شبکه عصبی پیشخور
یک شبکه عصبی پیشخور (به انگلیسی: Feedforward Neural Network) یک شبکه عصبی مصنوعی است، که در آن اتصال میان واحدهای تشکیل دهنده آن یک چرخه را تشکیل نمیدهند. در واقع این شبکه متفاوت از شبکههای عصبی بازگشتی میباشد.
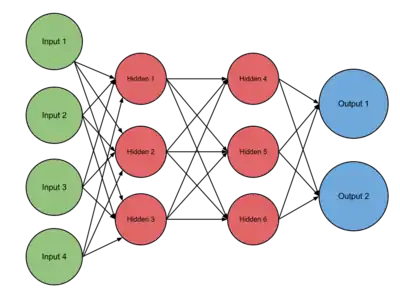
شبکه عصبی پیشخور اولین و سادهترین نوع شبکه عصبی مصنوعی میباشد. در این شبکه اطلاعات تنها از یک مسیر حرکت میکند که جهت آن رو به جلو میباشد. در واقع اطلاعات باشروع از گره (نورون)های ورودی و گذر از لایههای پنهان (درصورت وجود) به سمت گرههای خروجی میروند. همانطور که گفته شد در این شبکه حلقه یا دوری وجود ندارد.
مقدمه
در سال ۱۹۴۳ وارن مک کلاچ و والتر پیتز اولین نورون مصنوعی را طراحی کردند. خصوصیت اصلی مدل نورون طراحی شده این بود که مجموع سیگنالهای ورودی وزن دار شده را با یک مقدار آستانه مقایسه میکرد و به این ترتیب در مورد خروجی تصمیمگیری مینمود. این نورون در صورتی که مجموع وزندار شده سیگنالها، کمتر از آستانه بود، خروجی صفر و در غیر اینصورت مقدار ۱ را به عنوان خروجی تولید میکرد. آنها قصد داشتند، نشان دهند، یک نورون با چنین خصوصیاتی قادر به محاسبه هر تابع ریاضی یا منطقی میباشد. در اواخر دهه ۱۹۵۰ میلادی، فرانک روزنبلات و چندین محقق دیگر، یک کلاس از شبکههای عصبی تحت عنوان شبکههای عصبی پرسپترون معرفی کردند. نورونها در این شبکه مشابه نورونهای طراحی شده توسط مک کلاچ و پیتز بودند. روزنبلات ثابت کرد که قاعده یادگیری طراحی شده توسط او در آموزش شبکههای پرسپترون همواره به وزنهای صحیحی همگرا میشود. به این ترتیب این شبکهها در صورت وجود پاسخ، حتماً مسئله را حل میکردند. روند یادگیری ساده و خودکار بود، همچنین شبکههای پرسپترون حتی با شروع از مقادیر تصادفی وزنها و بایاسها قادر به یادگیری و حل مسئله میباشند. شایان توجه است که شبکههای پرسپترون دارای محدودیتهایی نیز میباشند. امروزه شبکههای پرسپترون دارای اهمیت ویژهای بوده و یک راهحل سریع و مطمئن برای حل مسائل طبقهبندی شده میباشند.
قواعد یادگیری
در مباحث مربوط به شبکههای عصبی، قواعد یادگیری، رویهای برای اصلاح وزنها و بایاسها تعریف میکنیم. قاعده یادگیری در راستای آموزش شبکه برای انجام کار خاصی مورد استفاده قرار میگیرد. قواعد یادگیری به سه بخش عمده تقسیمبندی میشوند:قاعده یادگیری با نظارت، قاعده یادگیری بی نظارت و قاعده یادگیری تقویتی. در اینجا توضیح مختصری در مورد نحوه عملکرد این قواعد میدهیم. در "'قاعده یادگیری با نظارت"' از مجموعهای از نمونههای آموزشی استفاده میکنیم که شبکه را آموزش میدهند. زوجهای مرتب زیر را در نظر بگیرید:

در هر زوج مرتب، ، ورودی شبکه و به عنوان خروجی یا هدف مورد نظر شناخته میشود. زمانی که ورودی به شبکه اعمال میشود، خروجی با هدف مقایسه میشود. سپس بر طبق قواعد یادگیری برای تنظیم وزنها و بایاسها تغییرات لازم اعمال میگردد تا خروجی شبکه به هدف مورد نظر نزدیک تر شود. قاعده یادگیری شبکههای پرسپترون از همین نوع میباشد. در "' قاعده یادگیری بی نظارت"' وزنها و بایاسها تنها در مقابل ورودی شبکه اصلاح میشوند و در واقع هیچ هدفی وجود ندارد. این الگوریتم اکثراً برای عملیات دستهبندی استفاده میشود. آنها ورودیها را با داشتن تعداد محدودی از کلاسها دستهبندی میکنند. "'قاعده یادگیری تقویتی"' بر رفتارهایی تمرکز دارد که ماشین باید برای بیشینه کردن پاداشش انجام دهد. این مسئله، با توجه به گستردگیاش، در زمینههای گوناگونی بررسی میشود. مانند: نظریه بازیها، نظریه کنترل، هوش ازدحامی، آمار و …. این نوع یادگیری در شبکههای پرسپترون و یادگیری بدون نظارت در شبکه پرسپترون کاربردی ندارند و توضیح بیشتر در مورد آنان از حوصله بحث خارج است.


یادگیری از طریق بازگشت به عقب
یادگیری ماشینی با نظارت (supervised learning) به دنبال تابعی از میان یک سری توابع هست که تابع هزینه (loss function) دادهها را بهینه سازد. به عنوان مثال در مسئله رگرسیون تابع هزینه میتواند اختلاف بین پیشبینی و مقدار واقعی خروجی به توان دو باشد، یا در مسئله طبقهبندی ضرر منفی لگاریتم احتمال خروجی باشد. مشکلی که در یادگیری شبکههای عصبی وجود دارد این است که این مسئله بهینهسازی دیگر محدب (convex) نیست.[1] ازین رو با مشکل کمینههای محلی روبرو هستیم. یکی از روشهای متداول حل مسئله بهینهسازی در شبکههای عصبی بازگشت به عقب یا همان back propagation است.[1] روش بازگشت به عقب گرادیانِ تابع هزینه را برای تمام وزنهای شبکه عصبی محاسبه میکند و بعد از روشهای گرادیان کاهشی (gradient descent) برای پیدا کردن مجموعه وزنهای بهینه استفاده میکند.[2] روشهای گرادیان کاهشی سعی میکنند به صورت متناوب در خلاف جهت گرادیان حرکت کنند و با این کار تابع هزینه را به حداقل برسانند.[2] پیدا کردن گرادیانِ لایه آخر ساده است و با استفاده از مشتق جزئی بدست میآید. گرادیانِ لایههای میانی اما به صورت مستقیم بدست نمیآید و باید از روشهایی مانند قاعده زنجیری در مشتقگیری استفاده کرد.[2] روش بازگشت به عقب از قاعده زنجیری برای محاسبه گرادیانها استفاده میکند و همانطور که در پایین خواهیم دید، این روش به صورت متناوب گرادیانها را از بالاترین لایه شروع کرده آنها را در لایههای پایینتر «پخش» میکند.
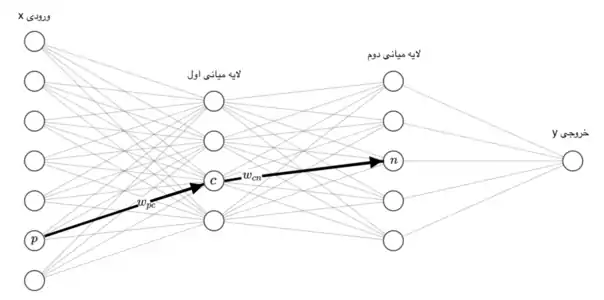
برای سلول عصبی ورودیی که از سلول عصبی به این سلول وارد میشود را با نشان میدهیم. وزن این ورودی است و مجموع ضرب ورودیها با وزنهایشان را با نمایش میدهیم، به این معنی که . حال باید بر روی تابعی غیر خطی اعمال کنیم این تابع را مینامیم و خروجی آن را با نمایش میدهیم یعنی . به همین شکل خروجیی که از سلول عصبی خارج شده و به سلول وارد میشود را با نمایش میدهیم و وزن آن را مینامیم. حال تمام وزنهای این شبکه عصبی را در مجموعهای به اسم میگنجانیم، هدف یادگیری این وزنهاست.[3] اگر ورودی ما باشد و خروجی و خروجی شبکه عصبی ما ، هدف پیدا کردن انتخاب است به قسمی که برای تمام دادهها و به هم خیلی نزدیک شوند. به عبارت دیگر هدف کوچک کردن یک تابع هزینه بر روی تمام داده هاست، اگر دادهها را با و تابع هزینه را با نشان دهیم هدف کمینه کردن تابع پایین است:[4]



















به عنوان مثال اگر مسئله رگرسیون است برای میتوانیم خطای مربعات را در نظر بگیریم و اگر مسئله دستهبندی است برای میشود منفی لگاریتم بازنمایی را استفاده کرد.
برای بدست آوردن کمینه باید از روش گرادیان کاهشی استفاده کرد، به این معنی که گرادیان تابع را حساب کرده، کمی در خلاف جهت آن حرکت کرده و این کار را آنقدر ادامه داد تا تابع هزینه خیلی کوچک شود. روش بازگشت به عقب در واقع روشی برای پیدا کردن گرادیان تابع است.

حال فرض کنیم میخواهیم گرادیان تابع را نسبت به وزن بدست بیاوریم. برای این کار نیاز به قاعده زنجیری در مشتقگیری داریم. قاعده زنجیری به این شکل کار میکند: اگر تابعی داشته باشیم به اسم که وابسته به سه ورودی ، و باشد و هرکدام از این سه ورودی به نوبه خود وابسته به باشند، مشتق به به این شکل محاسبه میشود:






با استفاده از این قاعده زنجیری روش بازگشت به عقب را به این شکل دنبال میکنیم:



همانطور که در خط پیشین دیدیم برای بدست آوردن گرادیان نسبت به به دو مقدار نیاز داریم ورودی به سلول عصبی از سلول عصبی که همان است و راحت بدست میآید و که از روش بازگشتی بدست میآید و بستگی به هایی لایه بعد دارد که سلول به آنها وصل است، بهطور دقیقتر .




روش بازگشتی برای بدست آوردن ها به این شکل کار میکند که ابتدا را برای سلولهای لایه خروجی حساب میکنیم، و بعد لایهها را به نوبت پایین آئیم و برای هر سلول آن را با ترکیت های لایههای بالایی آن طبق فرمول حساب میکنیم. محاسبه کردن برای لایه خروجی آسان است و مستقیماً با مشتق گرفتن از بدست میآید.[5]

پرسپترون تک لایه
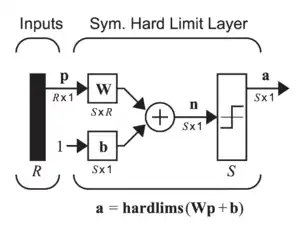
پرسپترون تک لایه سادهترین نوع شبکه عصبی است، که از یک لایه از نورونهای خروجی تشکیل شدهاست. ورودیهای این شبکه به وسیله یک آرایه از وزنها به صورت مستقیم به خروجیها نسبت داده میشوند. در نتیجه این شبکه لایه پنهانی ندارد. این شبکه را میتوان سادهترین شبکه عصبی پیشخور دانست. در هر نورون مجموع ضرب هر وزن در ورودی با اندیس برابر خود محاسبه میشود. اگر مقدار مجموع محاسبه شده در بالا برای هر نورون بالاتر از یک مقدار آستانه باشد (بهطور معمول ۰)، نورون فعال شده و مقدار فعال (بهطور معمول ۱) را میپذیرد، در غیر این صورت مقدار غیرفعال (بهطور معمول -۱) را میپذیرد. به نورونهای با تابع فعال سازی از نوع بالا را نورونهای مصنوعی یا واحدهای آستانه خطی میگوییم. اصطلاح پرسپترون اغلب اشاره به شبکههای متشکل از تنها یکی از این واحدها میکند.[6]
یک پرسپترون را میتوان با استفاده از هر مقداری برای حالات فعال و غیرفعال، تا زمانی که مقدار آستانه بین دو مقدار قرار دارد، ساخت. اکثر پرسپترونها خروجیهایی از ۱ یا -۱ با مقدار آستانه ۰ دارند. شبکههای دارای ساختار بالا را با سرعت بیشتری نسبت به شبکههای متشکل از نورونهای دارای مقادیر مختلف فعال و غیرفعال، میتوان آموزش داد.[7]
پرسپترونها را میتوان با یک الگوریتم یادگیری ساده که معمولاً به نام قانون دلتا آن را میشناسند، آموزش داد. این الگوریتم خطاهای میان خروجی محاسبه شده و خروجی نمونه را محاسبه کرده و از آن برای بروزرسانی مقادیر وزنها استفاده میکند. این الگوریتم نتیجه اجرای یک نمونه از گرادیان کاهشی میباشد.
پرسپترونهای تکواحد تنها قادر به یادگیری الگوهای خطی جدا از هم میباشد. در سال ۱۹۶۹ در یک مقاله-که بعداً تبدیل به کتاب شد- معروف تحت عنوان «پرسپترونها»،[8] ماروین مینسکی و سیمور پاپرت، نشان دادند که برای یک شبکه پرسپترون تکلایه یادگیری تابع بولی XOR غیرممکن است. با این وجود، میدانیم است که پرسپترونهای چند لایه قادر به تولید هر گونه تابع بولی میباشند.
اگر چه یک واحد آستانه کاملاً محدود به قدرت محاسباتی خود میباشد، اثبات شدهاست که شبکههایی از واحدهای آستانه موازی میتوانند هر تابع پیوسته از بازه فشرده اعداد حقیقی به بازه [-۱٬۱]. این نتیجه توسط پیتر آور، هارولد برگستینر و ولفگانگ ماس در مقالهای در مورد قوانین و الگوریتمهای یادگیری با عنوان بدست آمدهاست.[9]
شبکه عصبی چند لایه میتواند یک خروجی پیوسته را به جای یک تابع پلهای محاسبه کند. یک انتخاب رایج که تابع لجستیک (منطقی) نامیده میشود برابر است با:

تابع لجیستیک (منطقی) با نام تابع سیگموئید نیز شناخته میشود. با این انتخاب، شبکه تکلایه با مدل رگرسیون لجستیک یکسان میشود. این مدل به صورت گسترده در مدل آماری کاربرد دارد. ضابطه این تابع، دارای مشتق پیوسته و همچنین ضابطه مشتق آن بر حسب خود تابع بدست میآید. این ویژگی باعث شدهاست که از این تابع در متد پسانتشار استفاده شود. رابطه مشتق این تابع با خود تابع برابر است با:

(این رابطه به راحتی با استفاده از قاعده زنجیری قابل اثبات است)
جستارهای وابسته
منابع
- Ian Goodfellow and Yoshua Bengio and Aaron Courville (۲۰۱۶). Deep learning. MIT Press. صص. ۲۰۰.
- Heaton, Jeff (2017-10-29). "Ian Goodfellow, Yoshua Bengio, and Aaron Courville: Deep learning". Genetic Programming and Evolvable Machines. 19 (1–2): 305–307. doi:10.1007/s10710-017-9314-z. ISSN 1389-2576.
- «Build with AI | DeepAI». DeepAI. بایگانیشده از اصلی در 17 اكتبر 2018. دریافتشده در 2018-10-24. تاریخ وارد شده در
|archivedate=را بررسی کنید (کمک) - A., Nielsen, Michael (2015). "Neural Networks and Deep Learning". Archived from the original on 22 اكتبر 2018. Retrieved 13 دسامبر 2019. Check date values in:
|archive-date=(help) - Russell, Stuart; results, search (2009-12-11). Artificial Intelligence: A Modern Approach (به English) (3 ed.). Boston Columbus Indianapolis New York San Francisco Upper Saddle River Amsterdam, Cape Town Dubai London Madrid Milan Munich Paris Montreal Toronto Delhi Mexico City Sao Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo: Pearson. p. 578. ISBN 9780136042594.
- Kasabov, N. K (1998). Foundations of Neural Networks, Fuzzy Systems, and Knowledge Engineering. MIT Press. ISBN 0-262-11212-4.
- T.Hagan, Martin; B.Demuth, Howard; Beale, Mark (1996). Neural Networks Design. PWS Publishing Co. Boston. ISBN 0-534-94332-2.
- L.Minsky, Marvin; Papert, Seymour (1988). Perceptrons: An Introduction to Computational Geometry. The MIT Press. ISBN 0-262-63111-3.
- Auer, Peter; Harald Burgsteiner; Wolfgang Maass (2008). "A learning rule for very simple universal approximators consisting of a single layer of perceptrons" (PDF). Neural Networks. doi:10.1016/j.neunet.2007.12.036. Archived from the original (PDF) on 6 July 2011. Retrieved 27 April 2017.
پیوند به بیرون
- الگوریتمی ترکیبی برای آموزش شبکههای عصبی مصنوعی
- انجمن آمریکایی هوش مصنوعی
- هوش مصنوعی - MIT
- کتابخانه هوش مصنوعی
| ||
| علوم پایه |
|  |
| علوم اعصاب بالینی |
| |
| علوم اعصاب شناختی |
| |
| گرایشهای بینرشتهای |
| |
| مفاهیم |
| |
| ||
Note: This template roughly follows the 2012 ACM Computing Classification System. | |
| سختافزار | |
| سازمان سامانههای رایانه |
|
| شبکه رایانهای | |
| سازمان نرمافزار | |
| نظریه زبانهای برنامهنویسی و ابزار توسعه نرمافزار | |
| توسعه نرمافزار | |
| نظریه محاسبات | |
| الگوریتمها | |
| ریاضیات رایانه | |
| سامانه اطلاعاتی | |
| امنیت رایانه | |
| تعامل انسان و رایانه | |
| همروندی | |
| هوش مصنوعی | |
| یادگیری ماشین | |
| گرافیک رایانهای | |
| رایانش کاربردی | |
توجه: بنا بر سامانه ردهبندی رایانش ایسیام علم رایانه همچنین میتواند به موضوعها یا زمینههای گوناگون تقسیم شود.
| |