کمترین مربعات
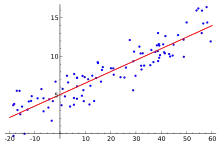
روش کمترین مربعات روشی در تحلیل رگرسیون است که برای حل دستگاه معادلاتی به کار میرود که تعداد معادلههایش بیش از تعداد مجهولهایش است. مهمترین کاربرد روش کمترین مربعات در برازش منحنی بر دادهها است. مدل برازش شده بر دادهها، مدلی است که در آن کمیت کمینه باشد.


| بخشی از مجموعه مباحث دربارهٔ آمار |
| تحلیل رگرسیون |
|---|
 |
| مدلها |
|
|
|
|
| تخمین |
|
|
|
|
| پیشزمینه |
|
|
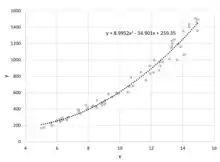
این روش را نخستین بار کارل فردریش گاوس در سال ۱۷۹۴ استفاده کرد.[1] روش کمترین مربعات در زبان برنامهٔ نویسی R، بیشتر نرمافزارهای آماری و ریاضی (مانند Excel, SPSS, MATLAB و …) و ماشین حسابهای مهندسی وجود دارد.
تاریخچه
منشأ روش کمترین مربعات از نجوم و یافتن موقعیت ستارگان بودهاست.
ساختار ریاضی
برای برازش منحنی بر دادهها، فرض میکنیم اندازهگیریها مستقل از هم انجام شدهاند و خطای نیز در مقابل خطای قابل صرف نظر است (مقادیر بدون خطا هستند). تابع علاوه بر ، به ثوابتی که آنها را با بردار نشان میدهیم بستگی دارند. هدف، پیدا کردن مقادیر است، به گونهای که تابع دقیقترین پیشبینی را از ارائه دهد. به این منظور، کمیت باقی مانده را به صورت







تعریف میکنیم. اگر هر از توزیع نرمال حول مقدار واقعی با پهنای پیروی کند، احتمال به دست آوردن متناسب است با:




است. احتمال مشاهدهٔ تمام مقادیر اینطور به دست میآید:


کمیت که در نما قرار دارد به صورت

تعریف میشود. پس هدف، پیدا کردن است؛ به گونهای که کمینه شود.

برای بدست پارامتر بهینه باید از تابع مربعات گرادیان گرفته و آن را برابر با صفر قرار دهیم:[2]

کمترین مربعات بدون وزن
اگر فرض کنیم ها برای همهٔ دادهها برابر است، خواهیم داشت:

سایر روشها
سایر انواع روش کمترین مربعات، عبارتاند از کمترین مربعات دارای قید (Constrained)، کمترین مربعات وزندار (Weighted) و کمترین مربعات مجموع (Total)
نمونهها
برازش خط
برای خط،

با مشتقگیری جزئی، خواهیم داشت:


در نتیجه:






کمترین مربعات خطی
اگر فرض کنیم بُعد ورودی است، یعنی و تابع یک تابع خطی است، مسئله رگرسیون به یک مسئله بهینهسازی برای پیداکردن پارامتر تبدیل میشود. به این معنی که ما یک پارامتر چند متغیره به اسم داریم و سعی میکنیم را با ترکیبی خطی از تخمین بزنیم یعنی . حال اگر یک بعد دیگر به متغیر اضافه کنیم و مقدارش را همیشه عدد ثابت در نظر بگیریم () و را به صورتِ تغییر دهیم، تخمینی که از داریم در واقع ضرب نقطه ای بردار ورودی و بردار پارامترهای ماست یعنی . حال فرض کنیم که تعداد مثالهایی که قرار است برای تخمین پارامترها استفاده کنیم










است و این مثالها را به این شکل نمایش دهیم . همانطور که در مقدمه گفتیم پارامتر بهینه پارامتری است که تابع را به حداقل برساند یعنی تابع پایین را:




از آنجا که تابع نسبت به تابعی کاملاً محدب است، در نقطه مینیمم گرادیان ما صفر خواهد بود و این روش پارامتر بهینه را بدست میدهد.[4] برای تسهیل کار شکل تابع را با بکارگیری چند ماتریس ساده میکنیم. دو ماتریس برای این کار نیاز داردیم ماتریس و ماتریس . ماتریس ماتریس ورودهای چندمتغیره ماست. هر سطر معادل یک نمونه از داده ماست، سطر ام برابر است با امین نمونه ورودی ما یعنی بردار ، از اینرو یک ماتریس خواهد بود. ماتریس از طرف دیگر برابر است با مجموعه متغیرهای وابسته داده ما. سطر ام این ماتریس برابر است با متغیر وابسته برای امین نمونه داده ما یا همان . ماتریس یک ماتریس است. با کمک این دو ماتریس میتوان تابع ضرر را به شکل ذیل تعریف کرد:








حال گرادیان این تابع را نسبت به پیدا میکنیم که میشود:

با برابر قرار دادن گرادیان با صفر پارامتر بهینه بدست میآید:

پس پارامتر بهینه ما برابر است با:

خطای روش کمترین مربعات



پیادهسازی روش کمترین مربعات
زبان R
در زبان R، برازش تابع خطی به فرم

بر دادهها به کمک تابع lsfit انجام میشود.[5] قطعه کدهای زیر، نحوهٔ پیادهسازی و خروجی را برای یک تابع ۲ متغیره نشان میدهد.
x = matrix(c(1.19, 1.08, 2.45, 2.53, 3.30, 2.97, 1.65, 0.58, 0.26, 4.39, 4.06, 0.55, 1.80, 1.68, 3.24, 2.23, 3.80, 4.63, 3.78, 4.84, # x_1 values
1.60, 5.88, 1.55, 1.86, 1.06, 3.85, 9.29, 13.04, 14.52, 0.50, 2.89, 16.99, 15.42, 17.36, 11.82, 16.38, 11.06, 9.08, 17.75, 15.17), # x_2 values
ncol = 2)
y = c(23.59, 31.95, 33.15, 34.00, 37.80, 41.07, 42.38, 43.76, 44.10, 44.16, 46.83, 50.52, 56.81, 59.04, 60.12, 61.84, 62.16, 64.18, 75.45, 76.77)
lsfit(x, y, intercept = TRUE)
| خروجی کد | ||||||||||||||||||||||||||||||||||||
|
نرمافزار Excel
در نرمافزار اکسل، برازش تابع خطی به فرم
بر دادهها به کمک تابع LINEST انجام میشود.[6] این تابع جزو توابع آرایهای است و با فشردن Ctrl+Enter اجرا میشود. ورودی تابع به شکل
LINEST(known_y's, [known_x's], [const], [stats])
است که در آن به ترتیب مقادیر y، مقادیر x و سپس دو مقدار بولی وارد میشوند که اولی برای مبدأ گذر نبودن و دومی برای بازگرداندن مقادیر خطا، رگرسیون و … است. خروجی تابع در جدولی به صورت زیر برگردانده میشود:
| F | E | D | C | B | A |
|---|---|---|---|---|---|
| ... | |||||
| ... | |||||
















منظور از خطا است. خانههای ردیف دوم به بعد، در صورتی نشان داده میشوند که stats=TRUE باشد.

ماشین حساب CASIO fx-82ES
اکثر ماشین حسابهای مهندسی مجهز به ویژگی برازش منحنی به روش کمترین مربعات هستند. در ماشین حسابهای کاسیو این ویژگی در بخش STAT قرار دارد.
لاسو (LASSO)
لاسو یک مدل تنظیم شده (به انگلیسی: Regularized) از مدل کمترین مربعات است. تنظیم به این صورت است که یا نرم L1-norm کمتر از مقدار مشخصی باشد. این معادل این است که در هنگام بهینهسازی هزینهٔ کمترین مربعات را نیز اضافه کرده باشیم. معادل بیزی این مدل این است که توزیع پیشین توزیع لاپلاس را برای پارامترهای مدل خطی استفاده کرده باشیم.


تفاوت اساسی بین مدل ridge regression و لاسو این است که در اولی علیرغم افزایش جریمه، ضرایب در عین غیرصفر بودن کوچکتر میشوند، علیرغم اینکه صفر نمیشوند، در صورتی که در لاسو با افزایش جریمه، تعداد بسیار بیشتری از ضرایب به سمت صفر میل میکنند.[7] میتوان بهینهسازی مربوط به لاسو را با روشهای بهینهسازی درجه دوم یا در حالت کلی بهینهسازی محدب انجام داد. به دلیل ایجاد ضرایب کم، لاسو در بسیاری از کاربردها مانند سنجش فشرده (به انگلیسی: compressed sensing) مورد استفاده قرار میگیرد.
لاسو در رگرسیون خطی
پیچیدگی مدلهای پارامتری با تعداد پارامترهای مدل و مقادیر آنها سنجیده میشود. هرچه این پیچیدگی بیشتر باشد خطر بیشبرازش (Overfitting) برای مدل بیشتر است.[8] پدیده بیشبرازش زمانی رخ میدهد که مدل بجای یادگیری الگوهای داده، داده را را حفظ میکند و در عمل یادگیری به خوبی انجام نمیشود. برای جلوگیری از بیشبرازش در مدلهای خطی مانند رگرسیون خطی جریمهای به تابع هزینه اضافه میشود تا از افزایش زیاد پارامترها جلوگیری شود. به این کار تنظیم مدل یا Regularization گفته میشود.[9] یکی از این روشهای تنظیم مدل روش لاسو است که در آن ضریبی از نُرمِ به تابع هزینه اضافه میشود، در رگرسیون خطی تابع هزینه به شکل پایین تغییر میکند:


این روش تنظیم مدل باعث میشود که بسیاری از پارامترهای مدل نهائی صفر شوند و مدل به اصلاح خلوت (Sparse) شود.[7]
جستارهای وابسته
پانویس
- Bretscher, Otto (1995), Linear Algebra With Applications, 3rd ed., Upper Saddle River NJ: Prentice Hall
- Yan, Xin (2009). Linear Regression Analysis: Theory and Computing. World Scientific. ISBN 9789812834119.
- Taylor, John (1997). An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements, 2nd ed. University Science Books. ISBN 9780935702750.
- Rencher, Alvin C.; Christensen, William F. (2012-08-15). Methods of Multivariate Analysis (به English). John Wiley & Sons. p. 155. ISBN 9781118391679.
- https://stat.ethz.ch/R-manual/R-devel/RHOME/library/stats/html/lsfit.html The R manual: lsfit function LINEST function
- https://support.office.com/en-us/article/linest-function-84d7d0d9-6e50-4101-977a-fa7abf772b6d Microsoft Office Excel Help: LINEST function
- Natarajan, B. K. (1995). "Sparse Approximate Solutions to Linear Systems". SIAM Journal on Computing. 24 (2): 227–234. doi:10.1137/s0097539792240406. ISSN 0097-5397.
- Bühlmann, Peter; van de Geer, Sara (2011). "Statistics for High-Dimensional Data". Springer Series in Statistics. doi:10.1007/978-3-642-20192-9. ISSN 0172-7397.
- Bühlmann, Peter; van de Geer, Sara (2011). Theory for ℓ1/ℓ2-penalty procedures. Berlin, Heidelberg: Springer Berlin Heidelberg. pp. 249–291. doi:10.1007/978-3-642-20192-9_8. ISBN 9783642201912.