گرادیان کاهشی تصادفی
[1]گرادیان کاهشی تصادفی (به انگلیسی: (Stochastic Gradient (SGD) روشی مبتنی بر تکرار برای بهینهسازی یک تابع مشتقپذیر به نام تابع هدف (تابع هزینه) است که یک تقریب تصادفی از روش گرادیان کاهشی میباشد. در حقیقت گرادیان کاهشی تصادفی الگوریتمی در اختیار ما قرار میدهد که طی چند حلقهٔ تکرار مقدار کمینه یک تابع و مقادیری را که با ازای آنها تابع کمینه مقدار خود را میگیرد، بدست بیاوریم. به تازگی مقالهای[2] ابداع این روش را به هربرت رابینز و ساتِن مونرو (به انگلیسی: Herbert Robins and Sutton Monro) برای انتشار مقالهای در باب گرادیان کاهشی تصادفی در سال ۱۹۵۱ نسبت دادهاست. تفاوت گرادیان کاهشی تصادفی با گرادیان کاهشی استاندارد در این است که برخلاف گرادیان کاهشی استاندارد که برای بهینهسازی تابع هدف از تمام دادههای آموزشی استفاده میکند، گرادیان کاهشی تصادفی از گروهی از دادههای آموزشی که بهطور تصادفی انتخاب میشود برای بهینهسازی استفاده میکند. این روش در مسائل آماری و یادگیری ماشین کاربرد فراوانی دارد.
پیشینه
در برآوردهای آماری و یادگیری ماشین معمولاً مسائلی بهوجود میآید که در آنها نیاز است تابعی مانند از دادههای آماری با یک یا چند پارامتر (به شکل ضریب یا اشکال دیگر) تعریف کنیم و سپس این پارامترها را طوری مشخص کنیم که مجموع (یا میانگین) مقادیر تابع به ازای تک تک دادههای آماری، حداقل مقدار ممکن خود بشود. فرض کنید مجموعهای از دادههای آماری داریم و تابع را برای این دادهها فقط بر حسب یک پارامتر تعریف کردهایم، در این صورت با دادن داده ام از مجموعهٔ دادهها به تابع یک تابع از بدست میآوریم که آن را مینامیم. حال مسئله به پیدا کردن ای که عبارت زیر را کمینه میکند، ساده میشود:





یا به عبارت دیگر:

که همان تابع هدف یا تابع هزینه است.

برای حل چنین مسئلهای از گرادیان کاهشی استاندارد یا در مواردی از گرادیان کاهشی تصادفی استفاده میشود. در آمار کلاسیک زمینههایی مثل کمترین مربعات یا برآورد درستنمایی بیشینه، مسائلی مشابه در باب کمینهسازی مجموع جملات مطرح میشود. همچنین مسئلهٔ مینیممسازی جمع جملات در اصل کمینهسازی خطر تجربی (Empirical risk minimization) نیز مطرح میشود.
در بسیاری از موارد تابع هدف تابعی ساده میشود که اعمال روش گرادیان کاهشی روی آن پیچیده و زمانبر نیست در این موارد از روش گرادیان کاهشی استاندارد استفاده میشود، مانند خانوادهٔ توابع نمایی یک پارامتره که در ارزیابی توابع اقتصادی استفاده میشود. اما از آنجا که در روش گرادیان کاهشی استاندارد یا تصادفی به محاسبهٔ گرادیان تابع هدف در هر حلقه نیاز است، در بعضی از موارد که پارامترهای تابع هدف زیاد اند یا مجموعهٔ دادههای آموزشی بسیار بزرگ است محاسبهٔ انجام شده در هر حلقه میتواند بسیار زمانبر و پیچیده باشد به همین دلیل در این موارد از گرادیان کاهشی تصادفی استفاده میشود که در هر حلقه این عملیات را تنها برای بخشی از مجموعهٔ دادههای آموزشی که در اختیار داریم، انجام میدهد. در روش گرادیان کاهشی تصادفی در هر حلقه عملیات موردنظر بر روی تنها یک عضو مجموعهٔ دادههای آموزشی که در هر حلقه یهصورت تصادفی انتخاب میشود انجام نمیشود و در عوض بر روی زیرمجموعهای از آن انجام میشود؛ این امر دو دلیل دارد:[3]
- پراکندگی مقدار بدست آمده برای پارامتر را در هر حلقه کم میکند و همگرایی پایدارتر پیش میرود.
- بهرهگیری از عملیات ماتریسی که پیادهسازی بسیار سریعی دارد.
کاربردها
گرادیان کاهشی تصادفی یک الگوریتم محبوب و متداول برای یادگیری طیف گستردهای از مدلها در یادگیری ماشین است، از جمله ماشینهای بردار پشتیبانی، رگرسیون لجستیک و مدلهای گرافیکی.[4] الگوریتم بازگشت به عقب که عملاً الگوریتم استاندارد برای یادگیری شبکههای عصبی مصنوعی است در واقع روشی برای پیدا کردن گرادیان شبکه برای استفاده در گرادیان کاهشی تصادفی است.[5] گرادیان کاهشی تصادفی در جامعه ژئوفیزیک نیز کاربردهایی دارد مانند مسئله وارونگی کامل شکلموج (FWI).[6]
روش پیادهسازی
در پیادهسازی کلی گرادیان کاهشی تصادفی ابتدا بردار پارامترها که برداری است که شامل تمام پارامترهای تابع هزینه است را مینامیم. را برابر برداری دلخواه قرار میدهیم سپس برای هر بار بهروزرسانی این بردار یک عضو از مجموعهٔ دادههای آموزشی را به صورت تصادفی انتخاب کرده و با نرخ ، بردار حاصل از گرادیان تابع هزینه در نقطه را از کم میکنیم:


که در آن تابع هزینه و یک عضو از دادههای آموزشی است که به صورت تصادفی انتخاب شدهاست و نشاندهندهٔ جملهٔ ام از جملات تابع هدف است. نرخی است که با آن را بهروزرسانی میکنیم و مقداری تجربی دارد که اگر خیلی کوچک باشد زمان رسیدن به همگرایی را طولانی میکند و اگر خیلی بزرگ باشد ممکن است همگرایی رخ ندهد.[7]



در پیادهسازی دیگر در هر حلقه عضوی تصادفی از مجموعهٔ دادهها انتخاب نمیشود بلکه در هر حلقه کل مجموعه دادهها یک بار بهصورت تصادفی بازچینی میشود سپس به عملیات بهروزرسانی به ترتیب به ازای انجام میشود که نشاندهندهٔ اندازهٔ مجموعهٔ دادههای آموزشی است. شبه کد زیر این پیادهسازی را نشان میدهد:


به و مقدار اولیه بده تا زمانی که کمینه بدست بیاید تکرار کن دادههای آموزشی را به صورت تصادفی بازچینی کن برای از ۱ تا n تکرار کن:
همانطور که پیشتر اشاره شد معمولاً عملیات بهروز رسانی برای حاصل از یک تک عضو مجموعهٔ دادههای آموزشی انجام نمیشود و برای زیرمجموعهای از این دادهها انجام میشود که به آن دستهٔ کوچک میگویند.
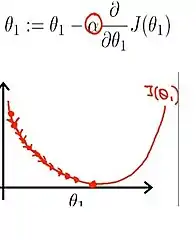 نحوهٔ عملکرد گرادیان کاهشی برای تابع یک ورودی
نحوهٔ عملکرد گرادیان کاهشی برای تابع یک ورودی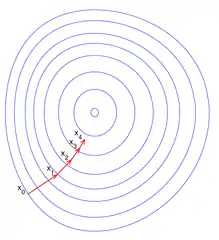 نحوهٔ عملکرد گرادیان کاهشی برای تابع دو ورودی
نحوهٔ عملکرد گرادیان کاهشی برای تابع دو ورودی
مثال
فرض کنید در یک مسئلهٔ یادگیری ماشین میخواهیم از روش کمترین مربعات استفاده کنیم به طوری که مجموعهای از دادههای آموزشی به شکل داریم که در هر دوتایی، نشاندهندهٔ مساحت یک خانه و نشاندهندهٔ قیمت خانه به آن مساحت باشد حال اگر بخواهیم نمودار را بر حسب با یک نمدار خطی تقریب بزنیم نیاز به روش کمترین مربعات داریم. طبق این روش بهترین تقریب این نمودار با خط زمانی اتفاق میافتد که تابع کمینه مقدار خود را داشته باشد. حال در این مثال تابع هزینه است و به روش گرادیان کاهشی تصادفی میشود مقدار را بدست آورد که با ازای آنها تابع هزینه کمینه شود و بهترین تقریب خطی یرای نمودار بدست بیاید.[8]








بسط
تا به حال چندین روش نوین برای کاهش سریعتر گرادیان کاهشی ابداع شده که ذیلاً بعضی مورد بررسی قرار گرفتهاند.[9][10][11][12][13]
تکانه (Momentum)
این روش برای اولین بار توسط روملهارت، هیلتون و ویلیامز معرفی شد.[9] در این روش میزان تغییر پارامتر در هر مرحله از بهینهسازی ذخیره شده تا در مرحله بعدی به شکل پایین از آن استفاده شود:



که با ترکیب این دو به عبارت پایین میرسیم:

روش momentum باعث میشود که مسیر پارامتر خیلی تغییر نکند و نوسانات شدیدی نداشته باشد. استفاده از این روش در شبکههای عصبی مصنوعی متداول است و معمولاً موجب بهبود دقت شبکههای عصبی میشود.[14]
میانگین (Averaging)
در این روش در هر مرحله پارامترهای مرحله پیشین ذخیره میشود و در نهایت میانگین آنها به عنوان پارامتر بهینه برگردانده میشود[10] یعنی .


گرادیان تطبیقی (AdaGrad)
روش آداگراد یا گرادیان تطبیقی برای اولین بار در سال ۲۰۱۱ معرفی و منتشر شد.[11][15] این روش برای هر بُعدِ پارامتر یک نرخ یادگیری جداگانهای در نظر میگیرد؛ نرخ یادگیری همان در معادله بالاست. برای ابعاد خلوتتر (sparse) معمولاً این روش نرخ یادگیری را افزایش میدهد و برای ابعادی که مقادیر صفر کمتری دارند نرخ یادگیری را کاهش میدهد. این روش اغلب برای مسائلی که با دادههای خلوت سروکار دارند مانند پردازش تصویر یا زبانهای طبیعی بهینهتر است و همگرایی را تسریع میبخشد.[11]
نرخ یادگیری برای ابعاد مختلف پارامتر از قطر اصلی ضرب خارجی بدست میآید. در این معادله گرادیان در مرحله است و نرخ یادگیری برای بُعدِ برابر خواهد بود با:





حال میتوان پارامتر را به صورت پایین بهروز کرد:

این معادله برای بعد برابر خواهد بود با:

از آنجا که در نرخ یادگیری برای بُعدِ j ام پارامتر بر مقدار تقسیم میشود، ابعدای که خلوتترند سریعتر نرخ یادگیریشان کاهش مییابد.[16] اگرچه روش گرادیان تطبیقی برای مسائل محدب طراحی شدهاست ولی برای مسائل غیر محدب نیز نتایج خوبی به بار آوردهاست.[17]

RMSProp
در این روش همانند گرادیان تطبیقی برای هر بُعدِ پارامتر نرخ یادگیری جداگانهای در نظر گرفته میشود.[12] ایده اصلی این است که نرخ یادگیری را برای یک بُعد بر میانگین گرادیانهای آن بُعد تقسیم کنیم؛ بنابراین، ابتدا میانگین را به این شکل محاسبه میکنیم:

در این معادله ضریب فراموشی است و پارامترها به این صورت بروز میشوند:


این روش نتایج بسیار خوبی برای مسائل مختلف بهینهسازی دادهاست.[18]
Adam
این روش مشابه روش RMSProp است با این تفاوت که هم از میانگین گرادیان و هم از گشتاورهای دوم آن به شکل پایین استفاده میشود.[13]





در اینجا برای جلوگیری از صفر شدن مخرج است، و ضرایب فراموشی گرادیان و گشتاور دوم گرادیان هستند. مربع گرادیانها مولفهای است. کاربرد ضرایب فراموشی گرادیان و گشتاور دوم گرادیان بیشتر برای جبران فاصله مقدار تقریبی از مقدار واقعی گرادیان می باشد،که معمولا برای زمانی که t کوچک است مفید می باشد. روش Adam رایج ترین روش در شبکه های عصبی عمیق برای تعلیم شبکه می باشد



منابع
- یادکرد خالی (کمک)
- Mei, Song; Montanari, Andrea; Nguyen, Phan-Minh (2018-08-14). "A mean field view of the landscape of two-layer neural networks". Proceedings of the National Academy of Sciences. 115 (33): E7665–E7671. doi:10.1073/pnas.1806579115. ISSN 0027-8424. PMID 30054315.
- "Unsupervised Feature Learning and Deep Learning Tutorial". deeplearning.stanford.edu. Archived from the original on 20 اكتبر 2018. Retrieved 2018-10-29. Check date values in:
|archivedate=(help) - Jenny Rose Finkel, Alex Kleeman, Christopher D. Manning (2008). Efficient, Feature-based, Conditional Random Field Parsing بایگانیشده در ۱۴ اوت ۲۰۱۸ توسط Wayback Machine. Proc. Annual Meeting of the ACL.
- LeCun, Yann A., et al. "Efficient backprop." Neural networks: Tricks of the trade. Springer Berlin Heidelberg, 2012. 9-48
- Díaz, Esteban and Guitton, Antoine. "Fast full waveform inversion with random shot decimation". SEG Technical Program Expanded Abstracts, 2011. 2804-2808
- S، Suryansh (۲۰۱۸-۰۳-۱۲). «Gradient Descent: All You Need to Know». Hacker Noon. بایگانیشده از اصلی در ۱ مه ۲۰۲۰. دریافتشده در ۲۰۱۸-۱۰-۲۹.
- Miller، Lachlan (۲۰۱۸-۰۱-۱۰). «Machine Learning week 1: Cost Function, Gradient Descent and Univariate Linear Regression». Medium. دریافتشده در ۲۰۱۸-۱۰-۲۹.
- Rumelhart, David E.; Hinton, Geoffrey E.; Williams, Ronald J. (8 October 1986). "Learning representations by back-propagating errors". Nature. 323 (6088): 533–536. Bibcode:1986Natur.323..533R. doi:10.1038/323533a0.
- Polyak, Boris T.; Juditsky, Anatoli B. (1992). "Acceleration of stochastic approximation by averaging" (PDF). SIAM J. Control Optim. 30 (4): 838–855. doi:10.1137/0330046. Archived from the original (PDF) on 12 January 2016. Retrieved 20 May 2019.
- Duchi, John; Hazan, Elad; Singer, Yoram (2011). "Adaptive subgradient methods for online learning and stochastic optimization" (PDF). Journal of Machine Learning Research. 12: 2121–2159. Archived from the original (PDF) on 28 May 2019. Retrieved 20 May 2019.
- Tieleman, Tijmen and Hinton, Geoffrey (2012). Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning
- Diederik, Kingma; Ba, Jimmy (2014). "Adam: A method for stochastic optimization". arXiv:1412.6980 [cs.LG].
- Zeiler, Matthew D. (2012). "ADADELTA: An adaptive learning rate method". arXiv:1212.5701 [cs.LG].
- Perla, Joseph (2014). "Notes on AdaGrad" (PDF). Archived from the original (PDF) on 2015-03-30.
- Zeiler, Matthew D. (2012). "ADADELTA: An adaptive learning rate method". arXiv:1212.5701 [cs.LG].
- Gupta, Maya R.; Bengio, Samy; Weston, Jason (2014). "Training highly multiclass classifiers" (PDF). JMLR. 15 (1): 1461–1492. Archived from the original (PDF) on 25 اكتبر 2018. Retrieved 21 مه 2019. Check date values in:
|archive-date=(help) - Hinton, Geoffrey. "Overview of mini-batch gradient descent" (PDF). pp. 27–29. Archived from the original (PDF) on 23 November 2016. Retrieved 27 September 2016.