درخت پسوندی
در علوم رایانه، یک درخت پسوندی (درخت PAT، که با نام قدیمیتر درخت موقعیت نیز شناخته شده است) یک ترای شامل پسوندهای یک رشتهی داده شده به عنوان کلید و مکان آنها در رشته به عنوان مقدار است. درختهای پسوندی پیادهسازی سریع شمار زیادی از عملیاتهای رشتهای مهم را ممکن میسازند.
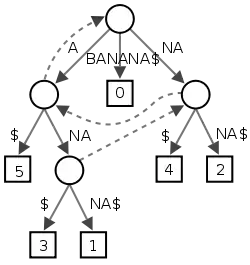
BANANA. هر زیر رشته با یک کاراکتر خاص $ خاتمه یافته است. ۶ مسیر از ریشه به برگها (که با مربعها نمایش داده شدهاند) متناظر با ۶ پسوند رشتهٔ BANANA میباشند. اعداد موجود در مربعها بیانگر مکان شروع پسوند متناظر هستند. پیوندهای پسوندی به صورت خط چین رسم شدهاند.درخت پسوندی برای یک رشتهٔ ، درختی است که یالهای آن با رشتههایی برچسب خوردهاند، به طوری که هر پسوند ، متناظر با دقیقاً یک مسیر از ریشهٔ درخت به یک برگ است؛ بنابراین، این درخت، یک درخت مبنا برای پسوندهای خواهد بود.

ساخت چنین درختی برای رشتهٔ به زمان و فضای خطی بر حسب طول نیاز دارد. وقتی این درخت ساخته شود، عملیات رشتهای، مانند یافتن یک زیررشته در ، یافتن یک زیررشته با یک تعداد مجاز مشخص شده برای خطاها، یافتن تطابقها برای یک الگوی عبارت باقاعده و غیره، میتوانند به سرعت انجام شوند. درختهای پسوندی یکی از اولین راه حلهای با زمان خطی برای مسئلهٔ بزرگترین زیررشته مشترک را نیز میسر ساختهاند. این افزایش سرعتها هزینهای دارند: ذخیرهسازی یک درخت پسوندی برای یک رشته، معمولاً به فضای بیشتری نسبت به ذخیرهسازی خود رشته نیاز دارد.
تعریف
درخت پسوندی برای رشتهٔ با طول درختی است که در شرایط زیر صدق کند:

- دقیقا دارای n برگ است که از 1 تا n شمارهگذاری شدهاند.
- تمامی گرههای داخلی (در بعضی موارد، به جز ریشه) حداقل دو فرزند دارند.
- هر یال با یک زیررشتهی ناتهی از برچسب خورده است.
- هیچ دو یالی که از یک گره بیرون میآیند نمیتوانند برچسبهایی داشته باشند که با یک کاراکتر شروع میشوند.
- رشتهی بدست آمده از الحاق زیررشتههای مسیر از ریشه تا برگ iاُم، معرف پسوند [i..n] برای هر i از 1 تا n است.
از آنجایی که یک اینچنین درختی برای همهٔ رشتهها وجود ندارد، به انتهای ، یک کاراکتر ترمینال (معمولاً با $ نشان میدهند) که در الفبای اصلی وجود ندارد الحاق میشود. مثلا اگر سعی کنید برای رشته abab آن را بسازید متوجه این نکته میشوید چون پسوند ab پیشوند پسوند رشته کامل(abab) است. از آنجایی که تمامی گرههای داخلی به جز ریشه شاخه شاخه میشوند، تعداد این گرهها حداکثر خواهد بود و تعداد کل گرهها برابر خواهد بود با ( برگ، گره داخلی، و یک ریشه).


کاربردها
درخت پسوندی داده ساختاری است که با ساخت آن میتوان انواع مختلف پرسمانها را پاسخ داد. ساخت آن با شرایطی در قابل انجام است. یکی از کاربردهای اصلی آن جستجوی رشته است.

در حوضه بیوانفورماتیک یکی از مسائل معروف و اصلی پیدا کردن تعدادی الگوی خوانده شده از ژنوم ( read ) در رشته طولانیتر( Text ) است. ابعاد read ها در حد چند صد حرف و ابعاد ژنوم در حد میلیارد هستند. الگوریتم تطابق رشته با زمان خطی برای یک الگو برای این مسئله مناسب نیستند و اگر روی تمام read ها به ترتیب اجرا کنیم بهینه نیست، چون تعداد آنها بسیار زیاد است. ساختار درخت پسوندی طوری است که چون تمام پسوندهای رشته در یک درخت پیشوندی ذخیره شده اند. با جستجوی یک pattern خاص از ریشه، تمام پسوندهای Text که با آن الگو شروع میشوند در زیردرخت راسی که درنهایت روی آن هستیم موجود اند. پس در پیچیدگی روی هر الگو تکرارهای آن پیدا میشوند. مقدار پیچیدگی زمانی کل هم میشود.


به دلیل خواص خوبی که درختهای پسوندی دارند از آنها برای ویرایش متن، جستوجوی متن آزاد، زیستشناسی محاسباتی و دیگر حوزهها استفاده میشود. کاربردهای اولیه عبارتند از:
- جستوجوی رشته
- پیدا کردن بلندترین زیررشتهی تکراری
- پیدا کردن بلندترین زیررشتهی مشترک
- پیدا کردن زیر رشتههای متمایز
- پیدا کردن بلندترین زیررشتهی پالیندروم در رشته
درختهای پسوندی اغلب در حوزهی بیوانفورماتیک استفاده میشوند، برای جستوجوی الگوها در دنبالههای دیانای یا دنبالههای پروتئینی (که میتوان آنها را به عنوان رشتههای بلندی از حروف در نظر گرفت). توانایی جستوجوی کارآمد با عدم تطابق ممکن است بزرگترین قدرت درختهای پسوندی باشد. این داده ساختارها همچنین در فشردهسازی دادهها استفاده میشوند؛ میتوان برای پیدا کردن دادههای تکراری و نیز در مرحلهی مرتبسازی تبدیل باروز-ویلر از آنها استفاده کرد. گونههایی از طرحهای فشردهسازی LZW از درختهای پسوندی استفاده میکنند (LZSS). در خوشهبندی درخت پسوندی (یک الگوریتم خوشهبندی که در برخی از موتورهای جستوجو استفاده میشود) نیز از درختهای پسوندی استفاده میشود.
پیادهسازی
اگر هر گره و یال را بتوان در فضای حافظهای از ذخیره کرد، میتوان تمام درخت را در فضای حافظهای از ذخیره نمود. جمع طول تمامی رشتههای روی همهی یالها در درخت از است، اما هر یال میتواند با دو عدد به صورت مکان و طول زیررشتهای از ذخیره شود؛ که در کل ذخیرهی همهی یالها حافظهای از اشغال میکند.



در اینجا دو روش برای ساخت درخت پسوندی را بررسی میکنیم.
- در زمان
به عنوان یک روش ساده برای حالتی که طول رشته کوتاه است میتوانیم از آن استفاده کنیم. کافی است تمام پسوندها را در یک درخت پیشوندی درج کنیم.
- در زمان ، Ukkonen's algorithm [1]
این الگوریتم ساخت درخت پسوندی را به تعداد فاز تقسیم میکند که هرکدام مراحلی دارند. در فاز ام، برای اولین بار حرف ام رشته را در نظر میگیریم و بعد از تمام شدن آن انتظار داریم تمام پسوندهای زیررشته در درخت درج شده باشند. در هر مرحله از این فاز، درج میشود. قبل از فاز ام فاز تمام شده، پس رشته را داخل درخت جستجو میکنیم. ۳ حالت امکان دارد رخ دهد که در هر حالت طبق قانون خاصی ادامه میدهیم.






- رشته کامل پیدا میشود و مسیر در یک راس برگ تمام میشود. در این حالت حرف ام به آخرین یال اضافه میشود و راس جدیدی هم نمیسازیم.
- رشته کامل پیدا میشود و مسیر وسط یک یال تمام میشود و حرف بعدی رشته روی یال برابر نیست یا مسیر روی یک راس درونی(غیر برگ) تمام میشود. اگر مسیر روی راس درونی تمام شود، یک برگ جدید ایجاد میکنیم. در حالت اول یک راس میانی و یک برگ جدید ایجاد میکنیم.
- پسوند پیدا میشود و مسیر روی یال تمام میشود در حالی که حرف بعدی آن مساوی است. در این حالت هیچ بروزرسانیای انجام نمیشود.

اگر همه فازها و مراحل را به شکل جستجوی جامع انجام دهیم چون فاز مرحلهای داریم و جستجوی درخت هم است در نهایت الگوریتم از میشود. برای کاهش آن از پیوندهای پسوندی استفاده میکنیم.

تعریف پیوند پسوندی: فرض کنید رشته در درخت وجود دارد و مسیر آن به راس ختم میشود. رشته ( حرفی دلخواه از الفبا) هم موجود است و به راس ختم میشود. به پیوندی از راس به پیوند پسوندی گفته میشود. در شکل اول این پیوندها با خطچین نشان داده شدهاند.





وقتی در حال انجام مرحله فاز هستیم، باید انتهای مسیر را بدانیم. همچنین در مرحله مسیر . قبل از انجام فاز فاز انجام شده یعنی دو رشته و در درخت هستند. همان است پس ما یک پیوند پسوندی از راس انتهایی به داریم پس به جای جستجو از ریشه میتوانیم از آن استفاده کنیم. در این حالت صرفا زمان جستجو بهتر میشود تا به برسیم.



برای اینکه پیچیدگی زمان شود حتما باید رشتههای روی یال را به صورت زیربازهای از رشته اصلی ذخیره کنیم. با ذخیره دو عدد شروع و پایان.

قوانینی که به آن اشاره شد، در یک فاز به ترتیب عمل میکنند. یعنی اولین مراحل قانون ۱ عمل میکند، بعد مدتی دومی و در آخر همیشه حالت سوم رخ خواهد داد. پس مثلا وقتی به حالت ۳ برسیم دیگر انجام آن فاز عملا تمام شده. وقتی یک برگ جدید میسازیم، همیشه برگ باقی میماند صرفا امکان دارد یال آن به پدرش طولانی شود.(در حالت ۱) همچنین برای تمام برگها یکسان میماند. پس در هر فاز قانون یک در زمان ثابت با ذخیره با لیست همگانی از های برگها قابل انجام است.

وقتی قانون دوم اجرا میشود هم، برگ جدید ایجاد میشود. و اگر یکبار در مرحله اجرا شود، در تمامی فازهای بعدی این مرحله قانون اول رخ میدهد. پس در بدترین حالت بار اجرا میشود چون برگ داریم. پس طبق خاصیتهای گفته شده مرتبه زمانی به کاهش پیدا کرد.
یک نمونه از پیادهسازی آن به زبان را در اینجا ببینید. [2]

یک انتخاب مهم هنگام پیادهسازی یک درخت پسوندی، رابطهی پدر-فرزندی بین گرهها است. استفاده از یک نوع لیست پیوندی به نام لیست خواهر و برادرها متداولترین نوع است. هر گره یک اشارهگر به فرزند اولش و یک اشارهگر به فرزند بعدی در لیست فرزندهایی که عضو آنها است، دارد. پیادهسازیهای دیگر با زمان اجرای کارآمد از جداول درهمسازی، آرایههای مرتب یا نامرتب، (آرایه پویا)، یا درختهای جستوجوی دودویی خود-متوازن استفاده میکنند.
فاکتورهای زیر در پیاده سازی مهم هستند:
- هزینهی پیدا کردن یک فرزند با یک حرف داده شده
- هزینهی درج یک فرزند
- هزینهی پیدا کردن تمام فرزندان یک گره (تقسیم شده بر تعداد فرزندان در جدول زیر)
اگر تعداد حروف الفبا باشد، هزینهها به شرح زیر است:


هزینهی درج سرشکن است، و هزینهی درهمسازی برای درهمسازی کامل داده شده است.
جستارهای وابسته
منابع
- "Suffix Trees Tutorials & Notes | Data Structures". HackerEarth. Retrieved 2020-06-05.
- "Suffix tree. Ukkonen's algorithm". Codeforces. Retrieved 2020-06-05.
مشارکتکنندگان ویکیپدیا. «Suffix Tree». در دانشنامهٔ ویکیپدیای انگلیسی، بازبینیشده در ۱۸ سپتامبر ۲۰۱۲.