بوتاسترپینگ (آمار)
در آمار، بوت استرپینگ (به انگلیسی: Bootstrapping) یک روش محاسباتی-آماری-کامپیوتری است برای تعیین میزان دقت برآوردگرهای حاصل دادهٔ نمونه (Efron وTibshirani ۱۹۹۴). در این تکنیک تنها با یک روش خیلی ساده میتوان تقریباً هر آمارهای از توزیع دادههای نمونه را تخمین زد. بهطور عمومی این روش از روشهای بازنمونهگیری به حساب میآید.
بوت استرپینگ در واقع تخمین ویژگیهای (مثل واریانس) یک برآوردگر است با استفاده از اندازهگیری همین ویژگیها در یک توزیع تقریبی از کل دادههای نمونه. یک انتخاب استاندارد برای توزیع تقریبی، توزیع تجربی دادههای مشاهده شدهاست. در حالتی که بتوان فرض کرد مجموعهای از مشاهدهها از جمعیتی مستقل و بهطور مساوی توزیع شده میباشد، بوت استرپینگ میتواند با ساخت تعدای بازنمونه پیادهسازی شود، که هرکدام از این بازنمونهها، در واقع نمونههایی تصادفی با جایگذاری از مجموعه دادههای اصلی هستند.
همچنین از بوت استرپینگ میتوان در ساخت آزمون فرض آماری استفاده کرد. از این روش معمولاً به عنوان جایگزینی برای روشهای استنباطی بر پایه فرضهای پارامتری هنگامی که در مورد این فرضها شک داشته باشیم استفاده میشود. همچنین در استنباط پارامتری زمانی که محاسبهٔ خطای استاندار فرمول محاسباتی پیچیده شود از بوت استرپینگ استفاده میکنیم.
فواید
یک فایده بزرگ بوت استرپینگ سادگی آن است. این روش برای تخمین خطای استاندارد و بازهٔ اطمینان برای تخمین زنندههای پیچیدهٔ پارامترهای توزیع، مثل نقطههای صدکی (percentile points)، نسبتها، نسبت بختها (odds ratio)و ضرایب همبستگی سر راست است. بهعلاوه روش مناسبی برای کنترل و بررسی پایداری نتایج است.
مضرات
به دلیل اینکه بوت استرپینگ تحت برخی شرایط بهطور مجانبی ثابت است، تضمین نمونه-متناهی عمومی را فراهم نمیکند. بعلاوه، گرایش به این دارد که خیلی خوشبینانه عمل کند. ظاهر سادهٔ این روش ممکن است پیش فرضهای مهم برای آنالیز بوت استرپ (مثل فرض مستقل بودن نمونهها) را پنهان کند در حالی که در روشهای دیگر این پیش فرضها به صورت رسم بیان میشوند.
توصیف غیررسمی
بوت استرپینگ این امکان را برای یک نفر فراهم میسازد که تعداد زیادی نسخهٔ جایگزین از یک آماره را که بهطور معمول از یک نمونه محاسبه میشود جمعآوری کند. به عنوان مثال، فرض کنید که ما علاقهمند به جمعآوری اطلاعات در مورد قد افراد در جهان هستیم. به دلیل اینکه نمیتوانیم کل جمعیت را اندازهگیری کنیم، تنها از یک قسمت کوچک نمونه برداری میکنیم. از این نمونه فقط یک آماره قابل محاسبهاست، مثلاً یک میانگین یا یک انحراف معیار. در نتیجه نمیتوانیم متوجه شویم که آمارهها چه قدر و در چه بازهای تغییر میکنند. اما هنگامی که از بوت استرپ استفاده کنیم ما به صورت تصادفی یک نمونهٔ n تایی از N تا دادهٔ نمونه برمیداریم، بهطوریکه هر نفر حد اکثر t بار میتواند انتخاب شود. با چندین بار انجام این کار در واقع تعداد زیادی مجموعهٔ داده میسازیم که برای هرکدام میتوانیم یک آماره حساب کنیم؛ بنابراین به این روش یک تخمین از توزیع آماره به دست میآید. نکتهٔ مهم در این روش ساختن نسخه جایگزین از دادههایی است که ممکن است ما دیده باشیم.
موارد کاربر روش بوت استرپینگ
آدر (Adèr) و همکارانش (در سال ۲۰۰۸) روش بوت استرپ را برای بهکارگیری در موارد زیر توصیه کردند:
- وقتی که توزیع یک آمارهٔ مورد نظر ناشناخته یا پیچیدهاست.
- وقتی که اندازهٔ نمونه برای یک استنباط آماری سرراست ناکافی است.
- وقتی که محاسبات توانی لازم است انجام شود، اما نمونهٔ پایلوت کوچکی در اختیار داریم.
چه تعداد نمونه بوت استرپ کافی است؟
تعداد نمونههای توصیه شده برای این روش با افزایش توان محاسباتی کامپیوترها به تدریج افزایش یافتهاست. اگر نتایج واقعاً مهم اند باید تا جایی که توان محاسباتی کامپیوتر و محدودیت زمان اجازه میدهد تعداد نمونهها را زیاد کرد. افزایش تعداد نمونهها باعث افزایش اطلاعات در دادههای اصلی نمیشود بلکه فقط اثر خطای نمونه برداری تصادفی را کاهش میدهد.
انواع طرحهای بوت استرپ
در مسائل یک متغیری، معمولاً قابل قبول است که بازنمونهگیری از مشاهدهها با جایگذاری باشد. در نمونههای کوچک ممکن است یک روش بوت استرپ پارامتری ترجیح داده شود. برای مسائل دیگر یک بوت استرپ نرم احتمالاً ترجیح داده خواهد شد.
برای مسائل رگرسیون جایگزینهای مختلفی موجودند.
بازنمونهگیری
بوت استرپ بهطور کلی برای تقریب توزیع آمارهها مفید است، بدون استفاده از روشهای معمول تئوری مثل تستهای آماری z-statistic, t-statistic. از بوت استرپ معمولاً وقتی استفاده میشود که هیچ روش معمول و تحلیلی ای برای کمک به تخمین توزیع آمارههای مورد نظر وجود ندارد. حداقل دو روش برای این نوع نمونهگیری وجود دارد:
- الگوریتم مونت کارلو که برای استفاده در اینجا بسیار ساده نیز هست. ابتدا با جایگذاری از دادهها بازنمونهگیری میکنیم، اندازهٔ بازنمونه باید برابر اندازهٔ مجموعه دادهٔ اصلی باشد. سپس آمارهٔ مورد نظر با استفاده از بازنمونه به دست آمده از مرحلهٔ اول محاسبه میشود و اینکار چندین بار تکرار میشود تا جواب دقیقتری به دست آید.
- روش دقیق نیز شبیه مونت کارلو است با این تفائت که در این روش تمام بازنمونههای ممکن از مجموعهٔ دادهها محاسبه میشوند. تعداد بازنمونهها برابر میشود با که در آن n اندازه مجموعه دادههای اولیهاست.

بوت استرپ نرم
در این حالت تعداد کمی از نویزهای تصادفی با مرکز صفر (معمولاً دارای توزیع نرمال) به هر بازنمونه اضافه میشوند. این معادل نمونه برداری از یک تخمین kernel density از دادهها است.
بوت استرپ پارامتری
در این حالت یک مدل پارامتری به دادهها برازش میشود، معمولاً با استفاده از درستنمایی ماکزیمم، نمونههای اعداد تصادفی از این مدل برازش شده بیرون کشیده میشوند. معمولاً نمونههای بیرون کشیده شده اندازهای برابر با اندازه دادهها اصلی دارند. سپس کمیت یا تخمین آمارهٔ مورد نظر از این دادهها بدست میآید؛ و همانند دیگر روشهای بوت استرپ این کار چندین بار تکرار میشود. استفاده از بوت استرپ در این گونه موارد منجر به روشهایی میشود که متفاوت اند با روشهای استنباط آماری پایه برای همین مدل.
بازنمونهگیری باقیماندهها
روش دیگر بوت استرپینگ در مسائل رگرسیون بازنمونهگیری از باقیماندهها است. این روش به شکل زیر است:
- مدل را برازش کن و مقادیر و باقیماندهها .


را بازیابی کن.
- به ازای هر جفت، (xi, yi), که در آن xi متغیر توضیحی است، یک بازنمونه تصادفی باقیمانده اضافه کن،، به جواب متغیر yi. به بیان دیگر متغیرهای ساختگی جواب را که در آن j متغیر تصادفی انتخاب شده از لیست (۱، …, n) است به ازای هر i.
- مدل را مجدداً برازش کن با استفاده از متغیرهای ساختگی y*i و بازیابی کمیتهای مورد نظر
- مراحل ۲و ۳ را به تعدادی که از نظر آماری معنی دار باشد تکرار کنید.


بوت استرپ پروسه گوسی رگرسیون
وقتی مه دادهها یه صورت موقت با هم همبستگی دارند، بوت استرپ مستقیم همبستگیهای ذاتی را از بین میبرد. این متد از رگرسیون گوسی استفاده میکند تا یک مدل احتمالاتی را برازش کند. پروسههای گوسی متدهایی از بایزین هستند اما در اینجا استفاده میشوند تا یک روش پارامتریک بوت استرپ بسازند، که به سادگی به دادههای مستقل از زمان اجازهٔ میدهد به حساب آورده شوند.
بوت استرپ ریسکی (wild)
هر باقیمانده به صورت تصادفی در یک متغیر تصادفی با میانگین صفر و واریانس ۱ ضرب میشود. در این متد فرض بر این است که توزیع درست باقیمانده متقارن است و میتوانند فوایدی برای نمونهگیری ساده روی نمونههای کوچک داشته باشد.[1]
بوت استرپ بلاک متحرک
در این روش n-b+۱ بلاک دارای اشتراک و هرکدام به طول b به صورت روبه رو ساخته میشوند: مشاهدههای ۱ تا b میشوند بلاک ۱، مشاهدههای ۲ تا b+۱ میشوند بلاک۲ و به همین ترتیب. سپس از این بلاکها n/b باک به صورت تصادفی همراه با جایگذاری انتخاب میشوند. سپس مرتب کردن این n/b بلاک به همان ترتیبی که برداشته شدهاند مشاهدههای بوت استرپ را میدهد. این نوع روش با دادههای وابسته نیز کار میکند اگرچه مشاهدهها دیگر با ساختن، ایستا نخواهند بود. اما نشان داده شدهاست که متغیر بودن طول بلاک از این مشکل جلوگیری میکند.[2]
انتخاب آماره- گردان
در مواقعی که لازم است اطلاعات زیادی از منبع داده استخراج شود، اینکه چه تخمینی یا کدام آمارهای مورد نظر بوت استرپینگ است باید مورد توجه قرار گیرد. فرض کنید استنباط میانگین تعدادی مشاهده مورد نیاز است. در این صورت دو امکان موجود است:
- تولید نمونههای بوت استرپ از میانگین نمونهای برای ساخت فاصلهٔ اطمینانی برای میانگین
- تولید نمونههای بوت استرپ از آمارهٔ جدید (میانگین تقسیم بر انحراف معیار نمونه)، ساخت یک فاصلهٔ اطمینان برای این، سپس فاصلهٔ اطمینان نهایی برای میانگین از ضرب کردن نقاط انتهایی از فاصلهٔ اطمینان اولیه در انحراف معیار نمونهای از نمونهٔ اصلی به دست میآید.
تایج متفاوت خواهند بود و نتایج شبیهسازی نشان میدهند که روش دوم بهتر است. این روش به نوعی میتواند از روش پارامتریک استاندارد برای توزیعهای نرمال منتج شود البته کمی عمومی تر. ایده این است که از یک کمیت محوری(pivotal quantity) استفاده شود، یا اینکه آمارهای که تقریباً محوری باشد پیدا شود. همچنین بد نیست که نگاهی بهAncillary statistic هم انداخته شود.
نتیجهگیری فاصلههای اطمینان از توزیع بوت استرپ
راههای زیادی برای استفاده از توزیع بوت استرپ در محاسبه فاصلهٔ اطمینان برای آمارههای شبیهسازی شده وجود دارند و هیچ متدی وجود ندارد که برای تمام مسائل بهترین جواب را بدهد. انتخاب بین سادگی و عمومیت و هدف متدهای تنظیم شده مختلف است که میکوشند برای پوشش بیشتر.
تأثیر اریبی و فقدان تقارن روی فاصلههای اطمینان بوت استرپ
- اریبی: وقتی که میانگین توزیع بوت استرپ را با آمارهٔ متناظر از توزیع اصلی مقایسه میکنیم، در واقع در حال بررسی کردن اریبی هستیم. تا زمانی که توزیع بوت استرپ اریب نباشد و شکلش متقارن باشد درصد فاصله اطمینان راه خوبی برای تخمین زدن است. اریبی در توزیع بوت استرپ منجر به اریبی در تخمین فاصله اطمینان میشود.
- فقدان تقارن در توزیع بوت استرپ موجب به وجود آمدن مسئلهٔ دیگری نیز میشود و آن این است که چگونه باید عدم تقارن توزیع در فاصله اطمینان بازتاب داده شود؟
متدهایی برای فاصله اطمینانهای بوت استرپ
این متدها شامل متدهای زیر میباشند:
- بوت استرپ بر حسب درصد
- بوت استرپ پایهای
- بوت استرپ استیودنت شده
- بوت استرپ اریب-درست شده
- بوت استرپ تسریع شده
مثالهایی از کاربردها ی بوت استرپ
کاربردهایی مربوط به تست
بوت استرپینگ یکی از مشهورترین متدهای آزمایش meidation است.[3] زیرا نیاز به فرض نرمال بودن ندارد و بهعلاوه از آن میتوان در مواردی که اندازهٔ نمونه کوچک است استفاده کرد (N <20)
بوت استرپ نرم شده
بوت استرپینگ روشی است که معمولاً برای تقریب فاصله اطمینانها برای میانه استفاده میشود. اگرچه میانه یک آماره گسستهاست، و این حقیقت خودش را در توزیع بوت استرپ نشان میدهد.
برای هموار کردن گسستگی میانه، ما میتوانیم مقدار کمی از N(۰، σ۲) نویز تصادفی را در هر نمونه بوت استرپ وارد کنیم. برای نمونهای با اندازهٔ n انتخاب میکنیم . هیستوگرامهای توزیع بوت استرپ و توزیع هموار شدهٔ بوت استرپ در زیر مشخصاند. توزیع بوت استرپ بسیار دندانه دار است زیرا میانه تنها مقادیر کمی را میتواند بپذیرد. اما توزیع بوت اترپ نرم شده بر این مشکل غلبه میکند.

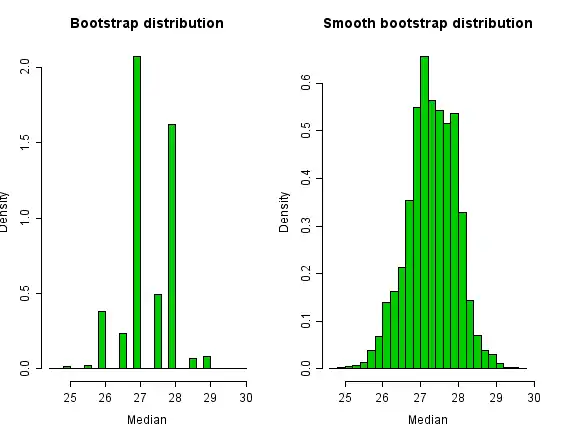
اگرچه توزیع بوت استرپ میانه زشت و به صورت شهودی اشتباه به نظر میرسد، فاصلههای اطمینانی که به دست میدهد در این مثال بد نیستند.
رابطه با دیگر راههای استنباط
رابطه با دیگر روشهای بازنمونهگیری
بوت استرپ متمایز شدهاست از:
- پروسهٔ جک نایف (jackknife)، استفاده شده برای تخمین اریبی آمارههای نمونه و برای تخمین واریانس.
- وارسی اعتبار (cross-validation)، که در آن پارامترها (مثل وزنهای رگرسیون) در یک زیرنمونه تخمین زده میشوند و به زیرنمونهها تسری داده میشوند.
برای اطلاعات بیشتر به Resampling مراجعه شود.
یو-آمارهها (U-Statistics)
در مواردی که یک آمارهٔ مشخص تنها با استفاده از عددی کوچک میتواند طراحی شود تا یک مشخصهٔ مورد نیاز را اندازه بگیرد، r، از آبتمهای داده، یک آمارهٔ متناظر بر اساس تمام نمونه میتواند فرمول بندی شود. اگر یک r-نمونه از اماره داده شده باشد، میتوان یک n-نمونه از آماره را با روشی شبیه بوت استرپینگ ساخت (با گرفتن میانگین از آماره روی کل زیر نمونهها با اندازهٔ r). این پروسه به عنوان پروسهای با ویژگیهای خوب شناخته میشود و نتیجه یک U-statistic است. برای r=۱ و r=۲، میانگین و واریانس نمونه از این نوعاند.
مبدأ این اصطلاح
استفاده از این نام در آمار توسط Bradley Efron در "Bootstrap methods: another look at the jackknife," Annals of Statistics, 7, (1979) ۱–۲۶. مراجعه شود به Notes for Earliest Known Uses of Some of the Words of Mathematics: Bootstrap (John Aldrich) و Earliest Known Uses of Some of the Words of Mathematics (B) (Jeff Miller) for details.
منابع
- Wu, C.F.J. (1986). Jackknife, bootstrap and other resampling methods in regression analysis (with discussions). Annals of Statistics, 14, 1261-1350
- Politis, D.N. and Romano, J.P. (1994). The stationary bootstrap. Journal of American Statistical Association, 89, 1303-1313.
- Preacher, K. J. , & Hayes, A. F. (2004). SPSS and SAS procedures for estimating indirect effects in simple mediation models. Behavior Research Methods, Instruments, and Computers, 36, 717–731 Macros for SAS and SPSS بایگانیشده در ۱۸ مه ۲۰۱۲ توسط Wayback Machine
- مشارکتکنندگان ویکیپدیا. «Bootstrapping_(statistics)». در دانشنامهٔ ویکیپدیای انگلیسی، بازبینیشده در ۲۵ می۲۰۱۱.