده
گاهی بر روی پردازندهها نام شرکت سازنده به صورت کامل و گاهی به صورت علائم اختصاری مخصوص شرکت مشخص میشود. شرکتهای تولیدکننده پردازنده، هرساله پردازندههای قدرتمندی برای کاربران عادی و گیمرها ارائه میشوند. پیچیدگی طراحی پردازندهها همزمان با افزایش سریع فناوریهای متنوع که ساختارهای کوچکتر و قابل اطمینان تری را در وسایل الکترونیک باعث میشد، افزایش یافت.
اینتل
شرکت اینتل در سال ۱۹۶۸ توسط رابرت نویس و گوردون مور راهاندازی شد. این شرکت مبدع فناوری ریزپردازندههای X۸۶ است. اینتل در اواسط دهه ۱۹۷۰ میلادی، یکی از قویترین تراشهها یعنی تراشه ۸۰۸۶ را به بازار عرضه کرد. این تراشهها تحولی عظیم در فناوری ریز پردازندهها ایجاد کردند. دفتر مرکزی این شرکت در شهر سانتا کلارا، کالیفرنیا قرار دارد. در سال ۲۰۰۸ بود که شرکت اینتل (Intel) با معرفی معماری نِهِیلِم (Nehalem) پردازندههای سری اینتل کور را به بازار معرفی کرد. روند نامگذاری با اعداد تا زمان ظهور سری پنتیوم ادامه داشت و بعد از آن از نام اختصاصی استفاده شد مانند: Celeron, pentium, Duron, Xeon, Athlon, phenom و …
از آن سال تا به امروز شرکت اینتل همواره پردازندههای جدید خود را با معماری بروزتر ولی با همان غالب Core i همراه با شمارهای بعداز حرف i معرفی میکند. پردازندههای Core i9 برای رقابت با پردازندههای تردریپر شرکت ایامدی وارد بازار شدهاند. این پردازندهها، اولین سری جدید محصولات «Core i» طی ۱۰ سال اخیر هستند. پردازندههای Core i9، پنجمین سری از خانوادهٔ پردازندههای رایانه خانگی هستند. پردازندههای قدرتمند اینتل ۱۸ هستهای و ۱۶ هستهای هستند.[85]
ایامدی
شرکت اِیاِمدی در سال ۱۹۶۹ و در ایالت کالیفرنیا شروع به کار کرد. ایامدی یکی از بزرگترین رقیبان این شرکت، که پا به پای اینتل پردازندههای خود را معرفی و عرضه میکند. ایامدی برای جذب مشتری بیشتر و در دست گرفتن بازار پردازندههای گرافیکی و مرکزی، سیاست کاهش قیمت را استفاده کرد و با این روش سعی در برتری نسبت به رقبا دارد. امروزه پردازندههای رایزن شرکت ایامدی پردازندههایی با تعداد ۳۲ هسته هستند.[86]
نسلها
پردازندهها بسته به تنوع در مدل و عملکرد آنها دارای مدلهای مختلفی میباشند. معمولاً هر گاه یک تغییر اساسی در ساختار یا پردازنده به وجود آمدهاست نسل جدیدی برای آن نام گذاری شدهاست. معمولاً نسلهای مختلف پردازندهها را با نام، علائم یا شمارههای مختلف نشان میدهند. شرکتهای سازنده پردازنده تولیدات خود را بر اساس یک روش استاندارد نام گذاری میکنند. هر کدام از نسلهای پردازنده دارای مدلهای مختلفی میباشد که دارای مشخصات متفاوت میباشند.[87] همچنین هر قسمت از نام یک پردازنده، نشان دهنده جزئیاتی از ساختار آن میباشد.
بازار تولید تراشه
به دنبال دنیاگیری کووید ۱۹ بسیاری از کارخانههای تولیدی بهصورت موقت تعطیل شدند و همین موضوع باعث شدهاست. کمبود تراشه روی صنایع مختلفی اثر گذاشته که یکی از مهمترین آنها صنعت گوشی هوشمند است.[88] اپل، سامسونگ و هواوی بزرگترین خریداران تراشه در سال ۲۰۲۰ بودهاند. میزان خرید هواوی به علت تحریمهای ایالات متحده آمریکا در مقایسه با سال ۲۰۱۹ در حدود ۲۳ درصد کمتر شدهاست.[89]
جستارهای وابسته
منابع
مشارکتکنندگان ویکیپدیا. «Central processing unit». در دانشنامهٔ ویکیپدیای انگلیسی، بازبینیشده در ۱۵ آوریل ۲۰۲۱.
- Kuck, David (1978). Computers and Computations, Vol 1. John Wiley & Sons, Inc. p. 12. ISBN 978-0-471-02716-4.
- Liebowitz, Kusek, Spies, Matt, Christopher, Rynardt (2014). VMware vSphere Performance: Designing CPU, Memory, Storage, and Networking for Performance-Intensive Workloads. Wiley. p. 68. ISBN 978-1-118-00819-5.
- Regan, Gerard (2008). A Brief History of Computing. p. 66. ISBN 978-1-84800-083-4. Retrieved 26 November 2014.
- Weik, Martin H. (1955). "A Survey of Domestic Electronic Digital Computing Systems". Ballistic Research Laboratory.
- Weik, Martin H. (1961). "A Third Survey of Domestic Electronic Digital Computing Systems". Ballistic Research Laboratory.
- "Bit By Bit". Haverford College. Archived from the original on October 13, 2012. Retrieved August 1, 2015.
- "First Draft of a Report on the EDVAC" (PDF). Moore School of Electrical Engineering, University of Pennsylvania. 1945.
- Stanford University. "The Modern History of Computing". The Stanford Encyclopedia of Philosophy. Retrieved September 25, 2015.
- "ENIAC's Birthday". The MIT Press. February 9, 2016. Retrieved October 17, 2018.
- Enticknap, Nicholas (Summer 1998), "Computing's Golden Jubilee", Resurrection, The Computer Conservation Society (20), ISSN 0958-7403, retrieved 26 June 2019
- "The Manchester Mark 1". The University of Manchester. Retrieved September 25, 2015.
- "The First Generation". Computer History Museum. Retrieved September 29, 2015.
- "The History of the Integrated Circuit". Nobelprize.org. Retrieved September 29, 2015.
- Turley, Jim. "Motoring with microprocessors". Embedded. Retrieved November 15, 2015.
- "Mobile Processor Guide – Summer 2013". Android Authority. 2013-06-25. Retrieved November 15, 2015.
- "Section 250: Microprocessors and Toys: An Introduction to Computing Systems". The University of Michigan. Retrieved October 9, 2018.
- "ARM946 Processor". ARM. Archived from the original on 17 November 2015.
- "Konrad Zuse". Computer History Museum. Retrieved September 29, 2015.
- "Timeline of Computer History: Computers". Computer History Museum. Retrieved November 21, 2015.
- White, Stephen. "A Brief History of Computing - First Generation Computers". Retrieved November 21, 2015.
- "Harvard University Mark - Paper Tape Punch Unit". Computer History Museum. Retrieved November 21, 2015.
- "What is the difference between a von Neumann architecture and a Harvard architecture?". ARM. Retrieved November 22, 2015.
- "Advanced Architecture Optimizes the Atmel AVR CPU". Atmel. Retrieved November 22, 2015.
- "Switches, transistors and relays". BBC. Archived from the original on 5 December 2016.
- "Introducing the Vacuum Transistor: A Device Made of Nothing". IEEE Spectrum. 2014-06-23. Retrieved 27 January 2019.
- What Is Computer Performance?. The National Academies Press. 2011. doi:10.17226/12980. ISBN 978-0-309-15951-7. Retrieved May 16, 2016.
- "1953: Transistorized Computers Emerge". Computer History Museum. Retrieved June 3, 2016.
- "IBM System/360 Dates and Characteristics". IBM. 2003-01-23.
- Amdahl, G. M.; Blaauw, G. A.; Brooks, F. P. Jr. (April 1964). "Architecture of the IBM System/360". IBM Journal of Research and Development. IBM. 8 (2): 87–101. doi:10.1147/rd.82.0087. ISSN 0018-8646.
- Brodkin, John. "50 years ago, IBM created mainframe that helped send men to the Moon". Ars Technica. Retrieved 9 April 2016.
- Clarke, Gavin. "Why won't you DIE? IBM's S/360 and its legacy at 50". The Register. Retrieved 9 April 2016.
- "Online PDP-8 Home Page, Run a PDP-8". PDP8. Retrieved September 25, 2015.
- "Transistors, Relays, and Controlling High-Current Loads". New York University. ITP Physical Computing. Retrieved 9 April 2016.
- Lilly, Paul (2009-04-14). "A Brief History of CPUs: 31 Awesome Years of x86". PC Gamer. Retrieved June 15, 2016.
- Patterson, David A.; Hennessy, John L.; Larus, James R. (1999). Computer Organization and Design: the Hardware/Software Interface (2. ed. , 3rd print. ed.). San Francisco: Kaufmann. p. 751. ISBN 978-1-55860-428-5.
- "1962: Aerospace systems are first the applications for ICs in computers". Computer History Museum. Retrieved October 9, 2018.
- "The integrated circuits in the Apollo manned lunar landing program". National Aeronautics and Space Administration. Retrieved October 9, 2018.
- "System/370 Announcement". IBM Archives. 2003-01-23. Retrieved October 25, 2017.
- "System/370 Model 155 (Continued)". IBM Archives. 2003-01-23. Retrieved October 25, 2017.
- "Models and Options". The Digital Equipment Corporation PDP-8. Retrieved June 15, 2018.
- https://www.computerhistory.org/siliconengine/metal-oxide-semiconductor-mos-transistor-demonstrated/
- Moskowitz, Sanford L. (2016). Advanced Materials Innovation: Managing Global Technology in the 21st century. John Wiley & Sons. pp. 165–167. ISBN 978-0-470-50892-3.
- Motoyoshi, M. (2009). "Through-Silicon Via (TSV)". Proceedings of the IEEE. 97 (1): 43–48. doi:10.1109/JPROC.2008.2007462. ISSN 0018-9219. S2CID 29105721.
- "Transistors Keep Moore's Law Alive". EETimes. 12 December 2018.
- "Who Invented the Transistor?". Computer History Museum. 4 December 2013.
- Hittinger, William C. (1973). "Metal-Oxide-Semiconductor Technology". Scientific American. 229 (2): 48–59. Bibcode:1973SciAm.229b..48H. doi:10.1038/scientificamerican0873-48. ISSN 0036-8733. JSTOR 24923169.
- Ross Knox Bassett (2007). To the Digital Age: Research Labs, Start-up Companies, and the Rise of MOS Technology. The Johns Hopkins University Press. pp. 127–128, 256, and 314. ISBN 978-0-8018-6809-2.
- Ken Shirriff. "The Texas Instruments TMX 1795: the first, forgotten microprocessor".
- "Speed & Power in Logic Families"..
- T. J. Stonham. "Digital Logic Techniques: Principles and Practice". 1996. p. 174.
- "1968: Silicon Gate Technology Developed for ICs". Computer History Museum.
- R. K. Booher. "MOS GP Computer". afips, pp.877, 1968 Proceedings of the Fall Joint Computer Conference, 1968 doi:10.1109/AFIPS.1968.126
- "LSI-11 Module Descriptions" (PDF). LSI-11, PDP-11/03 user's manual (2nd ed.). Maynard, Massachusetts: Digital Equipment Corporation. November 1975. pp. 4–3.
- "1971: Microprocessor Integrates CPU Function onto a Single Chip". Computer History Museum.
- Margaret Rouse (March 27, 2007). "Definition: multi-core processor". TechTarget. Retrieved March 6, 2013.
- Richard Birkby. "A Brief History of the Microprocessor". computermuseum.li. Archived from the original on September 23, 2015. Retrieved October 13, 2015.
- Osborne, Adam (1980). An Introduction to Microcomputers. Volume 1: Basic Concepts (2nd ed.). Berkeley, California: Osborne-McGraw Hill. ISBN 978-0-931988-34-9.
- Zhislina, Victoria (2014-02-19). "Why has CPU frequency ceased to grow?". Intel. Retrieved October 14, 2015.
- "MOS Transistor - Electrical Engineering & Computer Science" (PDF). University of California. Retrieved October 14, 2015.
- Simonite, Tom. "Moore's Law Is Dead. Now What?". MIT Technology Review. Retrieved 2018-08-24.
- "Excerpts from A Conversation with Gordon Moore: Moore's Law" (PDF). Intel. 2005. Archived from the original (PDF) on 2012-10-29. Retrieved 2012-07-25.
- "A detailed history of the processor". Tech Junkie. 15 December 2016.
- Eigenmann, Rudolf; Lilja, David (1998). "Von Neumann Computers". Wiley Encyclopedia of Electrical and Electronics Engineering. doi:10.1002/047134608X.W1704. ISBN 0-471-34608-X. S2CID 8197337.
- Saraswat, Krishna. "Trends in Integrated Circuits Technology" (PDF). Retrieved June 15, 2018.
- "Electromigration". Middle East Technical University. Retrieved June 15, 2018.
- "GIGA- | meaning in the Cambridge English Dictionary". dictionary.cambridge.org. Retrieved 2021-01-19.
- Ian Wienand (September 3, 2013). "Computer Science from the Bottom Up, Chapter 3. Computer Architecture" (PDF). bottomupcs.com. Retrieved January 7, 2015.
- "Introduction of Control Unit and its Design". GeeksforGeeks. 2018-09-24. Retrieved 2021-01-12.
- Brown, Jeffery (2005). "Application-customized CPU design". IBM developerWorks. Retrieved 2005-12-17.
- Garside, J. D.; Furber, S. B.; Chung, S-H (1999). "AMULET3 Revealed". University of Manchester Computer Science Department. Archived from the original on December 10, 2005.
- "IBM System/360 Model 65 Functional Characteristics" (PDF). IBM. September 1968. pp. 8–9. A22-6884-3.
- Huynh, Jack (2003). "The AMD Athlon XP Processor with 512KB L2 Cache" (PDF). University of Illinois, Urbana-Champaign. pp. 6–11. Archived from the original (PDF) on 2007-11-28. Retrieved 2007-10-06.
- Gottlieb, Allan; Almasi, George S. (1989). Highly parallel computing. Redwood City, Calif.: Benjamin/Cummings. ISBN 978-0-8053-0177-9.
- Flynn, M. J. (September 1972). "Some Computer Organizations and Their Effectiveness". IEEE Trans. Comput. C-21 (9): 948–960. doi:10.1109/TC.1972.5009071. S2CID 18573685.
- Lu, N. -P.; Chung, C. -P. (1998). "Parallelism exploitation in superscalar multiprocessing". IEE Proceedings - Computers and Digital Techniques. Institution of Electrical Engineers. 145 (4): 255. doi:10.1049/ip-cdt:19981955.
- Anjum, Bushra; Perros, Harry G. (2015). "1: Partitioning the End-to-End QoS Budget to Domains". Bandwidth Allocation for Video Under Quality of Service Constraints. Focus Series. John Wiley & Sons. p. 3. ISBN 978-1-84821-746-1. Retrieved 2016-09-21.
[...] in cloud computing where multiple software components run in a virtual environment on the same blade, one component per virtual machine (VM). Each VM is allocated a virtual central processing unit [...] which is a fraction of the blade's CPU.
- "VMware Infrastructure Architecture Overview- White Paper" (PDF). VMware. VMware. 2006.
- "CPU Frequency". CPU World Glossary. CPU World. 25 March 2008. Retrieved 1 January 2010.
- "What is (a) multi-core processor?". Data Center Definitions. SearchDataCenter.com. Retrieved 8 August 2016.
- "Quad Core Vs. Dual Core".
- Tegtmeier, Martin. "CPU utilization of multi-threaded architectures explained". Oracle. Retrieved September 29, 2015.
- Thomas Willhalm; Roman Dementiev; Patrick Fay (December 18, 2014). "Intel Performance Counter Monitor – A better way to measure CPU utilization". software.intel.com. Retrieved February 17, 2015.
- «انواع سی پی یو(CPU)». تکولایف. ۲۰۲۰-۰۵-۰۸. بایگانیشده از اصلی در ۲۳ ژانویه ۲۰۲۱. دریافتشده در ۲۰۲۰-۱۲-۲۶.
- «تفاوت پردازندههای معمولی و Xeon در چیست؟». Server.ir | نگرش جهانی، میزبانی ایرانی. ۲۰۱۴-۱۱-۱۱. دریافتشده در ۲۰۲۱-۰۱-۰۷.
- «هر آنچه در مورد پردازنده Core i9 اینتل میدانیم». زومیت. ۲۰۱۷-۰۹-۲۸. دریافتشده در ۲۰۲۱-۰۱-۱۹.
- Kingsley-Hughes, Adrian. "AMD unveils world's most powerful desktop CPUs". ZDNet. Retrieved 2021-01-19.
- پردازندهها (PDF).
- «بلومبرگ: وضعیت بازار تراشه ممکن است بسیار بدتر شود». زومیت. ۲۰۲۱-۰۲-۱۱. دریافتشده در ۲۰۲۱-۰۲-۱۱.
- نیکویی، توسط اشکان (۲۰۲۱-۰۲-۱۰). «اپل، سامسونگ و هواوی بزرگترین خریداران چیپ در سال 2020». سختافزار مگ. دریافتشده در ۲۰۲۱-۰۲-۱۱.
| در ویکیانبار پروندههایی دربارهٔ واحد پردازش مرکزی موجود است. |