مقایسه الگوریتمهای مرتبسازی
الگوریتم مرتبسازی، در دانش رایانه و ریاضی، الگوریتمی است که فهرستی از دادهها را به ترتیبی مشخص میچیند.
پرکاربردترین ترتیبها، ترتیبهای عددی و واژهنامهای هستند. مرتبسازی کارا در بهینهسازی الگوریتمهایی که به فهرستهای مرتب شده نیاز دارند (مثل جستجو و ترکیب) اهمیت زیادی دارد.
از آغاز علم رایانه مسائل مرتبسازی بررسیهای فراوانی را متوجه خود ساختند، شاید به این علت که در عین ساده بودن، حل آن به صورت کارا پیچیده است. برای نمونه مرتبسازی حبابی در سال ۱۹۵۶ به وجود آمد. در حالی که بسیاری این را یک مسئلهٔ حل شده میپندارند، الگوریتم کارآمد جدیدی همچنان ابداع میشوند (مثلاً مرتبسازی کتابخانهای در سال ۲۰۰۴ مطرح شد).
مبحث مرتبسازی در کلاسهای معرفی علم رایانه بسیار پرکاربرد است، مبحثی که در آن وجود الگوریتمهای فراوان به آشنایی با ایدههای کلی و مراحل طراحی الگوریتمهای گوناگون کمک میکند؛ مانند تحلیل الگوریتم، دادهساختارها، الگوریتمهای تصادفی، تحلیل بدترین و بهترین حالت و حالت میانگین، هزینهٔ زمان و حافظه، و حد پایین.
در این مقاله الگوریتم های مرتب سازی را مقایسه و طبقه بندی می کنیم.
طبقهبندی
در علم کامپیوتر معمولاً الگوریتمهای مرتبسازی بر اساس این معیارها طبقهبندی میشوند:
پیچیدگی (بدترین و بهترین عملکرد و عملکرد میانگین)
با توجه به اندازهٔ فهرست (n). در مرتبسازیهای معمولی عملکرد خوب و عملکرد بد است. بهترین عملکرد برای مرتبسازی است. الگوریتمهایی که فقط از مقایسهٔ کلیدها استفاده میکنند در حالت میانگین حداقل مقایسه نیاز دارند.



سرعت الگوریتم مرتبسازی یکی از خصیصههای مهم الگوریتم است که به تعداد مقایسهها و همچنین تعداد تعویضهایی که باید انجام گیرد بستگی دارد. سرعت اجرای بعضی از الگوریتمها با تعداد عناصز لیست نسبت توانی دارد و بعضی دیگر نسبت لگاریتمی.
سرعت اجرای الگوریتم در بدترین و بهترین حالت نیز مهم است زیرا ممکن است یکی از این دو حالت برای عمل مرتبسازی انتخاب گردد ممکن است سرعت متوسط اجرای الگوریتم خوب باشد ولی در بدترین حالت سرعت اجرای آن خیلی کم باشد.
حافظه (و سایر منابع کامپیوتر)
بعضی از الگوریتمهای مرتبسازی «در جا» هستند. یعنی به جز دادههایی که باید مرتب شوند، حافظهٔ کمی () مورد نیاز است؛ در حالی که سایر الگوریتمها به ایجاد مکانهای کمکی در حافظه برای نگهداری اطلاعات موقت نیاز دارند.

پایداری
الگوریتمهای مرتبسازی پایدار ترتیب را بین دادههای دارای کلیدهای برابر حفظ میکنند. فرض کنید میخواهیم چند نفر را بر اساس سن با یک الگوریتم پایدار مرتب کنیم. اگر دو نفر با نامهای الف و ب همسن باشند و در لیست اولیه الف جلوتر از ب آمده باشد، در لیست مرتب شده هم الف جلوتر از ب است.
برای فهم این فاکتور مقایسه الگوریتمها (شرکت عناصر مساوی در مقایسه) تصور کنید که یک بانک اطلاعاتی از آدرس افراد موجود است. این بانک اطلاعاتی بر اساس کد پستی و در داخل کد پستی بر اساس نام افراد مرتب است. اگر آدرس جدیدی به بانک اطلاعاتی اضافه گردد و این بانک اطلاعاتی بر اساس کد پستی مرتب گردید، نباید مجدداً بر اساس نام مرتب شود برای تضمین این مطلب الگوریتم مرتبسازی نباید جای دو کلید مساوی را تعویض نماید.
مقایسهای بودن یا نبودن
در یک مرتبسازی مقایسهای دادهها فقط با مقایسه به وسیلهٔ یک عملگر مقایسه، مرتب میشوند.
همسنجی سریع
جدول زیر مربوط به الگوریتمهای تطبیقی است. به کمک درخت تصمیم میتوان ثابت کرد حداقل زمان مرتبسازی با روش مقایسه در حالت میانگین، میباشد.

| نام | میانگین | بدترین | حافظه | پایداری | روش | نکات اضافه |
|---|---|---|---|---|---|---|
| مرتبسازی حبابی | بله | تعویض | کد کوتاه | |||
| مرتبسازی حبابی دوسویه | — | بله | تعویض | |||
| مرتبسازی شانهای | — | — | خیر | تعویض | کد کوتاه | |
| مرتبسازی گورزاد | — | بله | تعویض | کد کوتاه | ||
| مرتبسازی انتخابی | بستگی دارد | انتخاب | پایدار بودن آن به پیادهسازی بستگی دارد | |||
| مرتبسازی درجی | بله | درج | حالت میانگین همچنین ، میباشد که d تعداد درج هاست. | |||
| مرتبسازی شل | — | خیر | درج | |||
| مرتبسازی درخت دودویی | بله | درج | باید از یک درخت دودویی جستجو خودمتوازن گر استفاده شود | |||
| مرتبسازی کتاب خانهای | بله | درج | ||||
| مرتبسازی ادغامی | بله | ادغام | ||||
| مرتبسازی ادغامی درجا | بستگی دارد | ادغام | نمونه پیادهسازی اینجا: ؛ میتواند به عنوان یک مرتبسازی پایدار پیادهسازی شود: | |||
| مرتبسازی هرمی | بله | انتخاب | ||||
| مرتبسازی روان | — | خیر | انتخاب | |||
| مرتبسازی سریع | بستگی دارد | تقسیمبندی | با توجه به شیوهای که محور عمل میکند، میتواند به صورت پایدار پیادهسازی شود گونهٔ دیگری از آن از حافظه استفاده میکند. | |||
| مرتبسازی درونگرا | خیر | مرکب | استفاده شده در پیاده سازیهای SGI STL | |||
| مرتبسازی شکیبانه | — | خیر | درج و انتخاب | بزرگترین زیردنبالههای افزایشی را با پیدا میکند. | ||
| مرتبسازی رشتهای | بله | انتخاب | ||||
| مرتبسازی مسابقهای | انتخاب |











جدول زیر مربوط به الگوریتمهای ناتطبیقی است. این الگوریتمها محدودیت الگوریتمهای تطبیقی را ندارند. اندازه کلیدها و مقداری است که در پیادهسازی استفاده شدهاست. خیلی از این الگوریتمها بر این فرض استوارند که سایز کلیدها به قدری بزرگ است که همهٔ کلیدها مقدار یکسانی دارند. و یعنی "خیلی کمتر از".



| نام | میانگین | بدترین | حافظه | پایداری | n << 2k | نکات دیگر |
|---|---|---|---|---|---|---|
| مرتبسازی لانهکبوتری | بله | بله | ||||
| مرتبسازی سطلی | بله | خیر | فرض میکند عناصر در محدودهٔ خود یکنواخت پخش شدهاند. | |||
| مرتبسازی شمارشی | بله | بله | اگر k = آنگاه میانگین = | |||
| مرتبسازی مبنایی از کم ارزش ترین | بله | خیر | ||||
| مرتبسازی مبنایی از پرارزش ترین | خیر | خیر | ||||
| مرتبسازی گسترده | خیر | خیر |










الگوریتمهای مرتبسازی تطبیقی
درباره

سادهترین الگوریتم مرتبسازی از لحاظ پیادهسازی میباشد. این الگوریتم هر بار دو خانه مجاور را باهم مقایسه کرده، اگر ترتیب آنها درست نبود، جای آنها را عوض میکند و یک خانه جلو میرود. به این ترتیب پس از یک بار پیمایش آرایه یک خانه در جای درست خود قرار میگیرد و این کار تا زمانی که لیست کاملاً مرتب شود ادامه مییابد. دلیل نامگذاری آن نیز از این روست که حرکت یک کلید به سمت مکان نهایی آن شبیه پویش حباب به بالای مایع است.
مقایسه
در مرتبسازی حبابی موقعیت عناصر درون لیست نقش بسزایی در تعیین عملکرد آن دارد. از آنجایی که عناصر بزرگ در ابتدای لیست به سرعت جابجا (swap) میشوند، مشکل چندانی در سرعت عملکرد الگوریتم ایجاد نمیکنند. اگرچه عناصر کوچک نزدیک به آخر لیست (که باید به سمت ابتدای لیست بیایند) بسیار کند حرکت میکنند. این تفاوت در سرعت به حدی است که به عناصر بزرگ، لاکپشتها، و به عناصر کوچک، خرگوشها میگویند.
تلاش بسیاری انجام شده که سرعت حرکت لاکپشتها در مرتبسازی حبابی افزایش یابد. از جمله میتوان از Cocktail sort نام برد که در این زمینه بسیار خوب عمل میکند ولی بدترین زمان اجرای آن هنوز است. مرتبسازی شانهای (Comb sort) عناصر بزرگ با فاصلههای زیاد را مقایسه میکند و لاکپشتها را با سرعت فوق العادهای حرکت میدهد سپس با کم تر و کم تر کردن این فاصلهها لیست را به سرعت مرتب میکند، بهطوریکه سرعت متوسط آن قابل مقایسه با الگوریتمهای پر سرعتی مثل مرتبسازی سریع (Quick Sort) میباشد.
علی رغم پیادهسازی ساده، مرتبسازی حبابی در عمل در مقایسه با الگوریتمهای دیگری که پیچیدگی دارند، کارایی کمتری دارد. تا جایی که تحقیقات نشان میدهد مرتبسازی حبابی در عمل ۵ برابر کند تر از مرتبسازی درجی و ۴۰ درصد کندتر از مرتبسازی انتخابی میباشد.

گونههای دیگر
مرتبسازی زوج-فرد، پیادهسازی موازی مرتبسازی حبابی است که در سیستمهای انتقال پیام قابل استفاده میباشد.
درباره

یک الگوریتم تطبیقی ساده دیگر برای مرتبسازی یک لیست، مرتبسازی انتخابی است. شیوه مرتب کردن آن به این صورت است که در هر مرحله کوچکترین (یا بزرگترین) عنصر آرایه را با مییابد و آن را به مکان خود میبرد. بعد دومین عنصر کوچک (یا بزرگ) و به همین ترتیب ادامه میدهد تا آرایه مرتب شود.

مقایسه
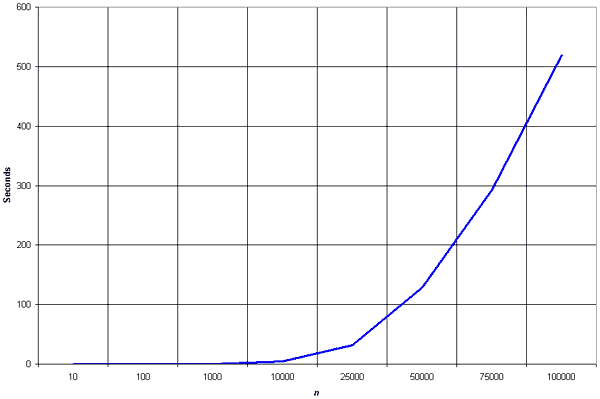
در بین الگوریتمهای هم مرتبه، مرتبسازی انتخابی عموماً سریع تر از مرتبسازی حبابی و (Gnome sort) عمل میکند. اما در مقایسه با مرتبسازی درجی کندتر است.(با یک محاسبهٔ ساده مرتبسازی درجی حدودا نصف مقایسههای مرتبسازی انتخابی را انجام میدهد). در عمل این الگوریتم برای مرتبسازی یک لیست کوچک، الگوریتمی نسبتا کارا بهشمار میرود. نمودار کارایی الگوریتم برحسب ورودیها را در زیر میبینید:
گونههای دیگر
پیادهسازی دوطرفهٔ مرتبسازی انتخابی، cocktail sort نامیده میشود که در هر پیمایش عنصر کمینه و بیشینه را با هم پیدا میکند. این کار تعداد پیمایشها را به نصف کاهش داده اما تعداد مقایسهها و جابه جاییها را کاهش نمیدهد. البته cocktail sort غالبا به عنوان گونهٔ تغییر یافتهٔ مرتبسازی حبابی شناخته میشود.
Bingo sort نیز گونهٔ تغییریافتهٔ دیگری از مرتبسازی انتخابی است برای زمانی که دادههای تکراری زیادی میان ورودیها وجود داشته باشد. این الگوریتم کلیدها را برحسب تعداد تکرارشان مرتب میکند تا به بزرگترین کلید برسد سپس آن کلیدها را به تعداد تکرارشان به مکان نهایی خود میبرد، مثل مرتبسازی شمارشی. در واقع مرتبسازی انتخابی برای انتقال یک مقدار به مکان نهایی خود یک پیمایش بر روی دادههای باقیمانده انجام میدهد. در حالی که در Bingo sort برای هر کلید (value و نه Item) دو بار پیمایش انجام میشود. یک بار برای یافتن کلید بزرگتر بعدی و یک بار برای انتقال تمام خانهها با آن کلید به محل نهاییشان. بنابراین اگر بهطور متوسط، از هر کلید ۲ تکرار یا بیشتر داشته باشیم Bingo sort عموماً سریع تر عمل خواهدکرد.
درباره

الگوریتم سادهای از لحاظ پیادهسازی است که در هر مرحله یک عنصر را برداشته و در محل مناسبش در میان دادههایی که در مراحل قبلی مرتب شدهاند درج میکند.
مقایسه
این الگوریتم در عمل از بسیاری از الگوریتمهای هم مرتبه خود مثل مرتبسازی حبابی و مرتبسازی انتخابی بهتر عمل میکند و متوسط زمان اجرای آن میباشد و برای تعداد ورودیهای کم الگوریتم کارایی محسوب میشود. همچنین برای مرتبسازی مجموعهای از دادههای تقریباً مرتب کارآمد است. و اگر تعداد وارونگیها، d باشد، این الگوریتم دارای زمان اجرای O(n)+d خواهد بود.
بهترین ورودی برای آن دادههای مرتب و بدترین ورودی آرایهای است که به صورت معکوس مرتب شده باشد.
در حالت کلی، مرتبسازی درجی در آرایه بار عمل نوشتن انجام میدهد؛ درحالیکه مرتبسازی انتخابی تنها بار مینویسد. به همین دلیل مرتبسازی انتخابی در مواردی که نوشتن در حافظه نیازمند هزینه زیادی باشد، سریعتر عمل میکند مانند نوشتن در flash memory.
برخی الگوریتمهای حل و تقسیم، مثل مرتبسازی ادغامی یا مرتبسازی سریع که با تقسیم لیست به صورت بازگشتی به زیرلیستهای مرتب شده، عمل مرتبسازی را انجام میدهند. یک راه بهینهسازی برای این الگوریتمها، استفاده از مرتبسازی درجی برای مرتب کردن زیرلیستهای کوچک است که در کل موجب تسریع الگوریتم میشود. سایز زیرلیستهایی که استفاده از مرتبسازی درجی برای آنها کارایی بهتری دارد حدودا بین ۸ تا ۲۰ عنصر است.

گونههای دیگر
مرتبسازی درجی دودویی گونهای از مرتبسازی درجی است که در آن برای یافتن محل مناسب هر عنصر از جستجوی دودویی استفاده میشود. این الگوریتم برای زمانی که هزینهٔ مقایسهها از هزینهٔ جابه جاییها بیشتر باشد، مانند زمانی که لیست ورودی مرتب شدهاست، مناسب تر میباشد.
D.L.Shell مرتبسازی درجی را با الگوریتمی تحت عنوان Shell sort بهبود بخشید. این الگوریتم مرتبسازی را با مقایسه دو عنصر که فاصله آنها از هم در هر مرحله کم میشود، انجام میدهد. مرتبسازی شل پیچیدگی الگوریتم را در عمل بهطور قابل توجهی افزایش داده که در دو نسخه مختلف با و عمل میکند.
گونهٔ تغییریافتهٔ دیگری از مرتبسازی درجی در سال ۲۰۰۶ با نام مرتبسازی کتابخانهای طراحی شد که در آن تعداد کمی فضای بدون استفاده در سراسر آرایه پخش میشود. این کار باعث تسریع شدن درجهای بعدی میشود. طراحان ثابت کردهاند که این الگوریتم با احتمال زیادی در زمان اجرا میشود.
Gnome sort نیز الگوریتم دیگری است که با تغییر کوچکی در مرتبسازی درجی ایجاد شدهاست به این ترتیب که در هر مرحله برای درج عنصر به جای شیفت دادن از جابه جایی تعدادی از عناصر مجاور استفاده میشود، مثل مرتبسازی حبابی.


درباره

این مرتبسازی به طریقهٔ تقسیم و حل، لیست را مرتب میکند. به این صورت که آرایه را به دو لیست با اندازهٔ تقریباً مساوی تقسیم کرده، هر زیر لیست را به صورت بازگشتی مرتب و سپس با هم ادغام میکند.
مقایسه
مرتبهٔ این الگوریتم از حل رابطهٔ بازگشتی حاصل میشود. در بدترین حالت تعداد مقایسههای آن تقریباً میباشد که در حالت متوسط مقدار آن a.n تا کم میشود که در آن a=0.2645.
تعداد مقایسههای مرتبسازی ادغامی دربدترین حالت حدود ۰٫۳۹ کمتر از مرتبسازی سریع در حالت متوسط است. بدترین حالت مرتبسازی ادغامی زمانی اتفاق میافتد که کلید تمام عناصر با هم برابر باشند. لازم به ذکر است این حالت برای مرتبسازی سریع بهترین حالت است! در پیادهسازی بازگشتی آن تابع مرتبسازی در بدترین حالت ۲n-1 بار صدا زده میشود در حالی که در مرتبسازی سریع n بار صدا زده میشود.
پیادهسازی معمولی مرتبسازی ادغامی به صورت غیردرجا و با حافظه کمکی n است. (البته پیاده سازیهایی نیز وجود دارد که به صورت غیردرجاست اما به n/2 حافظه اضافی نیاز دارد). پیادهسازی درجای آن (بدون نیاز به حافظه کمکی) نیز امکانپذیر است اما پیچیده بوده و در عمل کارآیی آن را کاهش میدهد. مرتبسازی ادغامی درجا برخلاف نوع ساده آن لزوما پایدار نیست.
در مقایسه مرتبسازی ادغامی با دیگر الگوریتمها، میتوان گفت اگرچه در اکثر موارد از مرتبسازی هرمیکندتر عمل میکند و همچنین حافظهٔ بیشتری میگیرد، و اگرچه در یک نگاه کلی مرتبسازی سریع به عنوان سریعترین الگوریتم مرتبسازی شناخته میشود، اما مرتبسازی ادغامی یک مرتبسازی پایدار است که اجرای موازی آن بهتر عمل میکند و همچنین اغلب بهترین انتخاب برای مرتبسازی یک لیست پیوندی است. زیرا اجرای مرتبسازی هرمی روی آن غیرممکن و اجرای مرتبسازی سریع کارایی چندانی ندارد.
در جاوا، دستور Array.sort() یا از مرتبسازی ادغامی استفاده میکند یا از یک نوع مرتبسازی سریع وابسته به نوع داده که برای کارایی بیشتر هنگامی که کمتر از ۷ ورودی داریم به مرتبسازی درجی تغییر میکند.
Python نیز از timsort استفاده میکند که ترکیبی از مرتبسازی ادغامی و درجی میباشد.


درباره
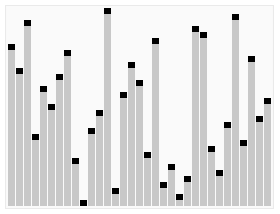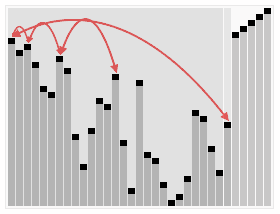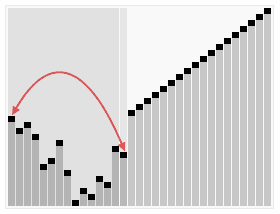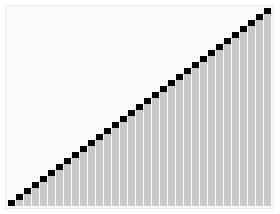
این مرتبسازی که از خانواده مرتبسازی انتخابی محسوب میشود، ابتدا داخل آرایه یک هرم بیشینه (یا کمینه) میسازد، سپس بزرگترین مقدار را در انتهای آرایه قرار میدهد. سپس با اعداد باقیمانده دوباره این عمل را انجام میدهد. بزرگترین مقدار را در هرم یافته و در مکان درست خود قرار میدهد و این کار را تا زمانی که هرم خالی شود انجام میدهد.
مقایسه
این الگوریتم که یک مرتبسازی غیرپایدار اما درجاست، در بدترین حالت دارای پیچیدگی میباشد و پیادهسازی آن برخلاف مرتبسازی سریع به صورت بازگشتی نیست.
در مقایسه با مرتبسازی سریع، معمولاً مرتبسازی سریع، کارایی بیشتری از خود نشان میدهد اما بدترین حالت آن میباشد که آن را برای تعداد زیادی داده ناکارآمد میکند.
گونههای دیگر
Introsort یک الگوریتم مرتبسازی جالب برای ترکیب مرتبسازی سریع و هرمی است، به نحوی که برتریهای هر دو را در خود جای دهد: سرعت مرتبسازی هرمی در حالت بد و سرعت مرتبسازی سریع در حالت میانگین.
در مقایسه با مرتبسازی ادغامی، معمولاً در دستگاههایی که حافظه نهان (Cache) کمتری دارند، مرتبسازی هرمی سریع تر عمل میکند. از طرف دیگر مرتبسازی ادغامی چندین مزیت بر مرتبسازی هرمی دارد. ازجمله این که پایدار است، موازیسازی آن بهتر صورت میگیرد و قابل پیادهسازی روی لیست پیوندی است.
الگوریتم مرتبسازی هرمی مبنای ۳ نیز دقیقا شبیه الگوریتم مذکور است با این تفاوت که به جای یک هرم دودویی از یک هرم سه سه یی استفاده میکند. به این معنا که هر عنصر میتواند ۳ فرزند داشته باشد. پیادهسازی این الگوریتم مشکل است اما به تعداد ثابتی عمل مقایسه و جابجایی را کاهش میدهد. این روش حدود ۱۲% سریع تر از حالت معمولی مرتبسازی هرمی عمل میکند.
نوع دیگری از مرتبسازی هرمی با استفاده از درخت دکارتی انجام میشود که عنصر را تا زمانی که کلیدهای کوچکتر در دو طرف آن گره، درون خروجی مرتب شده قرار نگرفته باشند، درون هرم اضافه نمیکند. به این ترتیب اثبات میشود که الگوریتم برای ورودیهایی که از قبل تقریباً مرتب شدهاند سریع تر از عمل میکند.
به خاطر حدبالای ثابت اجرای آن و همچنین حافظهٔ کمکی ثابت، در سیستمهای تعبیه شده که محدودیت زمانی دارند یا سیستمهای امنیتی از این مرتبسازی استفاده میکنند.
درباره
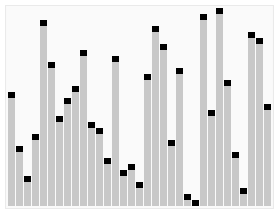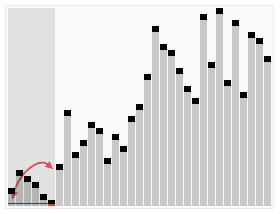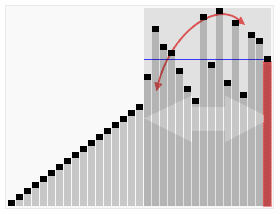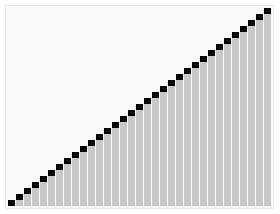
یکی از روشهای مرتبسازی است که به علت مصرف کم حافظه، سرعت اجرای مناسب و پیادهسازی ساده، بسیار مورد توجه و محبوب واقع شدهاست. این روش در ۱۹۶۰ توسط ریچارد هواره که بر روی ماشین ترجمه کار میکرد برای مرتبسازی کلماتی که باید ترجمه میشدند طراحی شد.
هر پیادهسازی این روش، از دو بخش تقسیمبندی آرایه و مرتبسازی تشکیل شدهاست و برای هر تقسیمبندی نیاز به یک محور دارد. پس از انتخاب محور، دادهها نسبت به آن مرتب میشوند یعنی همه دادههای بزرگتر در یک طرف و دادههای کوچکتر در طرف دیگر قرار میگیرند. با مرتبسازی بازگشتی این دو قسمت کل دادهها مرتب میشوند. برخلاف مرتبسازی ادغامی در این روش نیازی به ادغام این دو بخش نیست چرا که همه دادههای قسمت چپ از دادههای قسمت راست کوچکتر است.
این روش در واقع گونهای مرتبسازی درخت دودویی است که از لحاظ حافظه بهینه شدهاست.
مقایسه
بهترین حالت برای این الگوریتم زمانی اتفاق میافتد که محور در وسط واقع شود، در این صورت این الگوریتم در و سریع تر از الگوریتمهای دیگر اجرا میشود.
بدترین حالت زمانی است که محور پس از تقسیم در ابتدا یا انتهای آرایه قرار گیرد. که در این حالت زمان اجرای آن خواهدبود.
پیادهسازی آن به صورت تصادفی، محور را در هر مرحله به شکل تصادفی انتخاب میکند.
پیادهسازی آن برای لیست پیوندی معمولاً کارا نیست زیرا به دلیل نبود دسترسی تصادفی، محور خوبی نمیتوان انتخاب کرد.
مرتبسازی سطلی ای که با دو سطل انجام بشود بسیار شبیه مرتبسازی سریع است. محور در این مورد، عنصر میانی کلیدهاست. این عمل، حالت میانگین را برای ورودیهای بهطور یکنواخت توزیع شده، به خوبی اصلاح میکند.
این الگوریتم در عمل برای مرتبسازی آرایههای نسبتا کوچک اصلا مناسب نیست. به علاوه بخش تقسیمبندی آرایه نیز مشکل بزرگی در زمان اجرا میباشد. به همین دلیل پیشنهاد میشود برای ۷ داده یا کمتر از انواع دیگر مرتبسازی مثل مرتبسازی درجی استفاده شود، به علاوه به جای پیادهسازی بخش تقسیمبندی برای بیش از ۴۰ داده میتوان از میانهٔ ۹، برای کمتر از ۴۰ داده از میانهٔ ۳ و برای آرایههای بسیار کوچک از عضو وسط استفاده کرد.
این مرتبسازی را نیز میتوان مثل مرتبسازی ادغامی به صورت موازی اجرا نمود. اگر n پردازنده داشته باشیم، میتوان با ، n عنصر را به p زیرلیست تقسیم نمود، سپس هر بخش را با مرتب کرد. یک مزیت پیادهسازی موازی آن این است که نیازی به همگامسازی نیست و وقتی که زیرلیستها آماده شد، اجرای هر بخش کاملاً مستقل از بخشهای دیگر است.
این مرتب سازی، برای اجرا بر روی معماریهای کامپیوتری امروزی بسیار مناسب است و از سلسله مراتب حافظه بهترین استفاده را میکند.
پیادهسازی بسیار خوبی از این الگوریتم را میتوانید در کد منبع جاوا، در کتابخانهٔ java.util.array مشاهده نمایید.

الگوریتمهای مرتبسازی ناتطبیقی
درباره
الگوریتمی است که لیستی از داده با طول حداکثر را در مرتب میکند. به این صورت که ورودی را اگر رشته است به حروف سازنده اش و اگر عدد صحیح است به ارقامش شکسته و ابتدا کم ارزشترین (یا پرارزشترین) بخش آنها را مقایسه کرده، مرتب میکنیم، سپس بخش بعدی را مقایسه میکنیم و به همین ترتیب. برای مرتب کردن هر بخش میتوانیم از مرتبسازی شمارشی استفاده کنیم. اگر از کم ارزشترین بخش شروع کنیم به آن LSD radix sort میگویند و اگر از پرارزشترین قسمت شروع کنیم MSD radix sort.



مقایسه
میتوان برای کارآمدتر کردن الگوریتم از صف به عنوان پیمانهها استفاده کرد، به این ترتیب که هر بار اعداد را برحسب رقمشان درون یک صف قرار دهیم. پس از پایان مرحله، دوباره اعداد را از صف درون آرایه بریزیم و این کار را برای رقمهای بعدی تکرار کنیم. این یک مدل ساده ولی نسبتا مناسب برای پیادهسازی الگوریتم است.
گفتیم که زمان اجرای مرتبسازی مبنایی میباشد. وقتی که از حدود باشد، ممکن است به نظر برسد که مرتبسازی مبنایی، برتری خاصی نسبت به الگوریتمهای تطبیقی مثل مرتبسازی ادغامی نداشته باشد. اما باید توجه داشت که پیچیدگی بدست آمده برای این الگوریتمهای تطبیقی، در واقع تعداد مقایسههای دو عدد کامل را میشمارد و سریعترین زمان ممکن برای این مقایسه برابر است با k. بنابراین اگر ما تعداد عملیات بنیادین انجام شده را بشماریم، پیچیدگی مرتبسازی ادغامی از خواهد بود.



درباره
یک الگوریتم ناتطبیقی است که با فرض صحیح بودن اعداد، از آرایهای به طول بازهٔ اعداد ورودی، برای شمردن تعداد تکرار هر عدد استفاده میکند (به این آرایه، آرایه شمارش میگویند) به عنوان مثال اندیس i در آرایه شمارشی، تعداد تکرار عنصر i در آرایه ورودی را نشان میدهد. از اعداد داخل این آرایه برای قرار دادن عناصر آرایه وروذی در آرایه خروجی استفاده میشود.
این الگوریتم در سال ۱۹۵۴ توسط هارولد سوارد طراحی شد.
مقایسه
اگر کمینه آرایه ورودی صفر نبود، برای ساختن آرایه شمارشی باید اعضای آرایه ورودی را به نحوی شیفت دهیم که کوچکترین کلید آن، با اندیس اول آرایه شمارشی منطبق شود.
این مرتبسازی یک مرتبسازی پایدار، با پیچیدگی است که n طول آرایه ورودی و k طول آرایه شمارش میباشد.
برای این که الگوریتم کارآمد باشد، لازم است k از مرتبهٔ n باشد تا پیچیدگی نهایی آن از باشد.

انواع دیگر
یک گونه تغییریافتهٔ مرتبسازی شمارشی، Tally sort است که در آن آرایه ورودی شامل کلیدهای تکراری نیست یا انتظار ما این است که در طول مرتب سازی، تکرارهای هر کلید از آرایه حذف شوند. در این مرتبسازی آرایه شمارشی به صورت آرایهای از بیت هاست و هر بیت در صورتی یک میشود که کلید آن در بین اعداد موجود باشد.
درباره
این الگوریتم که count sort نیز نامیده میشود (با counting sort اشتباه نشود) الگوریتمی است که برای مرتبسازی لیستی از عناصر که در آن تعداد عناصر (n) و تعداد کلیدهای ممکن (N) تقریباً با هم برابر باشد، بسیار مناسب است. مراحل انجام آن به این صورت است:
- 1- با گرفتن آرایه ورودی، آرایه کمکی ازلانهها میسازیم، بهطوریکه هر لانه برای تعدادی از کلیدها در محدوده آرایه ورودی باشد.
- 2- با پیمایش آرایه اصلی، هر عنصر را در لانهای که با کلید آن عنصر مشابهت دارد قرار میدهیم. بنابراین هر لانه شامل عناصری با کلیدهای یکسان میشود.
- 3- با گذر از لانهها، عناصر خانههایی که خالی نیستند را در آرایه اصلی کپی میکنیم.
به عنوان مثال فرض کنید میخواهیم عناصر زیر را بر حسب کلیدهایشان مرتب کنیم:
- (5 , “hello”)
- (3 , “pie”)
- (8 , “apple”)
- (5 , “king”)
برای هر کلید بین ۳ تا ۸، یک لانه میسازیم، و عناصر را به شکل زیر درون لانهها قرار میدهیم:
- 3: (3 , “pie”)
- 4:
- 5: (5 , “hello”) , (5 , “king”)
- 6:
- 7:
- 8: (8 , “apple”)
حال با پیمایش لانهها آنها را درون آرایه اصلی قرار میدهیم.
تفاوت بین مرتبسازی لانه کبوتری و مرتبسازی شمارشی این است که در مرتبسازی شمارشی، آرایه کمکی شامل عناصر ورودی نیست و تنها تکرار آنها را میشمارد. مثلاً برای مثال قبل:
- 3: 1
- 4: 0
- 5: 2
- 6: 0
- 7: 0
- 8: 1
با استفاده از این اطلاعات ما میتوانیم با یکبار انتقال عناصر آرایه را مرتب کنیم، در صورتی که در مرتبسازی کبوتری دو انتقال لازم است، یکبار از آرایه اصلی به لانهها و یکبار از لانهها به آرایه نهایی.
برای آرایههایی که تعداد کلیدهای متفاوت آنها (N) خیلی بزرگتر از اندازه شان (n) باشد، مرتبسازی سطلی الگوریتمی است که در حافظه و زمان کارآمدتر عمل میکند.
درباره

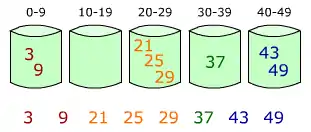
Bucket sort یا Bin sort نوعی مرتبسازی ناتطبیقی است که آرایه را به تعدادی سطل تقسیمبندی میکند. سپس هر سطل به صورت مستقل مرتب میشود، یا با استفاده از الگوریتمهای متفاوت مرتبسازی یا با اعمال بازگشتی خود مرتبسازی سطلی.
صورتی از این مرتبسازی بر روی آرایه از اعداد در دو شکل زیر مشخص است.
این مرتبسازی در واقع از خانواده مرتبسازی مبنایی است و همچنین حالت تعمیم یافتهٔ مرتبسازی طبقهای است.
شکل اصلی پیادهسازی آن به این صورت است که پس از سطل بندی، هر سطل را با مرتبسازی درجی مرتب میکنیم، میتوان نشان داد که هر سطل تقریباً در زمان خطی مرتب میشود. اگرچه کارایی این الگوریتم به شیوه سطل بندی کردن بسیار وابسته است. اگر سطل بندی به گونهای باشد که کلیدهای زیادی درون یک سطل قرار بگیرند، مرتبسازی به کندی صورت میگیرد.
اما یک پیادهسازی متداول و بهینه آن است که عناصر را پس از سطل بندی به همان ترتیب در آرایه اصلی قرار دهیم و سپس روی آرایه، مرتبسازی درجی را اعمال کنیم. به این خاطر که زمان اجرای این مرتبسازی وابسته به فاصله هر عنصر از مکان نهاییش میباشد و فاصله دادهها از مکان نهایی پس از سطل بندی کاهش یافته، تعداد مقایسهها مقدار قابل توجهی کم میشود و بهره وری سلسله مراتب حافظه در مرتبسازی لیست افزایش مییابد.
انواع دیگر
Shuffle sort گونهٔ تغییریافتهای از مرتبسازی سطلی است که در آن ۱/۸ ابتدایی دادهها از آرایه جدا میشود و بهطور جداگانه مرتب میشود. این عناصر n/8 سطل، برای ۷/۸ عنصر باقیماندهٔ آرایه ایجاد میکند. هر سطل مرتب میشود و سپس برای ساخت آرایه نهایی به هم الصاق میشود. این مرتبسازی به عنوان یک مرحله در J sort مورد استفاده قرار میگیرد.
مرتبسازی سطلی میتواند به عنوان نسخهٔ تغییریافتهٔ مرتبسازی شمارشی تلقی شود. اگر اندازهٔ هر سطل یک باشد، این دو مرتبسازی هم تراز هم قرار میگیرند. اندازهٔ متغیر سطلها در مرتبسازی سطلی، به آن اجازه استفاده از حافظه به جای میدهد که m تعداد کلیدهای متمایز است. به عبارت دیگر، این مرتب سازی، رفتار مرتبسازی شمارشی را در بدترین حالت که میباشد، بهبود میدهد.
مرتبسازی سطلی با دو سطل، در واقع پیادهسازی ای از مرتبسازی سریع است که محور همیشه میانهٔ دادهها انتخاب میشود. این شیوه برای دادههایی که به صورت یکنواخت پخش شدهاند کارآمد است اما شیوههای دیگر انتخاب محور، مثل انتخاب تصادفی، مقاومت و پایداری بیشتری در برابر دادههای مختلف ورودی، برای الگوریتم ایجاد میکند.
مرتبسازی ادغامی n – سویه نیز با تقسیم لیست ورودی به n زیرلیست و مرتبسازی آنها آغاز میشود. اگرچه در زیرلیستهای ایجاد شده توسط مرتبسازی ادغامی، محدوده کلیدها با هم اشتراک پیدا میکند و این سبب میشود که ترکیب زیرلیستهای آن به سادگی مرتبسازی سطلی نباشد و به جای آن از یک الگوریتم ادغام استفاده بشود، اما این هزینهٔ اضافی با آسان کردن مرحلهٔ تقسیم دادهها و همچنین هم اندازه کردن همهٔ زیرلیستها جبران میشود و در نهایت حدبالای زمان مرتبسازی را (یعنی در بدترین حالت) بهبود میدهد.


پیاده سازیها
منابع
- ویکیپدیای انگلیسی، الگوریتمهای مرتب سازی
- ویکیپدیای انگلیسی، مرتبسازی حبابی
- ویکیپدیای انگلیسی، مرتبسازی انتخابی
- ویکیپدیای انگلیسی، مرتبسازی درجی
- ویکیپدیای انگلیسی، مرتبسازی ادغامی
- ویکیپدیای انگلیسی، مرتبسازی هرمی
- ویکیپدیای انگلیسی، مرتبسازی سریع
- ویکیپدیای انگلیسی، مرتبسازی لانه کبوتری
- ویکیپدیای انگلیسی، مرتبسازی سطلی
- ویکیپدیای انگلیسی، مرتبسازی شمارشی
- ویکیپدیای انگلیسی، مرتبسازی مبنایی
مطالعه بیشتر
- مرتبسازی خارجی
- شبکههای مرتب سازی
- الگوریتمهای ترکیبی
- الگوریتمهای جستجو
- الگوریتمهای مرتبسازی ترتیبی و موازی
- دایره المعارف الگوریتمها، داده ساختارها و مسائل
- انیمیشنهای الگوریتمهای مرتب سازی