درخت ون امد بوآس
یک درخت van Emde Boas (یا صف اولویت van Emde Boas) که به اسم درخت vEB نیز خوانده میشود، یک درخت ساختار داده است که یک آرایه شرکت پذیر را با m بیت کلیدهای عدد صحیح پیادهسازی میکند.زمان اجرای این عملیات (O(log m میباشد، توجه داشته باشید که m اندازه کلیدها میباشد، بنابراین ( O ( Log m در یک درختی که در آن هر کلیدی زیر n مجموعه قرار دارد برابر (O(log n است، به صورت نمایی، این بهتر از یک درخت جستجوی دوتایی خود متعادل میباشد. همانطور که در زیر بیان شده، در زمانی که آنها تعداد عناصر زیادی را شامل میشوند، بازده مساحتی خوبی دارند. . آنها توسط یک تیم به رهبری پیتر ون امدبوس( Peter van Emde Boas ) در 1997 اختراع شدند.[1]
| درخت van Emde Boas | |
|---|---|
| گونه | Non-binary tree(درخت غیر دوتایی) |
| اختراع | 1977 |
| مخترع | Peter van Emde Boas |
| پیچیدگی سیستماتیک در نماد O بزرگ | |
| مساحت | (O(M |
| جستجو | (O(log log M |
| درج | (O(log log M |
| حذف | (O(log log M |
عملیاتهای پشتیبانی شده
عملیاتی که با درخت vEB پشتیبانی میشوند آنهایی هستند که آرایه شرکت پذیر مرتب شده دارند که شامل عملیات شرکت پذیر منظم معمولی به همراه دو عملیات منظم دیگر، یافتن بعدی و یافتن قبلی میشود:[2]
درج کردن : یک کلید وارد کنید / مقدار به همراه یک کلید عدد m
حذف کردن : کلید را حذف کنید / مقدار به همراه یک کلید داده شده
جستجو : مقدار را با توجه به کلید داده شده پیدا کنید
یافتن بعدی : کلید را پیدا کنید / مقدار به همراه کوچکترین کلید حداقل یک k داده شده
یافتن قبلی : کلید را پیدا کنید / مقدار به همراه بزرگترین کلید حداکثر یک k داده شده
چگونگی عملیات
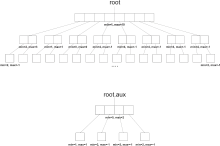
برای سادگی کار، یک عدد صحیح k را در log2 m = k قرار دهید . M=2m را تعریف کنید.
T یک درخت vEB بالای جهان {0,...,M-1} } یک منحنی ریشهای دارد که آرایه T.children به طول M1/2 را ذخیره میکند. [T.children[i یک اشاره گر به درخت vEB است که برای مقدارهای {iM1/2,...,(i+1)M1/2-1 } مسئول است. به علاوه ، T دو مقدار T.min و T.max را به همراه یک درخت vEB کمکی، T.aux، ذخیره میکند.
اطلاعات در یک درخت vEB به گونه زیر ذخیره شدهاست :
کوچکترین مقدار موجود در درخت در T.min و بزرگترین مقدار در T.max ذخیره میشوند. این دو مقدار در هیچ جای دیگر درخت vEB ذخیره نمیشود. اگر T خالی است پس ما از قاعده T.max=-1 و T.min=M استفاده می کنیم . هر مقدار x دیگر در زیر درخت [T.children[i قرار میگیرد که در آن . درخت کمکی T.aux نگه میدارد که کدام زیر مجموعه ها (children) غیر خالی هستند. پس T.aux مقدار j را شامل میشود که این فقط در صورتی است که [T.children[j غیر خالی است .

یافتن بعدی
عملیات یافتن بعدی (FindNext(T, x که به دنبال یک جانشین برای یک عنصر x در یک درخت vEB میباشد اینگونه پیش میرود : اگر x≤T.min باشد پس جستجو کامل است، و پاسخ T.min است . اگر x>T.max باشد آنوقت عنصر بعدی وجود ندارد ، M را برمیگرداند . در غیراینصورت ، i=x/M1/2 . اگر x≤T.children[i].max باشد، پس مقداری که دنبالش می گردید در [T.children[i است پس جستجو به حالت بازگشتی در [T.children[i ادامه پیدا میکند. در غیراینصورت، ما به دنبال مقدار i در T.aux می گردیم . این به ما شاخص j را از اولین زیردرخت می دهد که شامل یک عنصر بزرگتر از x میباشد. الگوریتم سپس به T.children[j].min بر می گردد. عنصر یافت شده در مقطع children نیاز دارد با ارقام بالا ترکیب شود تا یک عنصر کامل بعدی را تشکیل دهد.
FindNext(T, x)
if (x <= T.min)
return T.min
if (x> T.max) //no next element
return M
i = floor(x/sqrt(M))
lo = x % sqrt(M)
hi = x - lo
if (lo <= T.children[i].max)
return hi + FindNext(T.children[i], lo)
return hi + T.children[FindNext(T.aux,i+1)].min
توجه داشته باشید که در هر حال الگوریتم عملیات در (o(1 انجام میشود و سپس احتمالاً به روی یک زیردرخت روی یک کلیت به اندازه M1/2 (یک عدد کلی m/2) بر می گردد. این باعث عودت زمان عملیات (T(m)=T(m/2) + O(1 که معادل (O(log m) = O(log log M است، میشود .
درج کردن
فراخوان (Insert(T, x که یک مقدار x را در درخت vEB T درج میکند، به گونه زیر عمل میکند :
اگر T خالی است پس T.min = T.max = x و کار تمام است.
در غیر اینصورت، اگر x<T.min است، پس ما T.min را در زیردرخت i که مسئول T.min است قرار می دهیم و
سپس T.min = x میشود. اگر [T.children[i قبلاً خالی بوده، پس ما همچنین i را در T.aux قرار می دهیم.
در غیر اینصورت، اگر x>T.max باشد، ما T.max را در زیردرخت i که مربوط به T.max است قرار می دهیم و سپس T.max = x میشود . اگر [T.children[i قبلاً خالی بوده، پس ما همچنین i را در T.aux قرار می دهیم.
در غیر اینصورت، اگر T.min< x < T.max باشد، بنابراین ما x را در زیردرختی قرار می دهیم که برای x است. اگر [T.children[i قبلاً خالی بوده، پس ما همچنین i را در T.aux قرار می دهیم.
در کد :
Insert(T, x)
if (T.min> T.max) // T is empty
T.min = T.max = x;
return
if (T.min = T.max)
if (x <T.min)
T.min = x;
if (x> T.max)
T.max = x;
return
if (x <T.min)
swap(x, T.min)
if (x> T.max)
swap(x, T.max)
i = x/sqrt(M)
Insert(T.children[i], x % sqrt(M))
if (T.children[i].min = T.children[i].max)
Insert(T.aux, i)
بهترین راه برای بازدهی این عملیات این است که درج کردن یک عنصر در یک درخت vEB خالی حدود (O(1 زمان ببرد . بنابراین اگرچه بعضی اوقات الگوریتم دو فراخوان بازگشتی دارد، این فقط در زمانی رخ می دهد که اولین فراخوان بازگشتی در یک زیردرخت خالی باشد. درست مثل قبل، این عملیات بازگشتی در زمان (T(m)=T(m/2) + O(1 انجام میشود .
حذف کردن
حذف از درخت VEB بیشترین مهارت را در میان عملیاتها نیاز دارد. فراخوان (Delete(T, x که یک مقدار x را از درخت (vEB (T حذف میکند، همانند زیر عمل میکند :
اگر T.min = T.max = x باشد سپس x تنها عنصری است که در درخت ذخیره شدهاست و ما T.min = M و T.max = -1 تا نشان دهیم درخت خالی است .
در غیر اینصورت، اگر x = T.min پس ما نیاز داریم دومین کمترین مقدار y را در درخت vEB پیدا کنیم، آن را از جای فعلیش حذف کنیم و آن وقت T.min=y . دومین کمترین مقدار y یا T.max است یا T.children[T.aux.min].min . پس این میتواند در زمان (O(1 پیدا شود . در شرایط بعدی، ما y را از زیر درختی که او را در خود جای داده حذف می کنیم .
بهطور مشابه، اگر x = T.max باشد، ما باید دومین بزرگترین مقدار y را در درخت vEB پیدا کنیم، آن را از جایگاهش حذف کنیم و آن وقت T.max=y میشود . دومین بزرگترین مقدار y یا T.min است یا T.children[T.aux.max].max . پس این میتواند در زمان (O(1 پیدا شود . در شرایط بعدی، ما y را از زیر درختی که او را در خود جای داده حذف می کنیم .
در شرایطی که T.min ، x یا T.max نیست و T هیچ عنصر دیگری ندارد ما می دانیم که x در T نیست و بدون هیچ عملیاتی برمی گردیم.
در غیر اینصورت ما شرایط معمولی را داریم که در آن x≠T.min و x≠T.max است . در این موقع، ما x را از زیر درخت [T.children[i که شامل x است، حذف میکنیم .
در هر کدام از شرایط فوق، اگر ما آخرین عنصر x یا y را از هر زیر درخت [T.children[i حذف کنیم، آنگاه ما i را از T.aux حذف می کنیم .
در کد :
Delete(T, x)
if (T.min == T.max == x)
T.min = M
T.max = -1
return
if (x == T.min)
if (T.aux is empty)
T.min = T.max
return
else
x = T.children[T.aux.min].min
T.min = x
if (x == T.max)
if (T.aux is empty)
T.max = T.min
return
else
x = T.children[T.aux.max].max
T.max = x
if (T.aux is empty)
return
i = floor(x/sqrt(M))
Delete(T.children[i], x%sqrt(M))
if (T.children[i] is empty)
Delete(T.aux, i)
و دوباره اینکه، بازدهی این عملیات وابسته به این حقیقت است که حذف از یک درخت vEB که تنها یک عنصر دارد فقط زمان مشخصی می برد . خصوصاً، آخرین خط قانون فقط در حالتی اجرا میشود که x تنها عنصر در [T.children[i قبل از عملیات حذف بوده باشد .
بحث
این تفکر که log m یک عدد صحیح است غیرضروری است . اگر عملیات (x/sqrt(m و (x%sqrt(m با تنها گرفتن ترتیب بالاتر از سقف (m/2) و ترتیب پایینتر از کف (m/2) ارقام x به ترتیب میتوانند جایگزین شوند. در هر ماشین موجود این نسبت به تقسیم و محاسبات باقیمانده کارآمد تر است .
انجام عملیاتی که در بالا توضیح داده شد از اشاره گرها استفاده میکند و یک مساحت کلی را اشغال میکند . این میتواند اینگونه دیده شود که عملیات بازگشت اینگونه است .
حل آن به این ختم میشود : .
خوشبختانه با استنتاج ( قیاس کل از جز) میتوان را ثابت کرد .[3]
در اجراهای کاربردی، به خصوص در ماشینهایی که دستورالعملهای Find First zero و shift-by-k دارند، عملکرد میتواند با یک بار تغییر به یک آرایه رقمی m برابر با اندازه کلمه ( یا یک چند رقمی کوچک) خیلی پیشرفت کند . از آنجایی که همه عملیاتهایی که به روی یک تک کلمه هستند زمان مشخصی می برند، این عملکرد اسیمپاتیک (asymptotic ) را تحت تأثیر قرار نمیدهد، اما با وجود حفظ کاربردی و مهم زمان و فضا در این مهارت مانع ذخیره اکثر اشاره گرها و ارجاع تعدادی اشاره گر میشود.
یک بخش واضح و مثبت درختهای vEB دور انداختن درختهای زیر مجموعه خالی است . این درختهای vEB را در زمانی که خیلی عنصر دارند فشرده میکنند چون هیچ درخت زیر مجموعهای به وجود نمیآید مگر اینکه چیزی باید به آنها اضافه شود. در ابتدا، هر عنصر اضافه شده حدود (Log(m تا درخت جدید خلق میکند که با هم در حدود m/2 اشاره گر دارند. همزمان با اینکه درخت بزرگ میشود، زیر درختهای بیشتری دوباره استفاده میشوند، به خصوص آنهایی که بزرکتر هستند . در یک درخت کامل با 2m عنصر، فقط مساحت (O(2m استفاده میشود و اینکه بر خلاف درخت جستجوی دوتایی بیشتر این مساحت برای ذخیره اطلاعات استفاده میشود : حتی برای میلیونها عنصر و هزاران اشاره گر در یک درخت کامل vEB .




در حالی که برای درختهای کوچک بالاسری که به درختهای vEB مربوط است خیلی عظیم است : در ترتیب 2m/2 . به همین دلیل است که آنها در عمل خیلی محبوب نیستند . یک راه مقابله با این محدودیت استفاده از تعداد مشخصی از ارقام در هر مقطع است . ساختارهای دیگر که شامل آزمایشهای y-fast و x-fast میشوند نیز پیشنهاد شده اند که زمانهای تحقیق به روزتری دارند، اما فقط از فضای (O(n Log M یا (O(n استفاده میکنند که در آنها n تعداد عناصری است که در ساختار اطلاعاتی ذخیره شدهاست .
منابع
- Erik Demaine, Shantonu Sen, and Jeff Lindy. Massachusetts Institute of Technology. 6.897: Advanced Data Structures (Spring 2003). Lecture 1 notes: Fixed-universe successor problem, van Emde Boas. Lecture 2 notes: More van Emde Boas, ....
پانویس
- Peter van Emde Boas, R. Kaas, and E. Zijlstra: Design and Implementation of an Efficient Priority Queue (Mathematical Systems Theory 10: 99-127, 1977)
- Gudmund Skovbjerg Frandsen: Dynamic algorithms: Course notes on van Emde Boas trees (PDF) (University of Aarhus, Department of Computer Science)
- Rex, A. "Determining the space complexity of van Emde Boas trees". Retrieved 2011-05-27.