مرتبسازی سطلی
مرتبسازی سطلی (به انگلیسی: bucket sort)، یا مرتبسازی صندوقی، نوعی الگوریتم مرتبسازی است که با تقسیم کردن یک آرایه به تعدادی سطل کار میکند. سپس هر سطل بهطور جداگانه مرتب میشود که این کار مرتب کردن میتواند از یک الگوریتم مرتبسازی دیگر استفاده کرده یا مرتبسازی سطلی را بهطور بازگشتی روی آن اجرا کند. مرتبسازی سطلی تعمیم مرتبسازی لانه کبوتری است. از آن جایی که این مرتبسازی، مرتبسازی مقایسهای نیست، نمیتوان (Ω(nlog n را به عنوان کران پایین برای آن در نظر گرفت. پیچیدگی محاسباتی برای آن بر اساس تعداد سطلها محاسبه میشود. ایده اصلی مرتبسازی سطلی این است که بازه ی(۱و۰]را به n زیر بازه با اندازهٔ یکسان تقسیم، یا سطل بندی و سپس n عدد ورودی را درون سطلها پخش کند.
| رده | الگوریتم مرتبسازی |
|---|---|
| ساختمان داده | آرایه |
| کارایی بدترین حالت | |
| کارایی متوسط | |
| پیچیدگی فضایی |



نحوه عملکرد

عناصر در سطلها توزیع میشوند.
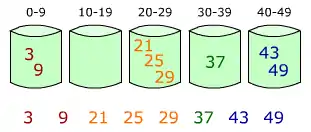
عناصر در هر سطل مرتب میشوند.
مرتبسازی سطلی به صورت زیر کار میکند:
- آرایهای به عنوان سطلهای خالی تعریف میکند.
- پخش کردن: روی آرایه اصلی حرکت میکند و هر عنصر را در سطلش قرار میدهد. (شکل (۱))
- هر سطل غیر خالی را مرتب میکند. (شکل (۲))
- جمعآوری کردن: به ترتیب سطلها را نگاه میکند و همه عناصر را به آرایه اصلی بازمیگرداند.
یک راه بهینهسازی مرسوم این است که ابتدا عناصر را در آرایه اصلی قرار داده، سپس مرتبسازی درجی را روی کل آرایه اجرا کند. چون زمان اجرای مرتبسازی درجی به این که هر عنصر از جای نهاییش چقدر فاصله دارد، بستگی داشته، تعداد مقایسهها نسبتاً کم باقی میماند و همچنین سلسله مراتب حافظه با مرتب کردن لیست بهطور متصل در حافظه، بهتر به کار گرفته میشود.
مرسومترین نوع مرتبسازی سطلی روی لیستی با طول n عمل میکند که ورودیها بین صفر و مقدار ماکسیممی مانند M هستند. سپس بازهٔ مقادیر را به n سطل هر کدام با طول M/n تقسیم میکند. اگر هر سطل با استفاده از مرتبسازی درجی مرتب شود، میتوان نشان داد که مرتبسازی در زمان مورد خطی مورد انتظار اجرا میشود. (که میانگین زمان اجرا را روی هر ورودی ممکن میدهد) با این وجود، کارایی این مرتبسازی، زمانی که عناصر نزدیک به هم قرار میگیرند، تنزل پیدا میکند. در این حالت همه عناصر در یک سطل قرار میگیرند و مرتبسازی به کندی انجام میگیرد.
الگوریتم
مرتبسازی سطلی بهطور میانگین (زمانی که دادهها به صورت یکنواخت توزیع شده باشند) در زمان خطی اجرا میشود. فرض میشود که دادهها با یک فرایند تصادفی که عناصر را بهطور یکنواخت روی بازه (۰٬۱] توزیع میکند.
ایده مرتبسازی سطلی این است که بازه (۰٬۱] را به n زیر بازه یا سطل با طول مساوی تقسیم میکند و n عدد ورودی را داخل سطلها توزیع میکند. از آن جایی که ورودیها بهطور یکنواخت روی (۰٬۱] توزیع شدهاند، ما انتظار نداریم که اعداد زیادی در یک سطل قرار بگیرند. برای تولید خروجی، اعداد هر داده را (با استفاده از مرتبسازی درجی) مرتب کرده و سپس به ترتیب روی سطلها حرکت کرده و عناصر داخل هر کدام را لیست میکنیم.
BUCKET_SORT (A) 1. n ← length [A] 2. For i = 1 to n do 3. Insert A[i] into list B[nA[i]] 4. For i = 0 to n-1 do 5. Sort list B with Insertion sort 6. Concatenate the lists B[0], B[1],.. B[n-1] together in order.
و الگوریتم در زبان C
void bucketSort(int a[],int n, int max)
{
int* buckets = new int[max];
int SIZE = n;
for(int j = 0 ; j <= max ; j++)
buckets[j] = ۰;
for(int i = 0 ; i < SIZE ; i++)
++buckets[a[i]];
for(i = 0 , j = 0 ; j <= max ; ++j)
for(int k = buckets[j] ; k > 0 ; k--)
a[i++] = j;
}
کد ما برای مرتبسازی سطلی فرض میکند که ورودی در آرایه n عنصری A قرار دارد و هر عنصر A بین ۰ و ۱ است. همچنین ما به یک آرایه کمکی[B[0.. n -1 برای لیستهای پیوندی مربوط به سطلها نیاز داریم.
برای آن که ببینیم این الگوریتم کار میکند، دو عنصر [A[i و [A[j را در نظر بگیرید. بدون از دست دادن کلیت مسئله فرض کنید که
[A[i]≤ A[j. عنصر [A[i میتواند در سطلی همانند [A[j قرار بگیرد یا به سطلی با اندیس کوچکتر برود. اگر [A[iو [A[j در سطلی یکسان قرار گیرند، حلقه for دوم آنها را در ترتیب درست قرار میدهد. اگر [A[i و [A[j در سطلهای متفاوت باشند، آنگاه خط آخر کد، آنها را در جای درست میگذارد. بنا براین، مرتبسازی سطلی درست کار میکند.
مثالی از نحوه مرتبسازی

آرایه [A[1..10 داده شدهاست. آرایه [B[0..9 آرایهای از لیستهای مرتب شده یا سطلها پس از خط پنجم کد است. سطل i مقادیری در بازه [i/10, (i +1)/10] را نگاه داشتهاست. خروجی مرتب شده شامل یک الحاق به ترتیب لیستها است که در ابتدا [B[0 بعد [B[1] بعد [B[2 و...... در انتها[B[9 میآیند.
زمان اجرای این مرتبسازی این گونه بدست میآید:
زمان وارد کردن n عنصر در آرایه A + زمان حرکت روی آرایه کمکی B (مرتب شده با مرتبسازی درجی)
که زمان این برابر میشود با:
(O(n) + n. O(2 - 1/n) = O(n
. بنابراین مرتبسازی سطلی در زمان خطی اجرا میشود.
پیادهسازی الگوریتم در ++C
# include <iostream>
using namespace std;
void bucketSort(int a[],int n, int max)
{
int* buckets = new int[max];
int SIZE = n;
for(int j = 0 ; j <= max ; j++)
buckets[j] = ۰;
for(int i = 0 ; i < SIZE ; i++)
++buckets[a[i]];
for(int i = 0 , j = 0 ; j <= max ; ++j)
for(int k = buckets[j] ; k > 0 ; k--)
a[i++] = j;
for(int i = 0 ; i < SIZE ; i++)
cout << a[i] << "";
cout << "\n";
}
int main()
{
int a[] = {۲۵٬۵۴٬۷۳٬۱۱٬۸۳٬۵۲٬۲۳٬۹۱};
int elem = sizeof(a)/sizeof(int);
int max = a[0];
for(int i = 0 ; i < elem ; i++)
if(a[i] > max)
max = a[i];
bucketSort(a, elem, max);
system("pause>nul");
}
پیادهسازی الگوریتم در جاوا
public class BucketSort {
public static void main(String[] args) {
int a[]=new int[]{2٬۵٬۷٬۱٬۸٬۵٬۲٬۹};
int elem=۱۰;
bucketSort(a,elem);
}
public static void bucketSort(int a[],int m){
int[] buckets = new int[m];
for(int j=0;j<m;j++)
buckets[j]=۰;
for(int i=0;i<a.length;i++)
++buckets[a[i]];
for(int i=0,j=0;j<m;++j)
for(int k=buckets[j];k>0;k--)
a[i++]=j;
for(int i=0;i<a.length;i++)
System.out.println(a[i]);
}
}
مقایسه با الگوریتمهای مرتبسازی دیگر
میتوان مرتبسازی سطلی را حالتی کلی از مرتبسازی شمارشی در نظر گرفت؛ در واقع، اگر اندازه هر سطل ۱ باشد، مرتبسازی سطلی به مرتبسازی شمارشی تبدیل میشود. اندازه متغیر سطلها در مرتبسازی سطلی اجازه میدهد که استفاده از حافظه جای O(M)از O(n) باشد، که M تعداد مقادیر متمایز است؛ در عوض رفتار مرتبسازی شمارشی در بدترین حالت O(n + M) خواهد بود. مرتبسازی سطلی با دو سطل نسخهای قابل اجرا از مرتبسازی سریع است که مقدار pivot محور مقدار میانهای از محدوده مقادیر انتخاب میشود. چون این انتخاب برای ورودیها با توزیع یکنواخت قابل اجرا است، روشهای دیگر انتخاب محور در مرتبسازی سریع مانند انتخاب تصادفی موجب مقاومت بیشتری برای دستهبندی کردن توزیع ورودیها میشود. الگوریتم مرتبسازی ادغامی n_راهه هم با توزیع لیست به n زیر لیست و مرتب کردن هر کدام آغاز میشود؛ اگرچه زیرلیستهایی که با مرتبسازی ادغامی ایجاد شدهاند شامل محدودههایی میشوند که با یکدیگر هم پوشانی دارند و بنابراین نمیتوانند دوباره به وسیلهٔ همان الحاق سادهای که در مرتبسازی سطلی انجام دادیم، ترکیب شوند. به جای آن باید با یک الگوریتم ادغام در محل اصلی خود جای داده شوند. اگرچه، این هزینه افزودن در مرحلهای که پراکنده کردن سادهتر انجام شد، موازنه شدهاست و اینکه میتوانیم مطمئن باشیم همه زیرلیستها به یک اندازهاند، کران خوبی برای بدترین حالت ایجاد میکند. مرتبسازی رقمی بالا-پایین میتواند حالت خاصی از مرتبسازی سطلی باشد اگر حتماً هر دو محدوده مقادیر و تعداد سطلها توانی از دو باشند. در نتیجه، اندازه هر سطل هم توانی از دو است، و این روش میتواند بهطور بازگشتی بکار بسته شود. این مشیء میتواند به مرحله پخش کردن سرعت دهد، از این رو ما فقط نیاز داریم بیت پیشوند را به نمایندگی از هر عنصر بیازماییم، تا سطل آن را تعیین کنیم.
مرتبسازی Postman
مرتبسازی Postman نوع دیگری از مرتبسازی سطلی است که برتریهای ساختار سلسله مراتبی عناصر را دارد، و نوعاً با مجموعهای از صفات توصیف میشود. این الگوریتمی است که ماشینهای مرتبسازی نامهها از آن در دفاتر پست استفاده میکنند: حالتهای اولیه، سپس دفاتر پست، سپس مسیرها، وغیره… چون کلیدها با یکدیگر مقایسه نمیشوند، زمان مرتبسازی O(cn) است، که c وابسته به اندازه کلید و تعداد سطل هاست. این مشابه مرتبسازی پایهای است که «بالا پایین،» یا «پرارزشترین رقم اول» کار میکند.
انواع
مرتبسازی بی قرار
«مرتبسازی بی قرار» (به انگلیسی: Shuffle sort) نوعی از مرتبسازی سطلی است که مرتبسازی را با حذف نخستین 1/8 از n آیتِم شروع میکند، آنها را به صورت بازگشتی مرتب میکند، سپس آنها را در یک آرایه قرار میدهد. این کار n/8 «سطلها» را میسازد تا 7/8 باقیمانده از آیتِمها توزیع شود. هر «سطل» در یک آرایه مرتبشده بهم میپیوندد. مرتبسازی بی قرار به عنوان قسمتی از یک مرتبسازی جی استفاده شدهاست.
جستارهای وابسته
منابع
| تئوری |  | |
|---|---|---|
| گونههای تعویضی | ||
| گونههای انتخابی | ||
| گونههای درجی | ||
| گونههای ادغامی | ||
| گونههای توزیعی | ||
| گونههای همرو | ||
| گونههای دوگانه |
| |
| گونههای دیگر |
| |