آزمون فرض آماری
آزمون فرض آماری[1] (به انگلیسی: Statistical hypothesis testing) در علم آمار روشی است برای بررسی ادعاها یا فرضها دربارهٔ پارامترهای توزیع در جوامع آماری. در این روش فرض صفر (به انگلیسی: Null-hypothesis) یا فرض اولیه، مورد بررسی ست که متناسب با موضوع مطالعه، فرض ای به عنوان فرض بدیل یا فرض مقابل (به انگلیسی: Alternative-hypothesis) انتخاب میشود تا درستی هر کدام نسبت به هم مورد آزمون قرار گیرد.[2]
رویه کلی آزمون فرض
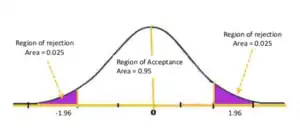
آزمون یک فرض آماری عبارت از به کار گرفتن مجموعه قواعد صریحی برای آن است که تصمیم بگیریم که آیا فرض صفر را بپذیریم یا آن را به نفع فرض مقابل رد کنیم؛ مثلاً فرض کنید که آماردانی میخواهد فرض صفر را در برابر فرض مقابل آزمون کند. برای انجام یک انتخاب، وی به تولید دادههای نمونه ای از طریق ترتیب دادن یک آزمایش و سپس محاسبه مقدار یک آماره آزمون دست میزند که این آماره به او خواهد گفت که به ازای هر برآمد ممکن فضای نمونه ای چه اقدامی بکند؛ بنابراین، روش آزمون، مقادیر ممکن آماره آزمون را به دو مجموعه افراز میکند؛ یک ناحیه قبول برای و یک ناحیه رد برای .



- : فرض صفر
- : فرض مقابل

به ناحیه رد برای ناحیه بحرانی آزمون، و به احتمال به دست آوردن مقداری برای اماره آزمون در داخل این ناحیه بحرانی، وقتی که درست باشد، اندازه ناحیه بحرانی اطلاق میشود. بدین ترتیب، اندازه یک ناحیه بحرانی صرفاً احتمال مرتکب شدن یک خطای نوع I است. این احتمال، سطح معنی دار بودن یک آزمون هم نامیده میشود.[3]

انواع خطا
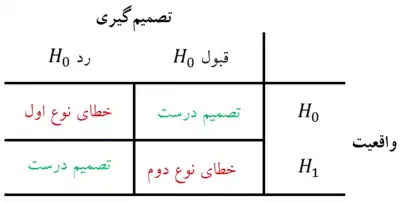
روشی که هماکنون توصیف شد ممکن است به دو نوع خطا منجر شود:
خطای نوع I
رد فرض صفر را وقتی که درست باشد خطای نوع I مینامند؛ احتمال ارتکاب خطای نوع I را با نشان میدهند.
خطای نوع II
قبول فرض صفر را وقتی که نادرست باشد، خطای نوع II مینامند؛ احتمال ارتکاب خطای نوع II را با نشان میدهند.[4]

کاربردها
اگر مهندسی بخواهد بر مبنای دادههای نمونه ای نظر دهد که آیا طول عمر متوسط نوع خاصی لاستیک چرخ ماشین حداقل ۲۲۰۰۰ مایل است یا نه، اگر یک کارشناس کشاورزی بخواهد بر مبنای آزمایشهایی نظر دهد که آیا نوع خاصی کود کشاورزی محصول لوبیای بیشتری نسبت به کود دیگر تولید میکند یا نه، و اگر یک سازنده محصولات دارویی بخواهد بر مبنای نمونههایی نظر دهد که آیا ۹۰ درصد کلیه بیمارانی که داروی جدیدی را مصرف میکنند از بیماری خاصی بهبود خواهند یافت یا نه، همه این مسائل را میتوان به زبان آزمون فرضهای آماری برگرداند.
در مورد اول میتوانیم بگوییم که این مهندس باید این فرض را آزمون کند که پارامتر یک جامعه نمایی، حداقل ۲۲۰۰۰ است؛ در مورد دوم، میتوانیم بگوییم که کارشناس کشاورزی باید نظر دهد که آیا که در آن و میانگینهای دو جامعه نرمال هستند؛ و در مورد سوم میتوانیم بگوییم که سازنده باید نظر دهد که آیا ، پارامتر یک جامعه دوجمله ای برابر با ۰٫۹۰ است یا نه.




مانند مثالهای بالا، اغلب آزمونهای آماری به پارامترهای توزیعها میپردازند، ولی گاهی آنها به نوع، یا ماهیت خود توزیعها نیز میپردازند. به عنوان مثال، در اولین مثال از سه مثال بالا، آن مهندس همچنین ممکن است بخواهد نظر دهد که آیا واقعاً با نمونه ای از توزیع نمایی سر و کار دارد، یا اینکه آیا دادههای او مقادیر متغیرهای تصادفی ای هستند که، مثلاً، دارای توزیع وایبول هستند.
فرض آماری
یک فرض آماری، حکم یا حدسی دربارهٔ توزیع یک یا چند متغیر تصادفی است. اگر یک فرض آماری توزیع را کاملاً مشخص کند، آن را فرض ساده و در غیر این صورت آن را فرض مرکب مینامند.
فرضهایی که به صورت یک رابطه تساوی بیان میشوند فرضهای ساده نامیده میشوند ولی ممکن است این فرضها به صورت نامساوی یا فرضهای مرکب نیز باشند.
بدین ترتیب یک فرض ساده باید نه تنها شکل تابع توزیع مبنا، بلکه مقادیر همه پارامترها را نیز مشخص کند؛ بنابراین در سومین مثال از مثالهای بالا، یعنی مثالی که با کارایی داروی جدید سر و کار دارد، فرض ساده است، البته با این فرض که اندازه نمونه و دو جمله ای بودن توزیع جامعه را بدانیم. اما، در اولین مثال از مثالهای بالا، فرض مرکب است، زیرا مقدار مشخصی به پارامتر نمیدهد.


برای اینکه بتوان ملاکهای مناسبی برای فرضهای آماری به وجود آورد، لازم است که فرضهای مقابل را هم فرمول بندی کنیم؛ مثلاً در مثالی که در آن با طول عمر لاستیک سر و کار داشتیم، میتوانیم این فرض مقابل را فرمول بندی کنیم که پارامتر در توزیع نمایی، کمتر از ۲۲۰۰۰ است؛ در مثالی که با دو نوع کود سر و کار داشتیم میتوانیم فرض مقابل را فرمول بندی کنیم؛ و در مثالی که در آن با داروی جدید سر و کار داشتیم میتوانیم این فرض مقابل را فرمول بندی کنیم که پارامتر در توزیع دو جمله ای مفروض صرفاً ۰٫۶۰ است، که همان نرخ بهبودی از بیماری بدون داروی جدید است.

مفهوم فرضهای ساده و مرکب در مورد فرضهای بالا نیز به کار میرود، و در مثال اول اینک میتوانیم بگوییم که فرض مرکب را در برابر فرض مقابل مرکب آزمون میکنیم که در آن پارامتر جامعه نمایی است. به همین نحو، در مثال دوم، فرض مرکب را در برابر فرض مقابل مرکب آزمون میکنیم، که در آن و میانگینهای دو جامعه نرمال اند، ور در مثال فرض سوم، فرض ساده را در برابر فرض ساده آزمون میکنیم که در آن پارامتر یک جامعه دو جمله ای است که برای آن معلوم است.[3]



پیدایش اصطلاح فرض صفر
آمار دانان اغلب، به عنوان فرضهای خود، ضد آنچه را که به باور آنها درست است بیان میکنند؛ مثلاً، اگر بخواهیم نشان دهیم که دانش آموزان یک مدرسه بهره هوشی بالاتری نسبت به مدرسه دیگری دارند، میتوانیم این فرض را فرمول بندی کنیم که تفاوتی در بین نیست، یعنی اینکه . با این فرض میدانیم که چه انتظاری میتوانیم داشته باشیم، اما اگر فرض را به صورت فرمول بندی میکردیم، وضعیت این گونه نمیبود؛ مگر اینکه حداقل فاصله واقعی بین و را مشخص کنیم.
به همین نحو، اگر بخواهیم نشان دهیم که نوعی سنگ معدن، محتوی درصد اورانیوم بیشتری نسبت به سنگ معدن دیگری است، میتوانیم این فرض را فرمول بندی کنیم که این درصدها یکسان است؛ و اگر بخواهیم نشان دهیم که تغییرپذیری بیشتری در کیفیت یک محصول نسبت به محصول دیگری وجود دارد، میتوانیم این فرض را فرمول بندی کنیم که هیچ تفاوتی در بین نیست، یعنی اینکه .

با توجه به فرضهای عدم تفاوت، فرضهایی نظیر اینها به پیدایش اصطلاح فرض صفر منجر شدند، گرچه امروزه این اصطلاح به هر فرض ای اطلاق میشود که میخواهیم آن را آزمون کنیم.[5]
مثال تحلیلی
با رجوع به مثال سوم در بالا، فرض کنید که سازنده داروی جدید میخواهد فرض صفر را در برابر فرض مقابل امتحان کند. آماره آزمون او ، تعداد پیروزیها (بهبودیها) ی مشاهده شده در ۲۰ امتحان است، و او فرض صفر را میپذیرد در صورتی که ؛ در غیر این صورت آن را رد خواهد کرد. حال میخواهیم و را محاسبه کنیم.


ناحیه قبول برای با مقادیر ؛ و ناحیه رد (یا ناحیه بحرانی) متناظر با مقادیر داده میشود، بنابراین طبق جدول توزیع نرمال (توزیع دو جمله ای با زیاد شدن تکرار آزمایشهای با توزیع نرمال تخمین زده میشود) داریم:



و
.

یک آزمون خوب آن است که در آن و هر دو کوچک باشند و بنابراین به ما شانس بالایی برای اتخاذ تصمیم درست بدهد. احتمال خطای نوع II () در مثال بالا نسبتاً زیاد است، اما میتوان آن را با تغییر مناسب ناحیه بحرانی کم کرد؛ مثلاً اگر ناحیه قابل قبول را در مثال بالا به کار ببریم، به طوریکه ناحیه بحرانی باشد، به آسانی میتوان تحقیق کرد که با این کار و خواهد شد؛ بنابراین، گرچه احتمال خطای نوع II کوچکتر شدهاست، احتمال خطای نوع I بزرکتر شدهاست. تنها راهی که میتوان احتمالهای هر دو نوع خطا را کم کرد افزایش دادن اندازه نمونه است، اما مادامی که ثابت گرفته شود، این رابطه متقابل بین احتمالهای خطای نوع I و نوع II از خصوصیات روشهای تصمیم آماری است. به عبارت دیگر، اگر احتمال یک نوع خطا کاهش یابد، احتمال خطای نوع دیگر افزایش مییابد.[3]




جستارهای وابسته
منابع
- «آزمون فرض» [آمار، ریاضی] همارزِ «hypothesis testing/ hypothesis test»؛ منبع: گروه واژهگزینی. جواد میرشکاری، ویراستار. دفتر ششم. فرهنگ واژههای مصوب فرهنگستان. تهران: انتشارات فرهنگستان زبان و ادب فارسی. شابک ۹۷۸-۹۶۴-۷۵۳۱-۸۵-۶ (ذیل سرواژهٔ آزمون فرض)
- سعید رضاخواه، آمار و احتمال کاربردی، انتشارات دانشگاه امیر کبیر، شابک ۹۶۴-۴۶۳-۰۹۱-۲ (کتابخانه ملی: م۷۹–۲۰۶۷۴) مقدار
|شابک=را بررسی کنید: invalid character (کمک) - فروند، جان (۱۳۷۸). آمار ریاضی. تهران: مرکز نشر دانشگاهی. صص. ۴۱۰.
- اهرابی، فریدون؛ تقوی طلب، محسن. احتمالات و تحلیل آماری. بانک مرکزی جمهوری اسلامی.
- ج. لارسن، هرولد (۱۳۸۹). نظریه احتمالات و نتیجهگیری آماری. تهران: موسسه انتشارات علمی دانشگاه صنعتی شریف.
| همگانی |
| ||||||
|---|---|---|---|---|---|---|---|
| پیشگیری پزشکی |
| ||||||
| Population health |
| ||||||
| بیولوژیکی و آمار اپیدمیولوژیک | |||||||
| Infectious and epidemic disease prevention |
| ||||||
| بهداشت مواد خوراکی و مدیریت ایمنی |
| ||||||
| Health behavioral sciences |
| ||||||
| نهادها، آموزش و پیشینه |
| ||||||
| |||||||